V současnosti existují dvě nejoblíbenější architektury procesorů. Jedná se o x86, který byl vyvinut již v 80. letech a používá se v osobních počítačích a ARM je modernější, což umožňuje, aby byly procesory menší a ekonomičtější. Používá se ve většině mobilních zařízení nebo tabletů.
Obě architektury mají svá pro a proti, stejně jako oblasti použití, ale jsou zde i společné rysy. Mnoho odborníků říká, že ARM je budoucnost, ale stále má některé nevýhody, které x86 nemá. V našem dnešním článku se podíváme na to, jak se architektura arm liší od x86. Zvažte základní rozdíly mezi ARM nebo x86 a také se pokuste určit, co je lepší.
co je architektura?
Procesor je hlavní součástí jakéhokoli výpočetního zařízení, ať už je to chytrý telefon nebo počítač. Jeho výkon určuje, jak rychle bude zařízení fungovat a jak moc může běžet na baterii. Zjednodušeně řečeno, architektura procesoru je soubor instrukcí, které lze použít při programování a jsou hardwarově implementovány pomocí určitých kombinací procesorových tranzistorů. Jsou to ty, které umožňují programům interakci s hardwarem a určují, jak budou data přenášena a čtena z paměti.
Na tento moment Existují dva typy architektur: CISC (Complex Instruction Set Computing) a RISC (Reduced Instruction Set Computing). První předpokládá, že v procesoru budou implementovány instrukce pro všechny příležitosti, druhý, RISC, klade za úkol vývojářům vytvořit procesor se sadou minimálních instrukcí nutných pro provoz. RISC instrukce jsou menší a jednodušší.

architektura x86
Architektura procesoru x86 byla vyvinuta v roce 1978 a poprvé se objevila v procesorech Intel a patří k typu CISC. Jeho název je převzat z modelu prvního procesoru s touto architekturou – Intel 8086. Postupem času, z nedostatku lepší alternativy, začali tuto architekturu podporovat i další výrobci procesorů, například AMD. Nyní je to standard pro stolní počítače, notebooky, netbooky, servery a další podobná zařízení. Občas se ale procesory x86 používají i v tabletech, to je celkem běžná praxe.
První procesor Intel 8086 měl bitovou hloubku 16 bitů, v roce 2000 pak vyšel procesor s 32bitovou architekturou a ještě později se objevila architektura 64bitová. Podrobně jsme to rozebrali v samostatném článku. Za tuto dobu se architektura hodně vyvinula, přibyly nové instrukční sady a rozšíření, která mohou výkon procesoru značně zvýšit.
x86 má několik významných nevýhod. Za prvé je to složitost týmů, jejich zmatenost, která vznikla dlouhou historií vývoje. Za druhé, takové procesory kvůli tomu spotřebovávají příliš mnoho energie a generují hodně tepla. Inženýři x86 se zpočátku vydali cestou maximálního výkonu a rychlost vyžaduje zdroje. Než se podíváme na rozdíly mezi arm x86, promluvme si o architektuře ARM.
Architektura ARM
Tato architektura byla představena o něco později pro x86 - v roce 1985. Byl vyvinut společností Acorn, známou společností v Británii, poté se tato architektura jmenovala Arcon Risk Machine a patřila k typu RISC, ale poté byla vydána její vylepšená verze Advanced RISC Machine, která je nyní známá jako ARM.
Při vývoji této architektury si inženýři dali za cíl odstranit všechny nedostatky x86 a vytvořit zcela novou a nejefektivnější architekturu. Čipy ARM získaly minimální spotřebu a nízkou cenu, ale měly špatný výkon ve srovnání s x86, takže zpočátku nezískaly velkou oblibu na osobních počítačích.
Na rozdíl od x86 se vývojáři zpočátku snažili získat minimální náklady pokud jde o zdroje, mají méně instrukcí procesoru, méně tranzistorů, ale v důsledku toho méně dalších funkcí. Ale v posledních letech se výkon procesorů ARM zlepšil. Vzhledem k tomu a nízké spotřebě energie se začaly velmi široce používat mobilní zařízení jako jsou tablety a chytré telefony.
Rozdíly mezi ARM a x86
A nyní, když jsme se podívali na historii vývoje těchto architektur a jejich zásadní rozdíly, udělejme podrobné srovnání ARM a x86 podle jejich různých charakteristik, abychom zjistili, která je lepší, a přesněji pochopili, jaký je jejich rozdíl. je.
Výroba
x86 vs výroba zbraní je jiná. Procesory x86 vyrábějí pouze dvě společnosti, Intel a AMD. Zpočátku to byla jedna společnost, ale tohle je úplně jiný příběh. Pouze tyto společnosti mají právo takové zpracovatele uvolnit, což znamená, že pouze oni budou řídit směr rozvoje infrastruktury.
ARM funguje velmi odlišně. Společnost, která vyvíjí ARM, nic nevydává. Jednoduše vydají povolení k vývoji procesorů této architektury a výrobci si již mohou dělat, co potřebují, například vydat konkrétní čipy s moduly, které potřebují.
Počet instrukcí
Toto jsou hlavní rozdíly mezi architekturami arm a x86. Procesory x86 se rychle vyvíjely jako výkonnější a produktivnější. Vývojáři přidali velký počet instrukce procesoru a zde není jen základní sada, ale spousta příkazů, od kterých by se dalo upustit. Zpočátku to bylo děláno pro snížení množství paměti obsazené programy na disku. Bylo také vyvinuto mnoho možností ochrany a virtualizace, optimalizace a mnoho dalšího. To vše vyžaduje další tranzistory a energii.
ARM je jednodušší. Instrukcí procesoru je zde mnohem méně, pouze těch, které potřebuje operační systém a které se skutečně používají. Pokud porovnáme x86, tak tam je použito pouze 30 % všech možných instrukcí. Snadněji se učí, pokud se rozhodnete psát programy ručně, a jejich implementace vyžaduje méně tranzistorů.
Spotřeba energie
Další závěr vyplývá z předchozího odstavce. Čím více tranzistorů na desce, tím větší je její plocha a spotřeba a naopak.
Procesory x86 spotřebují mnohem více energie než ARM. Spotřebu energie ale ovlivňuje i velikost samotného tranzistoru. Například procesor Intel i7 spotřebuje 47 wattů a jakýkoli procesor ARM pro smartphony spotřebuje ne více než 3 watty. Dříve se vyráběly desky s velikostí jednoho prvku 80 nm, pak to Intel zredukoval na 22 nm a letos vědci dokázali vytvořit desku s velikostí prvku 1 nanometr. To výrazně sníží spotřebu energie bez obětování výkonu.

V posledních letech se výrazně snížila spotřeba x86 procesorů, například nové procesory Intel Haswell vydrží déle na baterii. Nyní se rozdíl arm vs x86 postupně maže.
Odvod tepla
Počet tranzistorů ovlivňuje další parametr – tím je tvorba tepla. Moderní zařízení nemůže přeměnit veškerou energii na efektivní činnost, část z ní se rozptýlí jako teplo. Účinnost desek je stejná, to znamená, že čím méně tranzistorů a čím menší jejich velikost, tím méně tepla bude procesor generovat. Již není řeč o ARM nebo x86 bude generovat méně tepla.
Výkon procesoru
ARM nebyl stavěn pro maximální výkon, tam se x86 daří. To je částečně způsobeno menším počtem tranzistorů. V poslední době ale výkon ARM procesorů roste a lze je již plně využít v noteboocích nebo na serverech.
závěry
V tomto článku jsme se podívali na to, jak se ARM liší od x86. Rozdíly jsou docela vážné. V poslední době se ale hranice mezi oběma architekturami stírá. Procesory ARM jsou stále produktivnější a rychlejší a x86 díky zmenšení velikosti konstrukčního prvku desky začíná spotřebovávat méně energie a generovat méně tepla. Procesory ARM již najdete na serverech a noteboocích a procesory x86 na tabletech a chytrých telefonech.
A jaký máte názor na tyto x86 a ARM? Jaká technologie je podle vás budoucností? Pište do komentářů! Mimochodem, .
Na konci videa o vývoji architektury ARM:
Hlavní rysy architektury
SSE4 se skládá z 54 instrukcí, 47 z nich patří do SSE4.1 (jsou pouze v procesorech Penryn). Kompletní instrukční sada (SSE4.1 a SSE4.2, tj. 47 + zbývajících 7 instrukcí) je k dispozici v procesorech Nehalem. Žádná z instrukcí SSE4 nefunguje s 64bitovými registry mmx, pouze se 128bitovými xmm0-15. 32bitové procesory s SSE4 nebyly vydány.
Přibyly instrukce pro zrychlení kompenzace pohybu ve video kodecích, rychlé čtení z paměti USWC, spousta instrukcí pro zjednodušení vektorizace programů kompilátory. Kromě toho byly do SSE4.2 přidány instrukce pro zpracování řetězců 8/16 bitových znaků, výpočty CRC32, popcnt. Poprvé v SSE4 byl registr xmm0 použit jako implicitní argument pro některé instrukce.
Nové instrukce SSE4.1 zahrnují akceleraci videa, vektorová primitiva, vkládání/extrakce, násobení vektorového bodu, prolnutí, bitovou kontrolu, zaokrouhlování a čtení WC paměti.
Nové instrukce SSE4.2 zahrnují zpracování řetězců, počítání CRC32, počítání populace 1 bitů a práci s vektorovými primitivy.
SSE5
Nové rozšíření x86 instrukcí AMD s názvem SSE5. Tato zbrusu nová instrukční sada SSE, vytvořená společností AMD, bude od roku 2009 podporována nastupujícími společnostmi zabývajícími se procesory.
SSE5 přináší do klasické architektury x86 některé funkce, které byly dříve dostupné výhradně v procesorech RISC. Instrukční sada SSE5 definuje 47 nových základních instrukcí určených ke zrychlení jednovláknových výpočtů zvýšením "hustoty" zpracovávaných dat.
Existují dvě hlavní skupiny nových pokynů. První obsahuje instrukce, které shromažďují výsledky násobení. Pokyny tohoto typu mohou být užitečné pro organizaci iterativních výpočetních procesů při vykreslování obrázků nebo vytváření 3D zvukových efektů. Druhá skupina nových instrukcí zahrnuje instrukce, které pracují se dvěma registry a ukládají výsledek do třetího. Tato inovace může vývojářům umožnit obejít se bez zbytečných přenosů dat mezi registry ve výpočetních algoritmech. SSE5 také obsahuje několik nových instrukcí pro porovnávání vektorů, pro permutaci a přesun dat a pro změnu přesnosti a zaokrouhlování.
Hlavní aplikace pro SSE5 AMD vidí výpočetní úlohy, zpracování multimediálního obsahu a šifrovací nástroje. Očekává se, že ve výpočetních aplikacích využívajících maticové operace může použití SSE5 zvýšit výkon o 30 %. Multimediální úlohy, které vyžadují diskrétní kosinusovou transformaci, se mohou zrychlit o 20 %. A šifrovací algoritmy díky SSE5 mohou získat pětinásobné zvýšení rychlosti zpracování dat.
AVX
Další sada rozšíření od Intelu. Je podporováno zpracování čísel s plovoucí desetinnou čárkou zabalených do 256bitových „slov“. Pro ně je zavedena podpora stejných příkazů jako v rodině SSE. 128bitové registry SSE XMM0 - XMM15 se rozšiřují na 256bitové YMM0-YMM15
Rozšíření procesoru Intel Post 32nm – nová instrukční sada Intel, která umožňuje převádět čísla s poloviční přesností na čísla s jednoduchou a dvojnásobnou přesností, získávat skutečná náhodná čísla v hardwaru a přistupovat k registrům FS / GS.
AVX2
Další vývoj AVX. SSE integer instrukce začnou pracovat s 256bitovými AVX registry.
AES
Rozšíření příkazové sady AES - mikroprocesorová implementace šifrování AES.
3DNy!
Sada instrukcí pro streamové zpracování reálných čísel s jednoduchou přesností. Podporováno procesory AMD od K6-2. Není podporováno procesory Intel.
3DNy! jako operandy používejte registry MMX (v jednom registru jsou umístěna dvě jednoduchá čísla přesnosti), proto na rozdíl od SSE při přepínání úloh není nutné ukládat kontext 3DNow! samostatně.
64bitový režim
Superskalární znamená, že procesor může provést více než jednu operaci za cyklus hodin. Super-pipelining znamená, že procesor má více výpočetních kanálů. Pentium má dva z nich, což mu umožňuje být v ideálním případě dvakrát tak produktivní než 486 na stejných frekvencích a provádět 2 instrukce na takt najednou.
Procesor Pentium se navíc vyznačoval na tehdejší dobu zcela přepracovaným a velmi výkonným FPU, jehož výkon byl až do konce 90. let pro konkurenty nedosažitelný.
Pentium přes pohon
K jádru Pentium II byl navíc přidán MMX blok.
Celeron
První zástupce této rodiny byl založen na architektuře Pentium II, jednalo se o cartridge s plošným spojem, na kterém bylo osazeno jádro, L2 cache a cache tag. Montováno do slotu Slot 2.
Moderní Xeony jsou založeny na architektuře Core 2 / Core i7.
Procesory AMD
Am8086 / Am8088 / Am186 / Am286 / Am386 / Am486Zásadně nové procesor AMD(duben 1997), založené na jádře zakoupeném od NexGen. Tento procesor měl konstrukci páté generace, ale patřil k šesté generaci a byl umístěn jako konkurent Pentia II. Zahrnuje blok MMX a poněkud přepracovaný blok FPU. Tyto bloky však stále pracovaly o 15–20 % pomaleji než bloky s podobnou frekvencí procesory Intel. Procesor měl 64 KB L1 cache.
Celkově vzato, výkon podobný Pentiu II, kompatibilita se staršími základními deskami a dřívější uvedení na trh (AMD představilo K6 o měsíc dříve, než Intel představil P-II) a nižší cena z něj udělaly docela populární, ale výrobní problémy AMD výrazně zkazily pověst. tento procesor.
K6-2Další vývoj jádra K6. Tyto procesory mají přidanou podporu pro specializované 3DNow! . Reálný výkon se ale ukázal být výrazně nižší než u podobně taktovaných Pentií II (to bylo způsobeno tím, že nárůst výkonu s rostoucí frekvencí byl u P-II vyšší kvůli vnitřní mezipaměti) a pouze Celeron mohl konkurovat K6-2. Procesor měl 64 KB L1 cache.
K6-IIITechnologicky úspěšnější než K6-2, pokus vytvořit obdobu Pentia III. Marketingový úspěch to však nebyl. Vyznačuje se přítomností 64 KB mezipaměti první úrovně a 256 KB mezipaměti druhé úrovně v jádře, což mu umožnilo překonat Intel Celeron při stejné taktovací frekvenci a nebýt výrazně horší než rané Pentium III.
K6-III+Podobně jako K6-III s PowerNow! a více vysoká frekvence a rozšířený soubor pokynů. Původně určeno pro notebooky. Byl také instalován do stolních systémů s paticí procesoru Super 7. Používá se k upgradu stolních systémů s paticí pro procesor Socket 7 (Pouze na základních deskách, které dodávají procesoru dvě napětí, první pro I/O bloky procesoru a druhé pro jádro procesoru. Ne všichni výrobci poskytovali duální napájení u prvních modelů jejich základní desky se zásuvkou 7).
Analog K6-III + s mezipamětí druhé úrovně sníženou na 128 KB.
AthlonVelmi povedený procesor, díky kterému si AMD dokázalo získat zpět svou téměř ztracenou pozici na trhu mikroprocesorů. Mezipaměť první úrovně - 128 KB. Zpočátku byl procesor vyráběn v kazetě s mezipamětí druhé úrovně (512 KB) na desce a instalován do slotu A (který je mechanicky, ale není elektricky kompatibilní se slotem 1 Intel). Pak jsem přešel na Socket A a v jádře měl 256 KB L2 cache. Pokud jde o rychlost - přibližný analog Pentia III.
DuronOdříznutá verze Athlonu se od své mateřské liší velikostí mezipaměti druhé úrovně (pouze 64 KB, ale integrovaná do čipu a běžící na frekvenci jádra).
Celeron je konkurentem generací Pentium III / Pentium 4. Výkon je znatelně vyšší než u podobných Celeronů a v mnoha úlohách se Pentiu III vyrovná.
Athlon XPPokračující vývoj architektury Athlonu. Výkonově je to obdoba Pentia 4. Oproti běžnému Athlonu přibyla podpora instrukcí SSE.
SempronLevnější (kvůli snížené L2 cache) verze procesorů Athlon XP a Athlon 64.
První modely Sempron byly přeznačené čipy Athlon XP založené na jádrech Thoroughbred a Thorton, které měly 256 KB L2 cache a pracovaly na 166 (333 DDR) sběrnici. Později se pod značkou Sempron vyráběly (a jsou vyráběny) oříznuté verze Athlonů 64/Athlon II, které se staly konkurenty Intel Celeron. Všechny Semprony mají zkrácenou mezipaměť úrovně 2; mladší modely Socket 754 měly zablokované Cool&quiet a x86-64; Modely Socket 939 měly blokovaný dvoukanálový paměťový režim.
OpteronPrvní procesor podporující architekturu x86-64.
Athlon 64První neserverový procesor podporující architekturu x86-64.
Athlon 64X2Pokračování architektury Athlon 64, má 2 jádra.
Athlon FX
měl pověst „ten rychlý procesor pro hračky. je ve skutečnosti serverový procesor Opteron 1xx na stolních zásuvkách bez podpory registrované paměti. Vyrábí se v malých sériích. Stojí mnohem víc než jeho „masové“ protějšky.
PhenomDalší vývoj architektury Athlon 64 je k dispozici ve verzích se dvěma (Athlon 64 X2 Kuma), třemi (Phenom X3 Toliman) a čtyřmi (Phenom X4 Agena) jádry.
Phenom IIprocesory VIA
Cyrix III / VIA C3První procesor vydaný pod značkou VIA. Vydáno s různými jádry od různých vývojových týmů. Konektor Socket 370.
První vydání je založeno na jádře Joshua, které získala VIA spolu s vývojovým týmem Cyrix.
Druhé vydání je s jádrem Samuel, vyvinutým na základě nikdy nevydaného IDT WinChip -3. Vyznačoval se absencí mezipaměti druhé úrovně, a proto extrémně nízkou úrovní výkonu.
Třetí vydání je s jádrem Samuel-2, vylepšenou verzí předchozího jádra, vybavenou mezipamětí druhé úrovně. Procesor byl vyroben tenčí technologií a měl sníženou spotřebu energie. Po vydání tohoto jádra značka VIA Cyrix III konečně ustoupila VIA C3.
Čtvrté vydání je s jádrem Ezra. Existovala také varianta Ezra-T uzpůsobená pro práci se sběrnicí určenou pro procesory Intel Core Tualatin. Další vývoj ve směru úspory energie.
Páté vydání je s jádrem Nehemiah (C5P). Toto jádro konečně dostalo plnou rychlost koprocesoru, podporu pro instrukce nebo .
Procesory založené na jádře V33 neměly režim emulace 8080, ale podporovaly jej pomocí dvou dodatečné pokyny, rozšířený režim adresování.
Procesory NexGen
Nx586V březnu 1994 byl představen procesor NexGen Nx586. Byl umístěn jako konkurent Pentia, ale zpočátku neměl integrovaný koprocesor. Použití proprietární sběrnice s sebou neslo nutnost použití proprietárních čipových sad NxVL (VESA Local Bus) a NxPCI 820C500 (PCI) a nekompatibilní patice procesoru. Čipové sady byly vyvinuty společně s VLSI a Fujitsu. Nx586 byl superskalární procesor a mohl provádět dvě instrukce na takt. L1 cache byla samostatná (16 KB pro instrukce + 16 KB pro data). Řadič L2 cache byl integrován do procesoru, zatímco samotná cache byla umístěna na základní deska. Stejně jako Pentium Pro byl Nx586 uvnitř RISC procesor. Nedostatek podpory pro CPUID instrukce v raných modifikacích tohoto procesoru vedl k tomu, že byl programově definován jako rychlý 386 procesor. Souviselo to i s tím, že Windows 95 odmítal instalovat na počítače s takovými procesory. K vyřešení tohoto problému byla použita speciální utilita (IDON.COM), která reprezentovala Nx586 pro Windows jako CPU třídy 586. Nx586 byl vyroben v zařízeních IBM.
Byl vyvinut také koprocesor Nx587 FPU, který byl ve výrobě namontován na horní část matrice procesoru. Takové „sestavy“ byly označeny Nx586Pf. Při označování výkonu Nx586 bylo použito P-rating - od PR75 (70 MHz) do PR120 (111 MHz).
Další generace procesorů NexGen, která nebyla nikdy vydána, ale sloužila jako základ pro AMD K6.
SiS procesory
SiS550Rodina SiS550 SoC je založena na licencovaném jádru Rise mP6 a je dostupná na frekvencích od 166 do 266 MHz. Nejrychlejší řešení přitom spotřebují pouze 1,8 wattu. Jádro má tři celočíselná 8stupňová potrubí. Cache L1 samostatná, 8+8 KB. Vestavěný koprocesor je pipeline. SiS550 kromě standardní sady portů obsahuje 128bitové video jádro AGP 4x UMA, 5.1kanálový zvuk, podporu 2 instrukcí s názvem Code Morphing Software. To umožňuje procesoru přizpůsobit se libovolné sadě instrukcí a zlepšuje energetickou účinnost, ale výkon takového řešení je zjevně nižší než u procesorů s nativním instrukčním systémem x86. matematický koprocesor a koprocesorové varianty se měly nazývat U5D, ale nebyly nikdy vydány.
Intel získal soudní příkaz proti prodeji zelených CPU v USA s argumentem, že UMC používala mikrokód Intel ve svých procesorech bez licence.
Vyskytly se také nějaké problémy se softwarem. Například hra Doom odmítala běžet na tomto procesoru bez změny konfigurace a Windows 95 by čas od času zamrzal. Bylo to způsobeno tím, že programy našly v U5S chybějící koprocesor a pokusy o přístup k němu skončily neúspěšně.
Procesory vyráběné v SSSR a Rusku
KR1810VM86BLX IC Design/ICT procesory
BLX IC Design and Institute počítačová technologieČína vyvíjí procesory založené na MIPS s hardwarovým překladem x86 instrukcí od roku 2001. Tyto procesory vyrábí STMicroelectronics. Uvažuje se o partnerství s TSMC.
Godson (Longxin, Loongson, Dragon)
Godson je 32bitový RISC procesor založený na MIPS. Technologie - 180 nm. Představeno v roce 2002. Frekvence - 266 MHz, o rok později - verze s frekvencí 500 MHz.
Godson 2
- Godson 2 je 64bitový RISC procesor založený na MIPS III. 90nm technologie. Při stejné frekvenci překonává svého předchůdce 10krát ve výkonu. Představeno 19. dubna 2005.
- Godson-2E - 500 MHz, 750 MHz, později - 1 GHz. Technologie - 90 nm. 47 milionů tranzistorů, spotřeba energie - 5 ... 7,5 W. První Godson s hardwarovým překladem x86 příkazů a je na něj vynaloženo až 60 % výkonu procesoru. Představeno v listopadu 2006.
- Godson 2F - 1,2 GHz, dostupný od března 2007. Deklarován je nárůst výkonu oproti předchůdci o 20-30%.
- Godson 2H - plánované vydání v roce 2011. Bude vybaven integrovaným video jádrem a paměťovým řadičem a je určen pro spotřebitelské systémy.
- Godson 3 - 4 jádra, 65nm technologie. Spotřeba energie - asi 20 wattů.
- Godson 3B - 8 jader, technologie 65 nm (plánována je 28 nm), taktovací frekvence do 1 GHz. Plocha krystalu - 300 mm². Výkon v pohyblivé řádové čárce je 128 gigaflopů. Spotřeba 8jádrového Godsonu 3-40W. Překlad do kódu x86 se provádí pomocí sady 200 instrukcí a překlad spotřebuje asi 20 % výkonu procesoru. Procesor má 256bitovou vektorovou procesorovou jednotku SIMD. Procesor je určen pro použití v serverech a vestavěných systémech.
Struktura libovolné instrukce je následující:
- Předpony (každá je volitelná):
- Jednobajtová předpona změny adresy AddressSize (hodnota 67h).
- Jednobajtová předpona změny segmentu (hodnoty 26h, 2Eh, 36h, 3Eh, 64h a 65h).
- Jednobajtová předpona BranchHint označující preferovanou větev větve (hodnoty 2Eh a 3Eh).
- 2bajtová nebo 3bajtová komplexní předpona Vex (první bajt je vždy C4h pro 2bajtovou verzi nebo C5h pro 3bajtovou verzi).
- One-byte Lock prefix, aby se zabránilo modifikaci paměti jinými procesory nebo jádry (hodnota F0h).
- Jednobajtová předpona OperandsSize pro změnu velikosti operandu (hodnota 66h).
- Jednobajtový Povinný prefix pro kvalifikaci instrukce (hodnoty F2h a F3h).
- Jednobajtová předpona Repeat znamená opakování (hodnoty F2h a F3h).
- Jednobajtový strukturovaný prefix Rex je potřebný pro specifikaci 64bitových nebo rozšířených registrů (hodnoty 40h..4Fh).
- Escape prefix. Vždy se skládá z alespoň jednoho 0Fh bajtu. Po tomto byte volitelně následuje byte 38h nebo 3Ah. Navrženo pro upřesnění pokynů.
- Bajty specifické pro instrukci:
- Byte Opcode (libovolná konstantní hodnota).
- Byte Opcode2 (libovolná konstantní hodnota).
- Byte Params (má složitou strukturu).
- Byte ModRm se používá pro operandy v paměti (má složitou strukturu).
- Byte SIB se také používá pro operandy v paměti a má složitou strukturu.
- Údaje vložené do instrukce (volitelné):
- Offset nebo adresa v paměti (Displacement). Celé číslo se znaménkem o velikosti 8, 16, 32 nebo 64 bitů.
- První nebo jediný okamžitý operand (Immediate). Může být 8, 16, 32 nebo 64 bitů.
- Druhý okamžitý operand (Immediate2). Pokud je přítomen, má obvykle velikost 8 bitů.
V seznamu výše a níže jsou u technických názvů akceptovány názvy „pouze latinské, arabské číslice“ a znaménko mínus „-“ s podtržítkem „_“ a rejstřík je CamelCase (jakékoli slovo začíná velkým písmenem a pak pouze malá písmena, i když je zkratka: „ UTF-8“ → „Utf8“ – všechna slova dohromady). Předpony AddressSize, Segment, BranchHint, Lock, OperandsSize a Repeat lze vzájemně kombinovat. Zbytek prvků musí jít přesně v určeném pořadí. A můžete vidět, že bajtové hodnoty některých prefixů jsou stejné. Jejich účel a přítomnost určuje samotný pokyn. Předpony přepisu segmentu lze použít s většinou instrukcí, zatímco předpony BranchHint lze použít pouze s instrukcemi podmíněné větve. Podobná situace je s předponami Povinný a Opakovat - někde upřesňují pokyn a někde označují opakování. Prefix OperandSize spolu s povinnými prefixy se také označují jako prefixy instrukcí SIMD. Samostatně by se mělo říci o předponě Vex. Nahrazuje předpony Rex, Mandatory, Escape a OperandsSize a komprimuje je do sebe. Není povoleno s ním používat předponu Lock. Samotnou předponu zámku lze přidat, když je cílem operand v paměti.
Přehledný seznam všech režimů zájmu z hlediska kódování instrukcí:
- 16-bit ("Real Mode", reálný režim s adresováním segmentů).
- 32bitový ("Protected Mode", chráněný režim s modelem ploché paměti).
- 64bitový ("Long Mode", jako 32bitový chráněný modelem ploché paměti, ale adresy jsou již 64bitové).
V závorce anglické názvy režimů odpovídají oficiálním. Existují také syntetické režimy jako Unreal x86 Mode, ale všechny vyplývají z těchto tří (ve skutečnosti jsou to hybridy, které se liší pouze velikostí adresy, operandy atd.). Každý z nich používá "nativní" režim adresování, ale lze jej změnit na alternativní s předponou OperandsSize. V 16bitovém režimu bude povoleno 32bitové adresování, v 32bitovém režimu 16bitové a v 64bitovém režimu 32bitové adresování. Ale pokud se to udělá, pak se adresa vyplní nulami (pokud je menší) nebo se její bity vyššího řádu resetují (pokud je větší).
4.6. Vlastnosti architektury moderních x86 procesorů
4.6.1. Architektura procesoru Intel Pentium(P5/P6)
Procesory rodiny Pentium mají řadu architektonických a konstrukčních prvků oproti předchozím modelům mikroprocesorů Intel. Nejtypičtější z nich jsou:
Harvardská architektura s oddělením příkazových a datových toků zavedením samostatných bloků vnitřní mezipaměti pro ukládání příkazů a dat a také sběrnic pro jejich přenos;
Superskalární architektura, která poskytuje současné provádění několika příkazů v paralelně pracujících zařízeních;
Dynamické provádění příkazů, které implementuje změnu posloupnosti příkazů, použití rozšířeného souboru registrů (přejmenování registrů) a efektivní predikci větví;
Duální nezávislá sběrnice obsahující samostatnou sběrnici pro přístup k vyrovnávací paměti L2 (běží na frekvenci procesoru) a systémovou sběrnici pro přístup k paměti a externí zařízení(provádí se při taktovací frekvenci základní desky).
Hlavní charakteristiky rodiny procesorů Pentium jsou následující:
32bitová vnitřní struktura;
Použití systémové sběrnice s 36 adresovými bity a 64 datovými bity;
Samostatná vnitřní cache paměť první úrovně pro instrukce a data o kapacitě 16 KB;
Podpora sdílené cache paměti příkazů a dat druhé úrovně s kapacitou až 2 MB;
Provádění příkazů z potrubí;
Předpovídání směru větvení softwaru s vysokou přesností;
Zrychlené provádění operací s pohyblivou řádovou čárkou;
Prioritní kontrola při přístupu do paměti;
Podpora implementace víceprocesorových systémů;
Dostupnost interních nástrojů, které poskytují samočinné testování, ladění a sledování výkonu.
Nová mikroarchitektura Procesory Pentium (rýže. 4.6)a později je založen na metodě superskalární zpracování .
Pod superskalární implicitní více jeden potrubí pro zpracování příkazů (na rozdíl od skalární - single-pipeline architektury).
Obrázek 4.6 - Blokové schéma architektury Pentium MP
V Pentiu MP jsou příkazy distribuovány ve dvou nezávislých prováděcích kanálech (U a V). Dopravník U může provádět jakoukoli instrukci z rodiny IA-32, včetně instrukcí integer a floating point. Dopravník V navržený tak, aby vykonával jednoduché celočíselné instrukce a některé instrukce s pohyblivou řádovou čárkou. Příkazy lze posílat do každého z těchto zařízení současně, a když řídicí zařízení vydá pár příkazů v jednom cyklu, složitější příkaz vstoupí do potrubí U a méně složitý do potrubí V.
Takové párové zpracování instrukcí (párování) je však možné pouze pro omezenou podmnožinu celočíselných instrukcí. Skutečné aritmetické instrukce nelze spárovat s celočíselnými instrukcemi. Současné vydání dvou příkazů je možné pouze v případě, že neexistují žádné závislosti na registrech.
Jedním z hlavních rysů šesté generace mikroprocesorů architektury IA-32 je dynamický(spekulativní) výkon. Tento termín se vztahuje na následující sadu možností:
- předpověď hluboké větve(s pravděpodobností > 90 % je možné předpovědět 10-15 nejbližších přechodů);
- analýza toku dat(zobrazit program 20-30 kroků dopředu a určit závislost příkazů na datech nebo zdrojích);
- dopředné provádění příkazů(MP P6 může provádět příkazy v jiném pořadí, než je jejich pořadí v programu).
Vnitřní organizace MP P6 odpovídá architektuře RISC, takže blok načítání instrukce, čtení toku instrukcí IA-32 z L1 instrukční cache, dekóduje je do řady mikrooperací. Tok mikrooperací spadá do vyrovnávací paměť pro změnu pořadí (pool instrukcí). Obsahuje mikrooperace, které ještě nebyly provedeny, i mikrooperace, které již byly provedeny, ale ještě neovlivnily stav procesoru.
Pro dekódování instrukcí tři paralelní dekodér: dva pro jednoduché a jeden pro složité pokyny.
Každá instrukce IA-32 je dekódována v 1-4 mikrooperacích. Provádějí se mikrooperace pět paralelních pohonů: dva pro celočíselná aritmetika, dva pro skutečná aritmetika a blok paměťového rozhraní. Je tedy možné provést až pět mikrooperací za cyklus.
Blok výkonných zařízení je schopen vybrat pokyny z fondu v libovolném pořadí. Zároveň díky blok predikce větve provedení instrukcí po podmíněných skokech je možné. Rezervační jednotka neustále sleduje ve fondu instrukcí ty mikrooperace, které jsou připraveny k provedení (počáteční data nezávisí na výsledku jiných neprovedených instrukcí) a směruje je na volnou prováděcí jednotku příslušného typu. Jeden z celočíselných akčních členů se navíc podílí na kontrole správnosti predikce větvení. Když je detekován nesprávně předpovězený přechod, všechny mikrooperace následující po přechodu jsou z fondu odstraněny a potrubí instrukcí je naplněno instrukcemi na nové adrese.
Vzájemná závislost instrukcí na hodnotě registrů architektury IA-32 může vyžadovat čekání na uvolnění registrů. Chcete-li tento problém vyřešit, 40 univerzálních interních registrů používané v reálném počítači.
Smazat blok sleduje výsledek spekulativně provedených mikrooperací. Pokud mikrooperace již nezávisí na jiných mikrooperacích, její výsledek se přenese do stavu procesoru a odstraní se z vyrovnávací paměti pro změnu pořadí. Blok mazání potvrzuje provedení instrukcí (až tři mikrooperace na takt) v pořadí, v jakém se objevují v programu, s přihlédnutím k přerušením, výjimkám, bodům přerušení a chybám v predikci větvení.
Popsané schéma je znázorněno na Obr. 4.7.

Obrázek 4.7 - Blokové schéma mikroprocesoru Pentium Pro
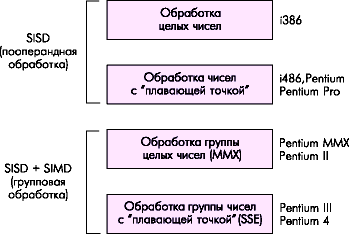
4.6.2. SIMD rozšíření MMX
Mnoho algoritmů pro práci s multimediálními daty umožňuje nejjednodušší prvky paralelizace, kdy jednu operaci lze provádět paralelně na několika číslech. Tento přístup se nazývá SIMD - jedna instrukce s více daty (jedna instrukce - hodně dat). Tato technologie byla poprvé implementována v generaci P55 (mikroprocesor Pentium MMX).
MMX (Multi-Media eXtension) je rozšíření SIMD pro streamování celočíselných dat, implementované na bázi FPU (pomocí registrů FPU).
Jediná instrukce MMX může provádět aritmetickou nebo booleovskou operaci na „balících“ celých čísel zabalených v registrech MMX. Například instrukce PADDSB přidá 8 bajtů jednoho "balíčku" k odpovídajícím 8 bajtům jiného balíčku, čímž v podstatě přidá osm párů čísel v jedné instrukci.
4.6.3. Procesory Pentium Pro, Pentium II, Pentium III
Procesor Pentium II kombinuje nejlepší vlastnosti procesorů Intel: výkon procesoru Pentium Pro a možnosti technologie MMX. Tato kombinace poskytuje procesorům Pentium II výrazné zvýšení výkonu oproti předchozím procesorům s architekturou IA-32.
Procesor obsahuje samostatné bloky interní instrukční a datové mezipaměti o velikosti 16 KB a 512 KB společné neblokující mezipaměti L2.
Zlepšení výkonu IA-32 bylo dosaženo nejen optimalizací pipeline instrukcí a přidáním prováděcích jednotek, ale také například zavedením cache paměti do jádra procesoru. V rodině IA-32 byla do procesorů Intel-486 poprvé implementována mezipaměť L1 na čipu o velikosti 8 KB. U procesorů Pentium byla velikost mezipaměti zdvojnásobena. První zástupci P6 (Pentium Pro) obsahovali i L2 cache o velikosti 256 nebo 512 KB. Takové řešení se však v té době ukázalo jako příliš drahé a nerentabilní, takže Pentium II představilo technologii Dual Independent Bus (DIB) - dvojitý nezávislý autobus. Pro přístup do mezipaměti a pro přístup k externí paměti byly použity samostatné sběrnice. Stejné architektonické řešení bylo použito u prvních modelů Pentium III. Od roku 1999 (Pentium III Coppermine) se L2 cache vrátila do útrob procesorových čipů.
Vývojem myšlenky SIMD pro reálná čísla byla technologie SSE (Streamovaná rozšíření SIMD), poprvé představen s procesory Pentium III. Blok SSE doplňuje technologii MMX o osm 128bitových registrů XMM0-XMM7 a 32bitový řídicí a stavový registr MXCSR.
Obrázek 4.9 - Vývoj procesu zpracování dat v procesorech Intel Pentium
4.6.4. Pentium 4 (P7) - mikroarchitektura Net Burst
Procesor Pentium 4 je 32bitový zástupce rodiny IA-32, patřící do nové, sedmé (podle klasifikace Intel) mikroarchitektury generace. Ze softwarového hlediska se jedná o procesor IA-32 s dalším rozšířením příkazového systému - SSE2. Pokud jde o sadu softwarově přístupných registrů, Pentium 4 opakuje procesor Pentium III. Z vnějšího, hardwarového hlediska se jedná o procesor s novým typem systémové sběrnice, ve kterém se kromě zvýšení taktovací frekvence uplatňují již známé principy dvojité (2x) a čtyřnásobné (4x) synchronizace, a je přijata řada opatření k zajištění výkonu na dříve nemyslitelných frekvencích. Mikroarchitektura procesoru zvaná Net Burst je navržena tak, aby zohledňovala vysoké frekvence jak jádra (více než 1,4 GHz), tak systémové sběrnice (400 MHz).
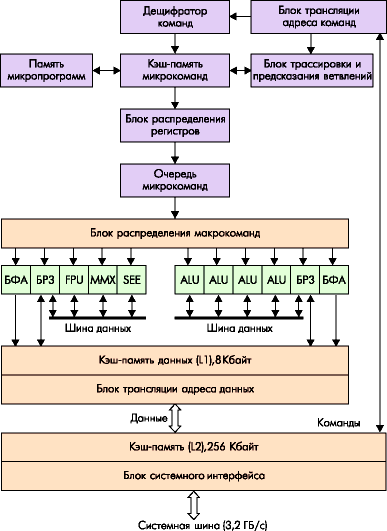
Obrázek 4.10 - Mikroarchitektura NetBurst
Procesor Pentium 4 je jednočipový. Kromě vlastního výpočetního jádra obsahuje cache paměť dvou úrovní. Sekundární mezipaměť, sdílená mezi instrukcemi a daty, má velikost 256 KB a šířku sběrnice 256 bitů (32 bajtů), jako např. nejnovější procesory Pentium III. Sekundární cache sběrnice pracuje na frekvenci jádra, která poskytuje její šířku pásma 32x1,4 = 44,8 GB/s při frekvenci 1,4 GHz. Sekundární mezipaměť má řízení ECC pro detekci a opravu chyb. Primární datová mezipaměť má stejně velkou šířku pásma (44,8 GB/s), ale její velikost byla poloviční (8 KB oproti 16 v Pentiu III). Neexistuje žádná primární instrukční cache v obvyklém smyslu, byla nahrazena trace cache. Ukládá sekvence mikrooperací, do kterých jsou dekódovány instrukce. Sem se vejde až 12K mikroinstrukcí.
Rozhraní systémové sběrnice procesoru je navrženo pouze pro konfigurace s jedním procesorem. Rozhraní je v mnohém podobné sběrnici P6, protokol je navíc zaměřen na současné provádění více transakcí. Pro zajištění vysoké propustnosti byla přijata řada opatření. V procesoru Pentium 4 je frekvence sběrnice 400 MHz s "quad pumped" (quad pumped) - takt systémové sběrnice je 100 MHz, ale rychlost přenosu adresy a dat je vyšší. Nové informace mohou být přenášeny na společných časovacích linkách každých 100 MHz. Pro přenos 2x a 4x se používá synchronizace ze zdroje dat.
MP aktuátory (ALU) pracují s dvojnásobnou frekvencí, což umožňuje provádět většinu celočíselných instrukcí v polovině cyklu. Ve srovnání s předchozími generacemi IA-32 obsahuje Pentium 4 nejdelší instrukční pipeline z 20 stupňů tzv. hyperdopravník. V souvislosti s touto funkcí mnoho odborníků poznamenává, že mikroarchitektura NetBurst bude mít maximální výkon provádění předvídatelných (lineárních a cyklických) úseků programu, typických pro aplikace, na které je Pentium 4 orientováno.frekvence 1,4 GHz a vyšší. Pro částečnou kompenzaci tohoto nedostatku byly výrazně optimalizovány mechanismy spekulativního provádění a predikce větví.
Materiál kapitoly 4 je založen na zobecnění prací.
Zřeknutí se odpovědnosti
Pravděpodobně nejpřesnější důvod vzhledu tohoto materiálu lze formulovat takto: "ani to není tak nutné, aby to bylo - je poněkud zvláštní, že to ještě nebylo." A skutečně: v komentářích k výsledkům testů neustále pracujeme s pojmy jako „kapacita mezipaměti“, „rychlost sběrnice procesoru“, „podpora rozšířených instrukčních sad“, ale na webu není jediný článek, který by obsahoval vysvětlení všech těchto termínů.. Takové opomenutí by samozřejmě mělo být odstraněno. Tento článek s podtitulem "x86 CPU FAQ" je pokusem o to. Některé jeho sekce lze samozřejmě připsat nejen procesorům architektury x86, a nejen jejich desktopovým (určeným pro instalaci do PC) variantám, ale k takovému globalismu rozhodně necílíme. Proto si prosím pamatujte, že pro účely tohoto materiálu, pokud není výslovně uvedeno jinak, slovo „procesor“ znamená „procesor x86 určený pro instalaci do stolních počítačů“. Možná se v procesu dalšího vylepšování a rozšiřování v článku objeví sekce o serverových CPU nebo dokonce procesorech jiných architektur, ale to je záležitost budoucnosti ...
Úvod
Kód a data: základní princip procesoru
Pokud se zde tedy nesnažíte prezentovat „stručně“ kurz informatiky pro střední školy, tak jediné, co bych vám rád připomněl, je, že procesor (až na vzácné výjimky) nespouští programy napsané v žádném programovacím jazyce ( jeden z nich, možná dokonce znáte), ale nějaký "strojový kód". To znamená, že příkazy pro něj jsou sekvence bajtů umístěné v paměti počítače. Někdy může mít příkaz jeden bajt, někdy to trvá několik bajtů. Na stejném místě, v hlavní paměti (RAM, RAM) jsou také data. Mohou být v samostatné oblasti, nebo mohou být „smíchané“ s kódem. Rozdíl mezi kódem a daty je v tom, že data jsou co nad čím procesor provádí některé operace. A kód jsou příkazy, které to říkají, která operace musí vyrábět. Pro zjednodušení si můžeme program a jeho data představit jako posloupnost bajtů nějaké konečné délky, umístěných spojitě (nekomplikujme) ve společném paměťovém poli. Například máme paměťové pole o délce 1 000 000 bajtů a náš program (spolu s daty) jsou bajty s čísly od 1 000 do 20 000. Ostatní bajty jsou jiné programy nebo jejich data, nebo jen volná paměť nezabraná ničím užitečným.
„Strojový kód“ jsou tedy instrukce procesoru umístěné v paměti. Data jsou tam umístěna. Aby mohl procesor provést instrukci, musí ji přečíst z paměti. Aby mohl procesor provést operaci s daty, musí je načíst z paměti a případně je po provedení určité akce zapsat zpět do paměti v aktualizované (upravené) podobě. Příkazy a data jsou identifikovány svou adresou, což je v podstatě pořadové číslo místa v paměti.
Obecné principy interakce
procesor a RAM
Možná někoho překvapí, že poměrně velká část v x86 CPU FAQ je věnována vysvětlení funkcí paměti v moderní systémy ah, na základě tohoto typu procesorů. Fakta jsou však tvrdohlavá věc: samotné procesory x86 nyní obsahují tolik bloků odpovědných konkrétně za optimalizaci jejich práce s RAM, že by bylo zcela směšné ignorovat toto úzké spojení. Můžete dokonce říci toto: protože řešení související s optimalizací práce s pamětí se stala nedílnou součástí samotných procesorů, lze samotnou paměť považovat za jakýsi „přídavek“, jehož fungování má přímý vliv na rychlost CPU. Bez pochopení zvláštností interakce procesoru s pamětí je nemožné pochopit, kvůli čemu ten či onen procesor (ten či onen systém) provádí programy pomaleji nebo rychleji.
Paměťový ovladač
Takže výše jsme již řekli, že příkazy i data vstupují do procesoru paměť s náhodným přístupem. Ve skutečnosti je vše trochu složitější. Ve většině moderních systémů x86 (tedy počítačích založených na procesorech x86) nemůže procesor jako zařízení vůbec přistupovat k paměti, protože neobsahuje odpovídající uzly. Proto se odkazuje na "střední" specializované zařízení zvané paměťový řadič a to zase na čipy RAM umístěné na paměťových modulech. Určitě jste viděli moduly - jsou to takové dlouhé úzké textolitové "laťky" (ve skutečnosti malé desky) s určitým počtem mikroobvodů, zasunuté do speciálních konektorů na základní desce. Role řadiče RAM je tedy jednoduchá: slouží jako jakýsi „most“ * mezi pamětí a zařízeními, která ji používají (mimochodem, to zahrnuje nejen procesor, ale o tom později). Paměťový řadič je zpravidla součástí čipové sady - čipové sady, která je základem základní desky. Rychlost výměny dat mezi procesorem a pamětí do značné míry závisí na rychlosti řadiče, jedná se o jednu z nejdůležitějších součástí, které ovlivňují celkový výkon počítače.
* - mimochodem, paměťový řadič je fyzicky umístěn v čipu čipové sady, tradičně nazývaném "severní můstek".
sběrnice procesoru
Každý procesor je nezbytně vybaven procesorovou sběrnicí, která se v prostředí x86 CPU běžně nazývá FSB (Front Side Bus). Tato sběrnice slouží jako komunikační kanál mezi procesorem a všemi ostatními zařízeními v počítači: pamětí, grafickou kartou, pevný disk, a tak dále. Jak však již víme z předchozí části, mezi vlastní pamětí a procesorem je paměťový řadič. Podle toho: procesor přes FSB komunikuje s paměťovým řadičem, a to zase přes speciální sběrnici (říkejme tomu bez dalšího „paměťová sběrnice“) – s moduly RAM na desce. Nicméně opakujeme: jelikož klasický x86 CPU má pouze jednu „externí“ sběrnici, slouží nejen k práci s pamětí, ale i ke komunikaci se všemi ostatními zařízeními.
Rozdíly mezi tradičními
x86 architektura CPU a K8/AMD64
Přístup AMD je revoluční v tom, že jeho procesory s architekturou AMD64 (a mikroarchitekturou, která se běžně nazývá „K8“) jsou vybaveny mnoha „externími“ sběrnicemi. V tomto případě je použita jedna nebo více sběrnic HyperTransport pro komunikaci se všemi zařízeními kromě paměti a samostatná skupina jedné nebo dvou (v případě dvoukanálového řadiče) sběrnic - výhradně pro procesor s pamětí. Výhoda integrace paměťového řadiče přímo do procesoru je zřejmá: „cesta od jádra k paměti“ se znatelně „zkrátí“, což umožňuje rychlejší práci s RAM. Tento přístup má však i nevýhody. Tedy například pokud dřívější zařízení typu pevný disk nebo grafické karty by mohly pracovat s pamětí prostřednictvím vyhrazeného nezávislého řadiče - v případě architektury AMD64 jsou nuceny pracovat s RAM prostřednictvím řadiče umístěného na procesoru. Protože CPU v této architektuře je jediným zařízením, které má přímý přístup k paměti. De facto v konfrontaci „externí kontrolor vs. integrovaná“, vyvinula se parita: na jedné straně je AMD v současnosti jediným výrobcem desktopových x86 procesorů s integrovaným paměťovým řadičem, na druhé straně se zdá, že je s tímto řešením celkem spokojená a nehodlá ho opustit . Zatřetí, Intel se také nehodlá vzdát externího ovladače a s léty prověřeným „klasickým schématem“ je vcelku spokojen.
RAM
Šířka paměťové sběrnice, N-kanálové paměťové řadiče
Ode dneška má veškerá paměť používaná v moderních x86 desktopových systémech 64bitovou širokou sběrnici. To znamená, že v jednom taktu lze na této sběrnici současně přenést násobek 8 bajtů informací (8 bajtů pro sběrnice SDR, 16 bajtů pro sběrnice DDR). Odlišuje se pouze paměť RDRAM, která byla používána v systémech založených na procesorech Intel Pentium 4 na úsvitu architektury NetBurst, ale nyní je tento směr uznáván jako slepá ulička pro počítače x86 (mimochodem stejná společnost Intel, která na jednou aktivně propagováno daný typ Paměť). Určitý zmatek přinášejí pouze dvoukanálové řadiče, které zajišťují současný provoz se dvěma samostatnými 64bitovými sběrnicemi, kvůli nimž někteří výrobci prohlašují jakousi „128bitovou“. To je samozřejmě čistá vulgárnost. Aritmetika na úrovni 1. stupně bohužel v tomto případě nefunguje: 2x64 se vůbec nerovná 128. Proč? Ano, už jen proto, že ani nejmodernější x86 CPU (viz níže sekce FAQ „64bitová rozšíření klasické architektury x86 (IA32)“) neumí pracovat se 128bitovou sběrnicí a 128bitovým adresováním. Zhruba řečeno: dvě nezávislé paralelní silnice, každá o šířce 2 metry, mohou umožnit současný průjezd dvou aut, širokých 2 metry – ale v žádném případě ne jednoho, 4 metry širokého. Stejně tak N-kanálový paměťový řadič může N-krát zvýšit rychlost práce s daty (a ještě více teoreticky než prakticky) - ale není v žádném případě schopen zvýšit bitovou hloubku těchto dat. Šířka paměťové sběrnice ve všech moderních řadičích používaných v systémech x86 je 64 bitů – bez ohledu na to, zda je tento řadič umístěn v čipsetu nebo v samotném procesoru. Některé řadiče jsou vybaveny dvěma nezávislými 64bitovými kanály, to však nijak neovlivňuje šířku paměťové sběrnice - pouze rychlost čtení a zápisu informací.
Rychlost čtení a zápisu
Rychlost čtení a zápisu informací do paměti je teoreticky omezena pouze šířkou pásma samotné paměti. Takže například dvoukanálový paměťový řadič DDR400 je teoreticky schopen poskytnout rychlost čtení a zápisu informací 8 bajtů (šířka sběrnice) * 2 (počet kanálů) * 2 (protokol DDR, který zajišťuje přenos 2 datových paketů na 1 cyklus) * 200 "000" 000 (skutečná frekvence paměťové sběrnice je 200 MHz, to znamená 200 "000" 000 cyklů za sekundu). Hodnoty získané jako výsledek praktických testů jsou zpravidla o něco nižší než teoretické: ovlivňuje „neideální“ design paměťového řadiče plus překryvy (latence) způsobené provozem cachovacího subsystému samotného procesoru (viz část o mezipaměti procesoru níže). Hlavní „fígl“ však není ani v překryvech spojených s provozem řadiče a cachovacího subsystému, ale v tom, že rychlost „lineárního“ čtení či zápisu není zdaleka jedinou charakteristikou, která ovlivňuje skutečné rychlost procesoru s RAM. Abychom pochopili, jaké komponenty tvoří skutečnou rychlost procesoru s pamětí, musíme vzít v úvahu kromě lineární rychlosti čtení nebo zápisu i takovou charakteristiku, jako je např. latence.
Latence
Latence není menší než důležitá vlastnost z hlediska rychlosti paměťového subsystému než rychlosti "čerpání dat", ale ve skutečnosti úplně jiné. Vysoká rychlost výměny dat je dobrá, když jsou jejich velikost relativně velká, ale pokud potřebujeme „trochu z různých adres“, pak se do popředí dostává latence. co to je? V obecném případě čas potřebný k zahájení čtení informací z konkrétní adresy. A skutečně: od okamžiku, kdy procesor odešle paměťovému řadiči příkaz ke čtení (zápisu), a do okamžiku, kdy je tato operace provedena, uplyne určitý čas. Navíc se to vůbec nerovná času, který trvá přenos dat. Po přijetí příkazu pro čtení nebo zápis z procesoru mu paměťový řadič „naznačí“, s jakou adresou chce pracovat. Přístup k libovolné libovolné adrese nemůže být okamžitý, trvá určitou dobu. Došlo ke zpoždění: adresa je zadána, ale paměť ještě není připravena poskytnout k ní přístup. Obecně se toto zpoždění nazývá latence. Pro různé typy pamětí je to různé. Takže například paměti DDR2 mají v průměru mnohem vyšší zpoždění než DDR (při stejné rychlosti přenosu dat). V důsledku toho, pokud jsou data v programu umístěna „chaoticky“ a v „malých částech“, rychlost jejich čtení se stává mnohem méně důležitá než rychlost přístupu k „začátku části“, protože zpoždění při přechodu na další adresa ovlivňuje výkon systému mnohem více než rychlost čtení nebo zápisu.
„Konkurence“ mezi rychlostí čtení (zápisu) a latencí je jednou z hlavních bolestí hlavy moderních systémových vývojářů: bohužel zvýšení rychlosti čtení (zápisu) téměř vždy vede ke zvýšení latence. Takže například SDR paměti (PC66, PC100, PC133) mají v průměru lepší (nižší) latenci než DDR. Na druhé straně je latence DDR2 ještě vyšší (tedy horší) než DDR.
Je třeba chápat, že „obecná“ latence paměťového subsystému závisí nejen na něm samotném, ale také na paměťovém řadiči a jeho umístění – všechny tyto faktory také ovlivňují zpoždění. Proto se AMD v procesu vývoje architektury AMD64 rozhodlo problém s vysokou latencí vyřešit „na jeden zátah“ integrací řadiče přímo do procesoru – aby „zkrátila vzdálenost“ mezi jádrem procesoru a modulů RAM co nejvíce. Nápad byl úspěšný, ale za vysokou cenu: nyní může systém založený na určitém CPU architektury AMD64 pracovat pouze s pamětí, pro kterou je jeho řadič navržen. Zřejmě proto se Intel zatím k tak zásadnímu kroku neodhodlal a raději jednal tradičními metodami: vylepšením paměťového řadiče v čipsetu a mechanismu Prefetch v procesoru (o tom viz níže).
Na závěr poznamenáváme, že pojmy „rychlost čtení/zápisu“ a „latence“ jsou v obecném případě použitelné pro jakýkoli typ paměti – včetně nejen klasických DRAM (SDR, Rambus, DDR, DDR2), ale také cache (viz níže).
Procesor: obecné informace
Pojem architektury
Architektura jako kompatibilita kódu
Určitě jste se často setkali s pojmem „x86“, případně „Intel-kompatibilní procesor“ (nebo „IBM PC kompatibilní“ – to už je ale ve vztahu k počítači). Občas se také setkáte s pojmem "Pentium-kompatibilní" (proč zrovna Pentium - pochopíte trochu později). Co se za všemi těmito názvy skutečně skrývá? V tuto chvíli je z pohledu autora nejsprávnější následující jednoduchá formulace: moderní procesor x86 je procesor schopný správně spouštět strojový kód architektury IA32 (32bitová architektura procesoru Intel). V prvním přiblížení se jedná o kód vykonávaný procesorem i80386 (populárně známým jako „386th“), ale hlavní instrukční sada IA32 byla nakonec vytvořena s vydáním procesoru Intel Pentium Pro. Co znamená „základní sada“ a co dalšího existuje? Nejprve si odpovězme na první část otázky. "Základní" v tomto případě znamená, že pouze s touto instrukční sadou lze napsat jakýkoli program, který lze napsat pro procesor x86 (nebo IA32, chcete-li).
Architektura IA32 má navíc „oficiální“ rozšíření (další instrukční sady) od vývojáře samotné architektury Intel: MMX, SSE, SSE2 a SSE3. Existují také "neoficiální" (ne Intel) rozšířené instrukční sady: EMMX, 3DNow! a Rozšířené 3DNow! - Byly vyvinuty společností AMD. Ovšem „oficiální“ a „neoficiální“ je v tomto případě relativní pojem – de facto to vše souvisí s tím, že některá rozšíření instrukční sady Intel, jako vývojář původní sady, uznává, a některá nikoli, zatímco vývojáři softwaru používají to, co je pro ně lepší.vše sedí. Pro rozšířené instrukční sady platí jedno jednoduché pravidlo: před jejich použitím musí program zkontrolovat, zda je procesor podporuje. Někdy dochází k odchylkám od tohoto pravidla (a mohou vést k nesprávnému fungování programů), ale objektivně se jedná o problém nesprávně napsaného softwaru, nikoli procesoru.
K čemu jsou další sady příkazů? Za prvé - zvýšit výkon při provádění určitých operací. Jediný příkaz z další sady obvykle provede akci, která by vyžadovala malý program složený z příkazů z hlavní sady. Opět platí pravidlo, že jedna instrukce je procesorem vykonána rychleji než sekvence, která ji nahrazuje. nicméně v 99 % případů nelze nic, co by nešlo udělat pomocí základních příkazů, udělat pomocí příkazů z doplňkové sady.
Výše zmíněná kontrola programem podpory dalších instrukčních sad procesorem by tedy měla plnit velmi jednoduchou funkci: pokud např. procesor podporuje SSE, pak budeme rychle počítat pomocí příkazů ze sady SSE. Pokud ne, budeme počítat pomaleji pomocí příkazů z hlavní sady. Dobře napsaný program by to měl dělat. Nyní však prakticky nikdo nekontroluje podporu MMX v procesoru, protože všechny CPU vydané za posledních 5 let podporují tuto sadu se zárukou. Pro orientaci zde uvádíme tabulku, která shrnuje informace o podpoře různých rozšířených instrukčních sad různými desktopovými (určenými pro desktop) procesory.
| procesor | |||||||
| Intel Pentium II | |||||||
| Intel Celeron až 533 MHz | |||||||
| Intel Pentium III | |||||||
| Intel Celeron 533-1400 MHz | |||||||
| Intel Pentium 4 | |||||||
| Intel Celeron od 1700 MHz | |||||||
| Intel Celeron D | |||||||
| Intel Pentium 4 eXtreme Edition | |||||||
| Intel Pentium eXtreme Edition | |||||||
| Intel Pentium D | |||||||
| AMD K6 | |||||||
| AMD K6-2 | |||||||
| AMD K6-III | |||||||
| AMD Athlon | |||||||
| AMD Duron až 900 MHz | |||||||
| AMD Athlon XP | |||||||
| AMD Duron od 1000 MHz | |||||||
| AMD Athlon 64 / Athlon FX | |||||||
| AMD Sempron | |||||||
| AMD Athlon 64X2 | |||||||
| VIA C3 |
* v závislosti na úpravě
V tuto chvíli jsou všechny populární stolní počítače software(operační systémy Windows a Linux, kancelářské balíky, počítačové hry, atd.) je vyvinut speciálně pro procesory x86. Běží (s výjimkou „nevychovaných“ programů) na jakémkoli x86 procesoru, bez ohledu na to, kdo jej vyrobil. Proto se místo výrazů „kompatibilní s Intelem“ nebo „kompatibilní s Pentium“ orientovaných na vývojáře původní architektury začal používat neutrální název: „procesor kompatibilní s x86“, „procesor x86“. V tomto případě „architektura“ označuje kompatibilitu se specifickou sadou instrukcí, tedy můžeme říci „architektura procesoru z pohledu programátora“. Existuje další výklad stejného pojmu.
Architektura jako charakteristika rodiny procesorů
"Dělníci železa" - lidé, kteří nepracují hlavně se softwarem, ale s hardwarem, chápou pod pojmem "architektura" něco jiného (i když správnější to, čemu říkají "architektura", se nazývá "mikroarchitektura", ale de facto předpona "mikro" se často vynechává). Pro ně je „architektura CPU“ určitým souborem vlastností, které jsou vlastní celé rodině procesorů, obvykle vyráběných po mnoho let (jinými slovy „vnitřní design“, „organizace“ těchto procesorů). Takže například každý specialista na x86 CPU vám řekne, že procesor s ALU běžícími na dvojnásobné frekvenci, QDR sběrnicí, Trace cache a případně podporou technologie Hyper-Threading je „procesor architektury NetBurst“ (nelekejte se neznámé pojmy – všechny budou vysvětleny o něco později). A procesory Intel Pentium Pro, Pentium II a Pentium III jsou „architektura P6“. Pojem „architektura“ ve vztahu k procesorům je tedy poněkud nejednoznačný: může znamenat jak kompatibilitu s určitou sadou instrukcí, tak souborem hardwarových řešení, která jsou vlastní určité poměrně široké skupině procesorů. Samozřejmě, že takový dualismus jednoho ze základních konceptů není příliš pohodlný, ale stalo se tak a je nepravděpodobné, že se v blízké budoucnosti něco změní ...
64bitová rozšíření klasické architektury x86 (IA32).
Není to tak dávno, co oba přední výrobci x86 CPU oznámili dvě téměř totožné* technologie (avšak AMD tomu raději říká architektura), díky nimž získaly klasické x86 (IA32) CPU status 64bitové. V případě AMD tuto technologii obdržel název "AMD64" (64-bit architektura AMD), v případě Intel - "EM64T" (technologie rozšířené 64bitové paměti). Také ctihodní stařešinové, kteří jsou obeznámeni s historií problému, někdy používají název „x86-64“ – jako obecné označení pro všechna 64bitová rozšíření architektury x86, nevázaná na registrované ochranné známky žádného výrobce. Použití jednoho ze tří výše uvedených názvů de facto závisí více na osobních preferencích uživatele než na skutečných rozdílech – rozdíly mezi AMD64 a EM64T totiž pasují na špičku velmi tenké jehly. Samotné AMD navíc představilo „proprietární“ název „AMD64“ jen krátce před oznámením vlastních procesorů založených na této architektuře a předtím bylo celkem v klidu používat neutrálnější „x86-64“ ve vlastních dokumentech. Nicméně, tak či onak, vše vede k jedné věci: některé interní procesorové registry se staly 64bitovými namísto 32bitových, 32bitové instrukce v x86 kódu dostaly své 64bitové protějšky, navíc množství adresovatelná paměť (včetně nejen fyzické, ale i virtuální) se mnohonásobně zvětšila (vzhledem k tomu, že adresa získala 64bitový formát namísto 32bitového). Počet marketingových spekulací na téma „64-bit“ přesáhl všechny rozumné meze, a proto bychom měli přednosti této novinky zvážit zvláště pečlivě. Co se tedy vlastně změnilo a co ne?
* - Argumenty, že Intel, jak říkají, "drzám zkopíroval EM64T z AMD64", neobstojí. A už vůbec ne proto, že to tak není – ale proto, že to vůbec není „drzé“. Existuje něco jako „křížová licenční smlouva“. Pokud taková dohoda existuje, znamená to, že veškerý vývoj jedné společnosti v určité oblasti se automaticky stane dostupným pro druhou společnost, stejně jako vývoj jiné společnosti se automaticky stane dostupným pro první. Intel využil křížové licence k vývoji EM64T, založeného na AMD64 (což nikdo nikdy nepopřel). AMD využilo stejné dohody k zavedení podpory pro další instrukční sady SSE2 a SSE3 vyvinuté společností Intel do svých procesorů. A není na tom nic hanebného: jakmile jsme souhlasili se „sdílením“ vývoje, pak se musíme podělit.
Co se nezměnilo? Za prvé - rychlost procesorů. Bylo by nehorázným nesmyslem uvažovat o tom, že stejný procesor bude při přechodu z obvyklého 32bitového do 64bitového režimu (a všechny současné x86 CPU bez problémů podporují 32bitový režim) pracovat 2x rychleji. Samozřejmě, v některých případech může dojít k určitému urychlení používání 64bitové celočíselné aritmetiky – ale počet těchto případů je velmi omezený a netýkají se většiny moderního uživatelského softwaru. Mimochodem: proč jsme použili termín "64bitová celočíselná aritmetika"? Ale protože bloky operací s pohyblivou řádovou čárkou (viz níže) ve všech x86 procesorech už dávno nejsou 32bitové. A to ani 64bit. Klasický x87 FPU (viz níže), který se konečně stal součástí CPU v dobách starého dobrého 32bitového Intel Pentium - byl již 80bitový. Operandy příkazů SSE a SSE2/3 jsou vůbec 128bitové! V tomto ohledu je architektura x86 spíše paradoxní: navzdory tomu, že formálně zůstaly procesory této architektury poměrně dlouho 32bitové – bitová hloubka těch bloků, kde „b o Více bitness“ bylo skutečně nutné - bylo vybudováno zcela nezávisle na ostatních. Například procesory AMD Athlon XP a Intel Pentium 4 „Northwood“ kombinovaly bloky, které pracovaly s 32bitovými, 80bitovými a 128bitovými operandy. Pouze hlavní instrukční sada (zděděná od prvního procesoru architektury IA32 – Intel 386) a adresování paměti (maximálně 4 gigabajty, kromě „zvrhlostí“ jako je Intel PAE) zůstaly 32bitové.
Skutečnost, že se procesory AMD a Intel staly „formálně 64bitovými“, nám v praxi přinesla pouze tři vylepšení: vzhled příkazů pro práci s 64bitovými celými čísly, zvýšení počtu a/nebo bitové hloubky registrů a zvýšení maximálního množství adresovatelné paměti. Poznámka: nikdo nepopírá skutečné výhody těchto inovací (zejména té třetí!) Stejně jako nikdo nepopírá zásluhy AMD při prosazování myšlenky „modernizace“ (kvůli zavedení 64bitových) procesorů x86. Chceme jen varovat před přehnanými očekáváními: nedoufejte, že z počítače zakoupeného „v cenové třídě VAZ“ se po instalaci 64bitového softwaru stane „šmrncovní Mercedes“. Na světě nejsou žádné zázraky...
Jádro procesoru
Rozdíly mezi jádry stejné mikroarchitektury
„Jádro procesoru“ (obecně zkráceně jednoduše „jádro“) je specifická implementace [mikro]architektury (tj. „architektura v hardwarovém smyslu tohoto termínu“), která je standardem pro celou řadu procesorů. . Například NetBurst je mikroarchitektura, která je základem mnoha dnešních procesorů Intel: Celeron, Pentium 4, Xeon. Mikroarchitektura stanovuje obecné principy: dlouhý kanál, použití určitého typu mezipaměti kódu první úrovně (Trace cache) a další „globální“ funkce. Jádrem je specifičtější implementace. Například procesory mikroarchitektury NetBurst se sběrnicí 400 MHz, mezipamětí druhé úrovně o velikosti 256 kB a bez Podpora hyper-threadingu je víceméně úplný popis jádra Willamette. Ale jádro Northwood má mezipaměť druhé úrovně 512 kilobajtů, ačkoli je také založeno na NetBurst. Jádro AMD Thunderbird je založeno na mikroarchitektuře K7, ale nepodporuje instrukční sadu SSE, zatímco jádro Palomino již ano.
Můžeme tedy říci, že „jádro“ je specifickým ztělesněním určité mikroarchitektury „v křemíku“, která má (na rozdíl od mikroarchitektury samotné) určitý soubor striktně určených charakteristik. Mikroarchitektura je amorfní, popisuje obecné principy stavby procesoru. Jádro – konkrétně se jedná o mikroarchitekturu, „prorostlou“ všemožnými parametry a charakteristikami. Případy, kdy procesory změnily mikroarchitekturu a ponechaly si jméno, jsou extrémně vzácné. A naopak, téměř každý název procesoru „změnil“ jádro alespoň několikrát během své existence. Například běžný název řady procesorů AMD je „Athlon XP“ – jedná se o jednu mikroarchitekturu (K7), ale až čtyři jádra (Palomino, Thoroughbred, Barton, Thorton). Různá jádra postavená na stejné mikroarchitektuře mohou mít mimo jiné různý výkon.
Revize
Revize je jednou z úprav jádra, která se od předchozí velmi mírně liší, a proto si nezaslouží označení „nové jádro“. Výrobci procesorů zpravidla nedělají velkou událost z vydání příští revize, děje se to „v provozuschopném stavu“. Takže i když si koupíte stejný procesor, se zcela podobným názvem a vlastnostmi, ale s odstupem zhruba šesti měsíců, je to docela možné, ve skutečnosti už to bude trochu jiné. Vydání nové revize je obvykle spojeno s některými drobnými vylepšeními. Podařilo se například mírně snížit spotřebu nebo snížit napájecí napětí, případně optimalizovat něco jiného, případně se podařilo odstranit pár drobných chyb. Z hlediska výkonu si nepamatujeme jediný příklad, kdy by se jedna revize jádra lišila od druhé tak výrazně, že by mělo smysl se o tom bavit. I když je taková možnost čistě teoreticky možná – optimalizací prošla například jedna z procesorových jednotek zodpovědná za provádění několika příkazů. Shrneme-li, můžeme říci, že se většinou nevyplatí „obtěžovat“ revizemi procesoru: ve velmi vzácných případech změna revize způsobí drastické změny procesoru. Stačí vědět, že něco takového existuje - pouze pro obecný rozvoj.
Frekvence jádra
Zpravidla je to právě tento parametr, který se hovorově nazývá „frekvence procesoru“. Ačkoli v obecném případě je definice „frekvence jádra“ stále správnější, protože není vůbec nutné, aby všechny součásti CPU pracovaly na stejné frekvenci jako jádro (nejběžnějším příkladem opaku byl starý „ slot” x86 CPU – Intel Pentium II a Pentium III pro Slot 1, AMD Athlon pro Slot A – jejich mezipaměť L2 fungovala na 1/2 a někdy dokonce na 1/3 frekvence jádra). Další častou mylnou představou je přesvědčení, že frekvence jádra jednoznačně určuje výkon. Ve skutečnosti je to dvakrát špatně: za prvé, každé konkrétní jádro procesoru (v závislosti na tom, jak je navrženo, kolik výkonných jednotek obsahuje různé typy, atd. atd.) může provádět různý počet příkazů za cyklus, přičemž frekvence je pouze počet takových cyklů za sekundu. Tedy (níže uvedené srovnání je samozřejmě velmi zjednodušené a tedy velmi podmíněné) procesor, jehož jádro vykonává 3 instrukce na takt, může mít o třetinu nižší frekvenci než procesor provádějící 2 instrukce na takt - a přitom mít zcela stejná rychlost..
Za druhé, ani v rámci stejného jádra nevede zvýšení frekvence vždy k úměrnému zvýšení výkonu. Zde se vám budou velmi hodit znalosti, které jste mohli získat z části „Obecné principy interakce mezi procesorem a RAM“. Faktem je, že rychlost provádění příkazů jádrem procesoru není zdaleka jediným ukazatelem, který ovlivňuje rychlost provádění programu. Neméně důležitá je rychlost, s jakou příkazy a data přicházejí na CPU. Představte si, čistě teoreticky, takový systém: rychlost procesoru - 10 000 příkazů za sekundu, rychlost paměti - 1000 bajtů za sekundu. Otázka: i když předpokládáme, že jeden příkaz nezabere více než jeden bajt a nemáme vůbec žádná data , s jakou rychlostí bude program v takovém systému vykonáván? frekvence jádra bez současného zrychlení paměťového subsystému, protože v tomto případě, počínaje určitou fází, zvýšení frekvence CPU již neovlivní zvýšení ve výkonu systému jako celku.
Vlastnosti tvorby názvů procesorů
Dříve, když byla obloha modřejší, pivo chutnalo lépe a dívky byly hezčí, se zpracovatelům říkalo jednoduše: jméno výrobce + jméno modelová řada+ frekvence. Například: "AMD K6-2 450 MHz". V současné době již oba významní výrobci od této tradice ustoupili a místo frekvence používají nějaká nepochopitelná čísla, která naznačují kdo ví co. Stručné vysvětlení toho, co tato čísla vlastně znamenají, je předmětem následujících dvou částí.
Hodnocení od AMD
Důvod, proč AMD „odstranilo“ frekvenci z názvu svých procesorů a nahradilo ji nějakým abstraktním číslem, je dobře známo: po objevení procesoru Intel Pentium 4, který pracuje na velmi vysokých frekvencích, začaly vedle něj procesory AMD "hledej špatně v okně" - kupující nevěřil, že CPU s frekvencí např. 1500 MHz může předběhnout CPU s frekvencí 2000 MHz. Proto byla frekvence v názvu nahrazena hodnocením. Formální („de iure“, abych tak řekl) interpretace tohoto hodnocení v ústech AMD v různých dobách zněla trochu jinak, ale nikdy nezněla v podobě, v jaké ji vnímali uživatelé: procesor AMD s jistým hodnocení by nemělo být alespoň pomalejší než procesor Intel Pentium 4 s frekvencí odpovídající tomuto hodnocení. Mezitím nebylo pro nikoho zvláštním tajemstvím, že právě tato interpretace byla konečným cílem zavedení hodnocení. Obecně všichni všemu perfektně rozuměli, ale AMD se pilně tvářilo, že to s tím nemá nic společného :). Nemělo by se jí to vyčítat: v konkurenčním boji platí úplně jiná pravidla než v klání. Výsledky nezávislých testů navíc ukázaly, že obecně AMD uděluje svým procesorům celkem férová hodnocení. Ve skutečnosti, dokud tomu tak je, nemá smysl protestovat proti použití hodnocení. Pravda, jedna otázka zůstává otevřená: proč (nás samozřejmě zajímá de facto stav, a ne vysvětlivky marketingového oddělení) bude hodnocení procesorů AMD o něco později svázané, když místo Pentia 4 , Intel začne vyrábět nějaký jiný procesor?
Číslo procesoru od Intelu
Co si musíte hned zapamatovat: Číslo procesoru (dále PN) pro procesory Intel není hodnocení. Ne hodnocení výkonu a ani hodnocení čehokoli jiného. Ve skutečnosti je to jen "položka", prvek řádku v inventárním seznamu, jehož jediným úkolem je zajistit, aby se řádek pro jeden procesor lišil od řádku pro jiný. V rámci řady (první číslice PN) mohou další dvě číslice v zásadě něco říkat, ale vzhledem k přítomnosti tabulek, které ukazují úplnou shodu mezi PN a skutečnými parametry, nevidíme moc smysl si pamatovat, které jsou mezilehlé zápasy. Motivace zavedení PN od Intelu (místo opětovného zadání frekvence CPU) je složitější než u AMD. Nutnost zavedení PN (jak to vysvětluje sám Intel) je dána především tím, že oba hlavní konkurenti mají rozdílný přístup k otázce jedinečnosti názvu CPU. Například název AMD „Athlon 64 3200+“ může znamenat čtyři procesory najednou s mírně odlišnými Technické specifikace(ale stejné "hodnocení"). Intel zastává názor, že název procesoru musí být unikátní, v souvislosti s nímž dříve společnost musela „uhýbat“ přidáváním různých písmen k hodnotě frekvence v názvu, což vedlo ke zmatkům. Teoreticky měla PN tento zmatek odstranit. Těžko říci, zda bylo cíle dosaženo: přesto zůstalo názvosloví procesorů Intel poměrně komplikované. Na druhou stranu je to nevyhnutelné, protože sortiment je příliš velký. Bez ohledu na vše ostatní se však jednoho de facto efektu rozhodně podařilo dosáhnout: nyní pouze odborníci, kteří problematice rozumí, mohou rychle a přesně říci „z paměti“ jménem procesoru, o co jde a jaký bude jeho výkon ve srovnání s jinými CPU . jak je to dobré? Těžko říct. Raději to nekomentujeme.
Měření rychlosti "v megahertzech" - jak je to možné?
To je nemožné, protože rychlost se neměří v megahertzech, stejně jako se vzdálenost neměří v kilogramech. Pánové marketéři však už dávno pochopili, že ve slovním souboji fyzika s psychologem vždy vítězí ten druhý – a bez ohledu na to, kdo má vlastně pravdu. Proto čteme o „ultrarychlém 1066 MHz FSB“ a bolestně se snažíme pochopit, jak lze rychlost měřit pomocí frekvence. Ve skutečnosti, protože takový zvrácený trend zakořenil, stačí jasně pochopit, co je myšleno. A to znamená následující: pokud „opravíme“ šířku sběrnice na N bitech, pak ano propustnost skutečně bude záležet na frekvenci, na které tato sběrnice funguje, a na tom, kolik dat je schopna přenést za hodiny. Na konvenční procesorové sběrnici s „jednou“ rychlostí (např. procesor Intel Pentium III takovou sběrnici měl) se za cyklus přenese 64 bitů, tedy 8 bajtů. Pokud je tedy provozní frekvence sběrnice 100 MHz (100 "000" 000 cyklů za sekundu), pak rychlost přenosu dat bude 8 bajtů * 100 "000" 000 hertzů ~= 763 megabajtů za sekundu (a pokud počítáte v "desetinných megabajtech", ve kterých se předpokládá datové toky, pak ještě krásnější - 800 megabajtů za sekundu). Pokud tedy DDR sběrnice pracuje na stejných 100 megahertzech a je schopna přenášet dvojnásobné množství dat v jednom hodinovém cyklu, rychlost se přesně zdvojnásobí. Proto by se podle paradoxní logiky marketérů měla tato sběrnice jmenovat „200 MHz“. A pokud je to také sběrnice QDR (Quad Data Rate), pak se ukáže, že je to vůbec „400 MHz“, protože přenáší čtyři datové pakety v jednom hodinovém cyklu. I když skutečná frekvence provozu pro všechny tři výše uvedené pneumatiky je stejná - 100 megahertzů. Takto se „megahertz“ stal synonymem pro rychlost.
Sběrnice QDR (s „čtyřnásobnou“ rychlostí), pracující na reálné frekvenci 266 MHz, nám tedy magicky vyjde na „1066 MHz“. Číslo "1066" v tomto případě představuje skutečnost, že jeho šířka pásma je přesně 4x větší než u "jednorychlostní" sběrnice pracující na stejné frekvenci. Ještě nejste zmatení?.. Zvykněte si! Tohle pro vás není nějaká teorie relativity, tady je vše mnohem složitější a opomíjené... Nejdůležitější je zde však naučit se nazpaměť jednu jednoduchou zásadu: pokud už se zabýváme takovou zvráceností, jako je srovnávání rychlost dvou pneumatik k sobě „v megahertzích“, pak musí mít stejnou šířku. Jinak to dopadá jako na jednom fóru, kde člověk vážně argumentoval, že propustnost AGP2X („133 MHz“, ale 32 bit sběrnice) - vyšší než šířka pásma FSB Pentia III 800 (skutečná frekvence 100 MHz, šířka 64 bitů).
Pár slov o některých šťavnatých funkcích protokolů DDR a QDR
Jak již bylo zmíněno výše, v režimu DDR se po sběrnici v jednom hodinovém cyklu přenese dvojnásobné množství informací a v režimu QDR se zčtyřnásobí. Pravda, v dokumentech zaměřených více na glorifikaci úspěchů výrobců než na objektivní pokrytí reality, z nějakého důvodu vždy zapomenou uvést jedno malé „ale“: režimy dvojnásobné a čtyřnásobné rychlosti jsou povoleny pouze pro přenos paketových dat. To znamená, že pokud bychom požadovali několik megabajtů z paměti z adresy X na adresu Y, pak ano, tyto dva megabajty budou přeneseny dvojnásobnou/čtyřnásobnou rychlostí. Ale samotná žádost o data je odeslána po sběrnici "jedinou" rychlostí - vždy ! Pokud tedy máme mnoho požadavků a velikost odesílaných dat není příliš velká, pak množství dat, které „putuje“ po sběrnici jedinou rychlostí (a požadavek jsou také data), bude téměř rovnající se množství těch, které jsou přenášeny dvojnásobnou nebo čtyřnásobnou rychlostí. Zdá se, že nám nikdo otevřeně nelhal, zdá se, že DDR a QDR opravdu fungují, ale ... jak se říká v jednom starém vtipu: „buď někomu ukradl kožich, nebo mu někdo ukradl kožich, ale něco tam je něco není v pořádku s kožichem ... ";)
Procesor "velký blok"
Mezipaměti
Obecný popis a princip činnosti
Všechny moderní procesory mají mezipaměť (anglicky - cache). Mezipaměť je jakýsi zvláštní druh paměti (hlavní vlastností, která mezipaměť radikálně odlišuje od RAM, je její rychlost), která je jakousi „vyrovnávací pamětí“ mezi řadičem paměti a procesorem. Tento buffer slouží ke zvýšení rychlosti práce s RAM. Jak? Nyní se pokusíme vysvětlit. Zároveň jsme se rozhodli opustit srovnání zavánějící mateřskou školkou, která se často vyskytují v popularizační literatuře na procesorová témata (bazény propojené potrubím různých průměrů atd. atd.). Přesto člověk, který dočetl článek až sem a neusnul, pravděpodobně snese a „stráví“ čistě technické vysvětlení, bez kaluží, koček a pampelišek.
Představme si tedy, že máme hodně relativně pomalé paměti (ať je to 10 "000" 000 bajtů RAM) a relativně málo velmi rychlé paměti (ať je to cache o velikosti pouhých 1024 bajtů). Jak můžeme tento nešťastný kilobajt využít ke zvýšení rychlosti práce s veškerou pamětí obecně? A zde je třeba připomenout, že data v procesu provozu programu zpravidla nejsou bezmyšlenkovitě házena z místa na místo - změna. Načetli z paměti hodnotu nějaké proměnné, přidali k ní nějaké číslo – zapsali to zpět na stejné místo. Pole bylo načteno, seřazeno vzestupně - opět zapsáno do paměti. To znamená, že v určitém okamžiku program nepracuje s celou pamětí, ale zpravidla s její relativně malou částí. Jaké řešení je požadováno? Správně: načtěte tento fragment do „rychlé“ paměti, tam jej zpracujte a poté jej zapište zpět do „pomalé“ (nebo jej jednoduše smažte z mezipaměti, pokud se data nezměnila). V obecném případě přesně takto funguje mezipaměť procesoru: jakákoli informace načtená z paměti se dostane nejen do procesoru, ale také do mezipaměti. A pokud je znovu potřeba stejná informace (stejná adresa v paměti), procesor nejprve zkontroluje: je v mezipaměti? Pokud existuje, informace se převezmou odtud a přístup do paměti vůbec nenastane. Podobně se zápisem: informace, pokud se její objem vejde do mezipaměti, se tam zapíše a teprve poté, když procesor dokončí operaci zápisu a začne provádět další příkazy, se data zapíší do mezipaměti. souběžně s prací jádra procesoru„pomalu unloaded“ do RAM.
Množství přečtených a zapsaných dat za celou dobu běhu programu je samozřejmě mnohem větší než velikost mezipaměti. Některé z nich je proto nutné čas od času smazat, aby se do mezipaměti vešly nové, relevantnější. Nejjednodušším známým mechanismem pro zajištění tohoto procesu je sledování času posledního přístupu k datům v mezipaměti. Pokud tedy potřebujeme vložit nová data do mezipaměti a je již „plná kapacita“, řadič, který spravuje mezipaměť, vypadá: ke kterému fragmentu mezipaměti nebylo přistupováno nejdelší dobu? Právě tento fragment je prvním kandidátem na „odjezd“ a na jeho místo jsou zapsána nová data, se kterými je třeba nyní pracovat. Takto obecně funguje cachovací mechanismus v procesorech. Výše uvedené vysvětlení je samozřejmě velmi primitivní, ve skutečnosti je ještě složitější, ale doufáme, že jste byli schopni získat obecnou představu o tom, proč procesor potřebuje mezipaměť a jak funguje.
A abychom pochopili, jak je cache důležitá, uveďme si jednoduchý příklad: rychlost výměny dat procesoru Pentium 4 s jeho cache je více než 10x (!) vyšší než rychlost jeho práce s pamětí. Moderní procesory ve skutečnosti dokážou naplno pracovat pouze s mezipamětí: jakmile se setkají s potřebou číst data z paměti, všechny jejich vychvalované megahertzy začnou jednoduše „ohřívat vzduch“. Opět jednoduchý příklad: provedení nejjednodušší instrukce procesorem proběhne v jednom cyklu, to znamená, že za sekundu může provést takové číslo jednoduché instrukce, jakou má frekvenci (ve skutečnosti i více, ale to si necháme na později ...). Čekací doba na data z paměti ale může být v nejhorším případě i více než 200 cyklů! Co dělá procesor, když čeká na správná data? A on nic nedělá. Jen tak stát a čekat...
Víceúrovňové ukládání do mezipaměti
Specifický design moderních procesorových jader vedl k tomu, že cachovací systém v naprosté většině CPU musí být víceúrovňový. Mezipaměť první úrovně (nejblíže jádru) je tradičně rozdělena na dvě (obvykle stejné) poloviny: mezipaměť instrukcí (L1I) a mezipaměť dat (L1D). Toto rozdělení zajišťuje tzv. „Harvardská architektura“ procesoru, což je v současnosti nejpopulárnější teoretický vývoj pro stavbu moderních CPU. V L1I se akumulují pouze příkazy (s tím pracuje dekodér, viz níže) a v L1D - pouze data (ty následně zpravidla spadají do vnitřních registrů procesoru). "Nad L1" je mezipaměť druhé úrovně - L2. Zpravidla má větší objem a je již „smíšený“ - jsou tam umístěny příkazy i data. L3 (mezipaměť třetí úrovně) zpravidla zcela opakuje strukturu L2 a zřídka se vyskytuje v moderních procesorech x86. L3 je častěji plodem kompromisu: použitím pomalejší a užší sběrnice může být velmi velká, ale rychlost L3 je stále vyšší než rychlost paměti (i když ne tak rychlá jako mezipaměť L2). ). Algoritmus pro práci s víceúrovňovou vyrovnávací pamětí se však obecně neliší od algoritmu pro práci s jednoúrovňovou vyrovnávací pamětí, pouze jsou přidány další iterace: nejprve se vyhledávají informace v L1, pokud tam nejsou, v L2, pak v L3, a teprve potom, pokud žádná není nalezena na jedné úrovni mezipaměti - probíhá přístup k hlavní paměti (RAM).
Dekodér
Ve skutečnosti, prováděcí jednotky všech moderních x86 desktopových procesorů... vůbec nepracují s x86 kódem. Každý procesor má svůj vlastní "vnitřní" příkazový systém, který nemá nic společného s těmi příkazy (tedy "kódem"), které přicházejí zvenčí. Obecně jsou příkazy prováděné jádrem mnohem jednodušší, "primitivní" než příkazy standardu x86. Právě proto, aby procesor „vypadal navenek“ jako CPU x86, existuje takový blok jako dekodér: je zodpovědný za převod „externího“ kódu x86 na „interní“ příkazy prováděné jádrem (v tomto V případě, je poměrně často jedna instrukce kódu x86 převedena na poněkud jednodušší "interní"). Dekodér je velmi důležitou součástí moderního procesoru: jeho rychlost určuje, jak konstantní bude tok příkazů přijatých vykonávajícími jednotkami. Neumí totiž pracovat s kódem x86, takže to, zda budou něco dělat nebo budou nečinné, závisí do značné míry na rychlosti dekodéru. Poněkud neobvyklý způsob, jak urychlit proces dekódování příkazů, implementoval Intel v procesorech architektury NetBurst – viz níže o Trace cache.
Prováděcí (funkční) zařízení
Po projití všech úrovní mezipaměti a dekodéru se příkazy konečně dostanou k těm blokům, kvůli kterým byl celý tento nepořádek uspořádán: vystupování zařízení. Ve skutečnosti jsou to prováděcí zařízení jediný nezbytný prvek procesor. Můžete to udělat bez mezipaměti - rychlost se sníží, ale programy budou fungovat. Můžete se obejít bez dekodéru - prováděcí zařízení se zkomplikují, ale procesor bude fungovat. Rané x86 procesory (i8086, i80186, 286, 386, 486, Am5x86) si nakonec bez dekodéru nějak poradily. Bez spouštěcích zařízení se to neobejde, protože spouštějí programový kód. V úplně prvním přiblížení se tradičně dělí na dva velké skupiny: Aritmetické logické jednotky (ALU) a jednotky s pohyblivou řádovou čárkou (FPU).
Aritmetické logické jednotky
ALU jsou tradičně zodpovědné za dva typy operací: aritmetické operace (sčítání, odčítání, násobení, dělení) s celými čísly, logické operace opět s celými čísly (logické "a", logické "nebo", "exkluzivní nebo" a podobně). Což ostatně vyplývá z jejich názvu. V moderních procesorech je obvykle několik ALU. K čemu - pochopíte později přečtením části "Superskalarita a provádění příkazů mimo pořadí." Je jasné, že ALU může provádět pouze ty příkazy, které jsou pro něj určeny. Distribuce příkazů přicházejících z dekodéru do různých prováděcích zařízení je řešena speciálním blokem, ale to je, jak se říká, „příliš složitá záležitost“ a stěží má smysl je vysvětlovat v materiálu, který je věnován pouze povrchní seznámení se základními principy moderního provozu x86 CPU.
Jednotka s plovoucí desetinnou čárkou*
FPU se zabývá prováděním instrukcí, které pracují s čísly s plovoucí desetinnou čárkou, navíc na ni tradičně „věší všechny psy“ v podobě všemožných doplňkových sad instrukcí (MMX, 3DNow !, SSE, SSE2 , SSE3 ...) - bez ohledu na to, zda pracují s čísly s plovoucí desetinnou čárkou nebo s celými čísly. Stejně jako v případě ALU může být v FPU několik samostatných bloků, které mohou pracovat paralelně.
* - podle tradic ruské matematické školy nazýváme FPU „plovoucí jednotkou“ čárka“, i když se doslova jmenuje (Plovoucí směřovat Unit) se překládá jako "... plovoucí desetinná čárka" - podle amerického standardu pro zápis takových čísel.
Registry procesoru
Registry – ve skutečnosti stejné paměťové buňky, ale „územně“ jsou umístěny přímo v jádře procesoru. Rychlost práce s registry je samozřejmě mnohonásobně větší než rychlost práce s paměťovými buňkami umístěnými v hlavní RAM (zde obecně řádově ...), a s cache libovolné úrovně. Proto většina instrukcí architektury x86 poskytuje implementaci akcí na obsahu registrů a ne na obsahu paměti. Celková velikost registrů procesoru je však většinou velmi malá – nelze ji srovnávat ani s velikostí cache první úrovně. Proto de facto programový kód (ne v jazyce vysoká úroveň, jmenovitě binární, „stroj“) často obsahuje následující posloupnost operací: načíst informace z RAM do jednoho z registrů procesoru, načíst další informace (také z RAM) do jiného registru, provést nějakou akci s obsahem těchto registrů, umístit výsledek ve třetím - a pak výsledek znovu načíst z registru do hlavní paměti.
Procesor v detailu
Vlastnosti keší
Frekvence cache a její sběrnice
Ve všech moderních procesorech x86 pracují všechny úrovně mezipaměti na stejné frekvenci jako jádro procesoru, ale ne vždy tomu tak bylo (tento problém již byl zmíněn výše). Rychlost práce s cache však závisí nejen na frekvenci, ale také na šířce sběrnice, přes kterou je připojena k jádru procesoru. Jak si (doufejme) pamatujete z toho, co jste si přečetli dříve, rychlost přenosu dat je v podstatě součinem frekvence sběrnice (počet hodin za sekundu) krát počtu bajtů, které jsou přeneseny na sběrnici v jednom hodinovém cyklu. Počet bajtů přenesených za takt lze zvýšit zavedením protokolů DDR a QDR (Double Data Rate and Quad Data Rate) – nebo jednoduše zvětšením šířky sběrnice. V případě cache je populárnější druhá možnost – v neposlední řadě kvůli výše popsaným „pikantem“ DDR/QDR. Samozřejmě minimální rozumná šířka cache sběrnice je šířka vnější sběrnice samotného procesoru, tedy k dnešnímu dni - 64 bitů. Přesně to dělá AMD v duchu zdravého minimalismu: u jeho procesorů je šířka sběrnice L1 L2 64 bitů, ale zároveň je obousměrná, to znamená, že je schopná současně vysílat a přijímat informace. V duchu „zdravého gigantismu“ Intel opět jednal: ve svých procesorech, počínaje Pentiem III „Coppermine“, má sběrnice L1 L2 šířku ... 256 bitů! Podle zásady „kaši olejem nezkazíš“, jak se říká. Je pravda, že tato sběrnice je jednosměrná, to znamená, že v jednom okamžiku funguje buď pouze pro vysílání, nebo pouze pro příjem. Debata o tom, který přístup je lepší (obousměrná sběrnice, ale užší, nebo jednosměrná široká) stále probíhá...nicméně i mnoho dalších sporů ohledně technických řešení používaných dvěma hlavními konkurenty na trhu x86 CPU.
Exkluzivní a neexkluzivní cache
Koncept exkluzivního a neexkluzivního ukládání do mezipaměti je velmi jednoduchý: v případě nevýhradní mezipaměti lze duplikovat informace na všech úrovních ukládání do mezipaměti. L2 tedy může obsahovat data, která jsou již v L1I a L1D, a L3 (pokud existuje) může obsahovat úplnou kopii celého obsahu L2 (a podle toho i L1I a L1D). Exkluzivní cache na rozdíl od neexkluzivní cache poskytuje jasné rozlišení: pokud je informace obsažena na nějaké úrovni cache, pak chybí na všech ostatních. Výhoda exkluzivní cache je zřejmá: celková velikost cache informací se v tomto případě rovná celkovému objemu cache všech úrovní – na rozdíl od neexkluzivní cache, kde je velikost cache informací (v nejhorším případě ) se rovná objemu největší úrovně mezipaměti. Mínus exkluzivní mezipaměti je méně zřejmý, ale existuje: je zapotřebí speciální mechanismus, který monitoruje skutečnou „exkluzivitu“ (například když jsou informace vymazány z mezipaměti L1, proces jejich kopírování do L2 je automaticky zahájen před že).
Neexkluzivní cache používá tradičně Intel, exkluzivní (od vzhledu procesorů Athlon založených na jádře Thunderbird) používá AMD. Obecně jsme zde svědky klasické konfrontace mezi objemem a rychlostí: AMD má díky exkluzivitě při stejných objemech L1/L2 větší celkovou velikost informací v mezipaměti – díky ní ale také funguje pomaleji (zpoždění způsobené přítomností mechanismu exkluzivity). Asi je třeba poznamenat, že Intel v poslední době kompenzoval nedostatky neexkluzivní mezipaměti jednoduše, hloupě, ale těžce: zvýšením jejího objemu. U špičkových procesorů této společnosti se 2 MB L2 cache stala téměř normou - a AMD se svými 128 KB L1C + L1D a maximálně 1 MB L2 tyto 2 MB zatím "překonat" nemůže ani kvůli exkluzivitě.
Kromě toho má smysl zvýšit celkové množství informací uložených v mezipaměti zavedením exkluzivní architektury mezipaměti pouze v případě, že je nárůst objemu dostatečně velký. a m. Pro AMD je to relevantní. jeho současné CPU mají celkovou velikost L1D+L1I 128 KB. Procesory Intel, jejichž velikost L1D je maximálně 32 KB a L1I mají někdy úplně jinou strukturu (viz o Trace cache), by zavedení exkluzivní architektury přineslo mnohem menší přínos.
A také existuje taková běžná mylná představa, že architektura mezipaměti procesorů Intel je „inkluzivní“. Spíš ne. NENÍ exkluzivní. Inkluzivní architektura to zajišťuje na „nižší“ úrovni mezipaměti nemůže být čímkoli, co není na více „horní“. Nejen exkluzivní architektura přiznává duplikace dat na různých úrovních.
Trace cache
Koncept Trace cache je ukládat do instrukční cache první úrovně (L1I) nikoli ty příkazy, které se čtou z paměti, ale již dekódované sekvence (viz dekodér). Pokud je tedy x86 instrukce znovu provedena a je stále v L1I, procesorový dekodér ji nemusí znovu překládat do sekvence instrukcí "vnitřního kódu", protože L1I obsahuje tuto sekvenci ve své již dekódované podobě. Koncept Trace cache velmi dobře zapadá do obecné koncepce architektury Intel NetBurst, která je zaměřena na vytváření procesorů s velmi vysokou frekvencí jádra. Nicméně užitečnost Trace cache pro [relativně] CPU s nižší frekvencí je stále sporná, protože složitost organizace Trace cache se stává srovnatelnou s úkolem navrhnout konvenční rychlý dekodér. I když tedy vzdáváme hold originalitě nápadu, stále bychom řekli, že Trace cache nelze považovat za univerzální řešení „pro všechny příležitosti“.
Superskalární a mimo provoz
Hlavním rysem všech moderních procesorů je, že jsou schopny spustit k provedení nejen instrukci, která má být (podle programového kódu) v daném čase vykonána, ale i další po ní následující. Zde je jednoduchý (kanonický) příklad. Předpokládejme, že bychom měli provést následující posloupnost příkazů:
1) A = B + C
2) Z = X + Y
3) K = A + Z
Je dobře vidět, že příkazy (1) a (2) jsou na sobě zcela nezávislé - neprotínají se ani v počátečních datech (proměnné B a C v prvním případě, X a Y ve druhém), popř. v místě výsledku (proměnná A in v prvním případě a Z ve druhém). Pokud tedy v tuto chvíli máme více než jeden volný prováděcí blok, lze tyto příkazy rozdělit mezi ně a provádět je současně, nikoli postupně *. Pokud tedy vezmeme dobu provádění každé instrukce rovnou N cyklům procesoru, pak by v klasickém případě provedení celé sekvence zabralo N * 3 cykly a v případě paralelního provedení pouze N * 2 cykly (protože příkaz (3) nelze provést bez čekání na výsledek provedení předchozích dvou).
* - míra paralelismu samozřejmě není nekonečná: příkazy lze provádět paralelně pouze tehdy, je-li v daném čase odpovídající počet volných bloků (FU), a přesně ti, kteří dotyčným příkazům „rozumějí“.. Nejjednodušší příklad: blok související s ALU není fyzicky schopen provést instrukci určenou pro FPU. Opak je také pravdou.
Ve skutečnosti je to ještě obtížnější. Pokud tedy máme následující sekvenci:
1) A = B + C
2) K = A + M
3) Z = X + Y
Potom se změní fronta provádění příkazů procesoru! Vzhledem k tomu, že příkazy (1) a (3) jsou na sobě nezávislé (ani z hlediska zdrojových dat, ani z hlediska umístění výsledku), mohou být prováděny paralelně – a budou prováděny paralelně. Po nich se ale provede příkaz (2) (ten třetí) - protože aby byl výsledek výpočtu správný, je nutné, aby byl příkaz (1) proveden ještě před tím. Proto se mechanismus diskutovaný v této části nazývá „provádění příkazů mimo pořadí“ (provádění mimo pořadí, zkráceně „OoO“): v případech, kdy příkaz provedení nemůže žádným způsobem ovlivnit výsledek , jsou příkazy odesílány k provedení ve špatném pořadí.pořadí, ve kterém jsou umístěny v kódu programu, ale v takovém, který umožňuje dosáhnout maximálního výkonu.
Nyní by vám mělo být zcela jasné, proč moderní CPU potřebují tolik podobných prováděcích jednotek: poskytují schopnost paralelně provádět několik instrukcí, které by v případě „klasického“ přístupu k návrhu procesoru musely být vykonávány v pořadí, ve kterém jsou obsaženy zdrojový kód, jeden za druhým.
Procesory vybavené mechanismem pro paralelní provádění několika po sobě jdoucích příkazů se nazývají „superskalární“. Ne všechny superskalární procesory však podporují spouštění mimo pořadí. V prvním příkladu nám tedy stačí „jednoduchá superskalarita“ (provádění dvou po sobě jdoucích příkazů současně) – ale ve druhém příkladu se neobejdeme bez přeuspořádání příkazů na místech, pokud chceme získat maximální výkon . Všechny moderní x86 CPU mají obě vlastnosti: jsou superskalární a podporují provádění instrukcí mimo pořadí. Přitom v historii x86 existovaly i „jednoduché superskaláry“, které nepodporovaly OoO. Například klasický desktopový x86 superskalar bez OoO byl Intel Pentium.
Pro spravedlnost je třeba poznamenat, že ani Intel, ani AMD, ani žádný jiný (včetně zesnulého) výrobce x86 CPU nemá žádnou zásluhu na vývoji superskalárních a OoO konceptů. První superskalární počítač podporující OoO vyvinul Seymour Cray již v 60. letech 20. století. Pro srovnání: Intel vydal svůj první superskalární procesor (Pentium) v roce 1993, první superskalární s OoO (Pentium Pro) - v roce 1995; První superskalar AMD s OoO (K5) byl vydán v roce 1996. Komentáře, jak se říká, jsou zbytečné...
Předběžné (pokročilé) dekódování
a ukládání do mezipaměti
Predikce větve
V každém více či méně složitém programu existují příkazy podmíněného skoku: "Pokud je určitá podmínka pravdivá, přejděte ke spuštění jedné části kódu, pokud ne, další." Z pohledu rychlosti provádění programového kódu moderním procesorem, který podporuje spouštění mimo pořadí, je jakákoliv podmíněná instrukce větvení skutečně boží metlou. Koneckonců, dokud nebude známo, která část kódu po podmíněném přechodu bude „relevantní“ - není možné ji začít dekódovat a provádět (viz provedení mimo pořadí). Aby bylo možné nějak sladit koncept provádění mimo pořadí s podmíněnými instrukcemi větvení, je určen speciální blok: blok predikce větvení. Jak jeho název napovídá, ve skutečnosti se zabývá „proroctvími“: snaží se předpovědět, na kterou část kódu bude instrukce podmíněného skoku ukazovat, a to ještě předtím, než je provedena. V souladu s pokyny „pravidelného vnitrojaderného proroka“ provádí procesor zcela skutečné akce: „předpovězená“ část kódu je načtena do mezipaměti (pokud tam není) a dokonce začíná dekódování a provádění jejích příkazů. . Navíc mezi prováděnými příkazy mohou být také instrukce podmíněného skoku a jejich výsledky jsou také predikovány, což generuje celý řetězec dosud neověřeno předpovědi! Samozřejmě, pokud je prediktor větvení chybný, veškerá práce provedená v souladu s jeho předpověďmi je jednoduše zrušena.
Algoritmy používané blokem predikce větví nejsou ve skutečnosti vůbec mistrovskými díly umělé inteligence. Většinou jsou jednoduché... a hloupé. Instrukce podmíněného větvení se nejčastěji vyskytuje v cyklech: určitý čítač nabývá hodnoty X a po každém průchodu cyklu se hodnota čítače o jedničku sníží. V souladu s tím, pokud je hodnota čítače větší než nula, provede se přechod na začátek cyklu a poté, co bude rovna nule, provádění pokračuje dále. Blok predikce větvení jednoduše analyzuje výsledek provádění instrukce podmíněného větvení a uvažuje, že pokud Nkrát za sebou byl výsledkem skok na určitou adresu, pak v N + 1 případech bude proveden skok na stejnou adresu. Přes všechen primitivismus však toto schéma funguje dobře: pokud například čítač nabývá hodnoty 100 a „spouštěcí práh“ větveného prediktoru (N) se rovná dvěma skokům v řadě na stejnou adresu, je snadné vidět, že 97 přechodů z 98 bude předpovězeno správně!
Samozřejmě, i přes poměrně vysokou účinnost jednoduchých algoritmů se mechanismy predikce větví v moderních CPU stále neustále zlepšují a stávají se komplikovanějšími - ale tady mluvíme o boji o jednotky procent: například zvýšit efektivitu blok predikce větve z 95 procent na 97, nebo dokonce z 97 % na 99...
Předběžné načítání dat
Blok prefetch dat (Prefetch) je principiálně velmi podobný bloku predikce větve - jen s tím rozdílem, že v tomto případě mluvíme o datech, nikoli o kódu. Obecný princip fungování je stejný: pokud vestavěný obvod analýzy přístupu k datům v RAM rozhodne, že určitá paměťová oblast, která ještě nebyla načtena do mezipaměti, bude brzy zpřístupněna, vydá příkaz k načtení této paměťové oblasti do cache ještě dříve, než to vyžaduje spustitelný program. „Inteligentně“ (efektivně) fungující blok přednačtení může výrazně zkrátit dobu přístupu k požadovaným datům, a tím zvýšit rychlost provádění programu. Mimochodem: kompetentní Prefetch velmi dobře kompenzuje vysokou latenci paměťového subsystému, načítá potřebná data do mezipaměti, a tím vyrovnává zpoždění při přístupu k nim, pokud nebyly v mezipaměti, ale v hlavní RAM.
V případě chyby v bloku prefetch dat jsou však samozřejmě negativní důsledky nevyhnutelné: Načtením de facto „zbytečných“ dat do mezipaměti z ní Prefetch vytlačí další (snad jen ty správné). Navíc kvůli "předvídání" operace čtení vzniká další zátěž na paměťovém řadiči (de facto v případě chyby je to úplně zbytečné).
Algoritmy předběžného načítání, stejně jako algoritmy bloku predikce větvení, také nezáří inteligencí: zpravidla se tento blok snaží sledovat, zda jsou informace čteny z paměti s určitým „krokem“ (podle adres), a na základě toho analýze se snaží předvídat, ze které adresy budou data čtena v průběhu další činnosti programu. Stejně jako v případě bloku predikce větvení však jednoduchost algoritmu vůbec neznamená nízkou efektivitu: v průměru blok přednačtení dat „zasáhne“ častěji, než udělá chyby (a to, jako v předchozím případě , je způsobeno především tím, že „masivní“ čtení dat z paměti zpravidla nastává během provádění různých cyklů).
Závěr
Jsem ten králík, který nemůže začít jíst trávu, dokud
nebude podrobně chápat, jak probíhá proces fotosyntézy!
(vyjádření osobního postoje jedním z autorových blízkých známých)
Je docela možné, že pocity, které jste měli po přečtení tohoto článku, se dají popsat asi takto: „Místo toho, abych na prstech vysvětloval, který procesor je lepší, vzali to a zatížili můj mozek hromadou konkrétních informací, které stále mám. rozumět a rozumět a konec v nedohlednu!" Zcela normální reakce: věřte, že vám rozumíme dobře. Řekněme si ještě více (a ať nám spadne koruna z hlavy!): pokud si myslíte, že na tuto jednoduchou otázku („který procesor je lepší?“) dokážeme odpovědět sami, tak se velmi mýlíte. Nemůže. Pro některé úkoly je lepší jeden, pro jiné - druhý a pak je jiná cena, dostupnost, sympatie konkrétního uživatele k určitým značkám... Úkol nemá jednoznačné řešení. Kdyby ano, určitě by to někdo našel a stal by se nejslavnějším sloupkařem v historii nezávislých testovacích laboratoří.
Rád bych znovu zdůraznil: i když plně rozumíte a rozumíte všem informacím uvedeným v tomto materiálu, stále nemůžete předvídat, který z těchto dvou procesorů bude ve vašich úkolech rychlejší, pouze se podíváte na jejich vlastnosti. Za prvé proto, že zde nejsou zohledněny zdaleka všechny vlastnosti procesorů. Za druhé proto, že existují i takové parametry CPU, které lze v číselné podobě znázornit jen s velmi velkým „roztažením“. Takže pro koho (a proč) je to všechno napsáno? V podstatě - pro ty samé "králíky", kteří jistě chtějí vědět, co se děje uvnitř zařízení, která denně používají. za co? Možná se jen cítí lépe, když vědí, co se kolem nich děje? :)
Budoucí plány na rozšíření FAQ:
- Část o víceprocesorových systémech: vysvětlení pojmu SMP, technologie Hyper-Threading, N-procesor, N-core.
- Oddíl věnovaný fyzikální vlastnosti CPU: typy šasi, zásuvky, spotřeba energie atd.
Dnes už nikoho nepřekvapí, že oblíbená rodinná fotografie, uložená a chráněná před zákeřnými překvapeními v podobě například vody od nešťastných sousedů z nejvyššího patra, kteří zapomněli zavřít kohoutek, může být nějaký druh nepochopitelné množiny čísel a zároveň zůstat rodinnou fotografií. domácí počítač se stala samozřejmostí jako „krabice“ s modrou obrazovkou. Nepřekvapí mě, když bude domácí počítač brzy postaven na roveň domácím elektrickým spotřebičům. Mimochodem, „motor pokroku“, známý všem Intel, nám to prorokuje a propaguje myšlenku digitální domácnosti.
Osobní počítač tedy obsadil své místo ve všech sférách lidského života. Jeho podoba a formování jako nedílného prvku způsobu života se již stalo historií. Když mluvíme o počítačích PC, máme na mysli systémy kompatibilní s IBM PC, a to právem. Málokterý čtenář někdy na vlastní oči viděl systém, který není kompatibilní s PC od IBM, natož aby jej používal.
Všechny počítače IBM a kompatibilní jsou založeny na procesorech x86. Abych byl upřímný, někdy se mi zdá, že nejde jen o architekturu procesoru, ale o architekturu celého PC, jako o ideologii systému jako celku. Těžko říct, kdo koho táhl, zda vývojáři periferních zařízení a koncových produktů se přizpůsobili architektuře x86, nebo naopak přímo či nepřímo tvořili cestu vývoje pro procesory x86. Historie x86 není hladká dlážděná cesta, ale kombinace kroků vývojářů různé „závažnosti“ a geniality, silně provázané ekonomickými faktory. Znalost historie x86 procesorů není vůbec nutná. Srovnávat procesor dnešní reality s jeho dávnými předky je prostě nesmyslné. Abychom však mohli sledovat obecné trendy vývoje a pokusit se vytvořit předpověď, je nezbytný exkurz do historické minulosti architektury x86. Pochopitelně, že seriózní historická práce může zabrat více než jeden svazek a nemá smysl žádat objektivní a široké pokrytí tématu. Nebudeme se proto pouštět do peripetií „životnosti“ jednotlivých generací x86 procesorů, ale omezíme se na nejdůležitější události celého x86 eposu.
1968
Čtyři zaměstnanci Fairchild Semiconductor: Bob Noyce, manažer a vynálezce integrovaného obvodu v roce 1959, Gordon Moore, vedoucí výzkumu a vývoje, Andy Grove, chemický inženýr, a Arthur Rock, finanční podporovatel, založili Intel. Tento název je odvozen od Integral Electronic.
1969
Bývalý marketingový ředitel Fairchild Semiconductor Jerry Sanders a několik jeho spolupracovníků založili společnost AMD (Advanced Micro Devices), která začala vyrábět mikroelektronická zařízení.
1971
Při plnění jedné z objednávek na čipy RAM navrhl zaměstnanec Intelu Ted Hoff vytvoření univerzálního „chytrého“ IC. Vývoj vedl Federico Fagin. V důsledku toho se zrodil první mikroprocesor Intel 4004.
1978
Celé období před tímto je pravěk, i když neoddělitelné od událostí, které se staly později. Letos začala éra x86 – Intel vytvořil mikroprocesor i8086, který měl frekvence 4,77,8 a 10 MHz. Vtipné frekvence? Ano, to jsou frekvence moderních kalkulaček, ale u nich to všechno začalo. Čip byl vyroben pomocí 3mikronové technologie a měl vnitřní 16bitový design a 16bitovou sběrnici. To znamená, že se objevila 16bitová podpora a následně 16bitové operační systémy a programy.
O něco později, ve stejném roce, byl vyvinut i8088, jehož hlavním rozdílem byla 8bitová externí datová sběrnice, která zajišťovala kompatibilitu s dříve používanou 8bitovou vazbou a pamětí. Argumentem v jeho prospěch byla i kompatibilita s i8080/8085 a Z-80, relativně nízká cena. Ať je to jak chce, IBM zvolilo i8088 jako CPU pro své první PC. Od té doby se procesor Intel stane nedílnou součástí osobní počítač, a samotný počítač se bude ještě dlouho jmenovat IBM PC.
 |
1982
i80286 oznámeno. „286th“ se stal prvním x86 procesorem, který pronikl do sovětského a postsovětského prostoru velké množství. Taktovaný na 6, 8, 10 a 12 MHz byl vyroben pomocí 1,5mikronové procesní technologie a obsahoval asi 130 000 tranzistorů. Tento čip měl plnou 16bitovou podporu. Poprvé, s příchodem i80286, se objevil takový koncept jako „chráněný režim“, ale poté vývojáři softwaru nevyužili jeho schopnosti naplno. Procesor mohl přepnutím do chráněného režimu adresovat více než 1 MB paměti, ale po úplném restartu bylo možné se vrátit zpět a segmentovaná organizace přístupu do paměti vyžadovala značné dodatečné úsilí při psaní programového kódu. To vedlo k tomu, že i80286 byl používán spíše jako rychlý i8086.
 |
Výkon čipu ve srovnání s 8086 (a zejména ve srovnání s i8088) se několikanásobně zvýšil a dosáhl 2,6 milionu operací za sekundu. V těchto letech začali výrobci aktivně využívat otevřenou architekturu IBM PC. Zároveň začalo období klonování procesorů architektury x86 od Intelu výrobci třetích stran. Čili čip vyrobily jiné společnosti ve formě přesné kopie. Intel 80286 se stal základem pro nejnovější IBM PC/AT a jeho četné klony. Hlavní přednosti nového procesoru byly zvýšený výkon a další režimy adresování. A co je nejdůležitější – kompatibilita se stávajícím softwarem. Procesor byl samozřejmě také licencován třetími stranami...
V témže roce AMD uzavírá licenční smlouvu s Intelem a na jejím základě zahajuje výrobu klonů x86 procesorů.
1985
Letos se odehrála možná nejvýznamnější událost v historii x86 procesorů – Intel vydal první procesor i80386. Stal se, dalo by se říci, revolučním: 32bitový multitaskingový procesor se schopností spouštět více programů současně. Ve skutečnosti nejmodernější procesory nejsou nic jiného než rychlé 386. Moderní software používá stejnou architekturu 386, jen moderní procesory dělají to samé, jen rychleji. Intel 386™ je velkým vylepšením oproti i8086 a i80286. Ve skutečnosti nejmodernější procesory nejsou nic jiného než rychlé 386. Moderní software používá stejnou architekturu 386, jen moderní procesory dělají to samé, jen rychleji. Intel 386™ je velkým vylepšením oproti i8086 a i80286. Intel 386™ výrazně zlepšil správu paměti oproti i80286 a vestavěný multitasking umožnil vývoj operační systém Microsoft Windows a OS/2.
 |
Na rozdíl od i80286 mohl Intel 386™ volně přepínat z chráněného režimu do reálného režimu a zpět a měl nový režim, virtuální 8086. V tomto režimu mohl procesor spouštět několik různých softwarových vláken současně, protože každé z nich jel na izolovaném „virtuálním“ 86. voze. Procesor zavedl další režimy adresování paměti s proměnnou délkou segmentu, což značně zjednodušilo tvorbu aplikací. Procesor byl vyroben 1mikronový výrobní proces. Poprvé byl procesor Intel představen s několika modely, které tvořily rodinu 386. Zde začíná slavná marketingová hra Intelu, která později vyústila v rozdělení jednoho vyvinutého jádra na dvě obchodní opce, které se v určitém okruhu uživatelů a specialistů říká: "Pentium pro bohaté, Celeron pro chudé." I když co je tady špatně - a vlci jsou sytí a ovce jsou v bezpečí.
Byly vydány následující modely:
386DX na 16, 20, 25 a 33 MHz měl 4 GB adresovatelné paměti;
386SX s frekvencí 16, 20, 25 a 33 MHz měl na rozdíl od 386DX 16, nikoli 32bitovou datovou sběrnici, a tedy 16 MB adresovatelné paměti (podobným způsobem najednou i8088 procesor byl "vytvořen" z i8086 externí sběrnicí, aby byla zajištěna kompatibilita se stávajícími externími zařízeními);
386SL v říjnu 1990 - mobilní verze procesor Intel 386SX s frekvencí 20 a 25MHz.
1989
Intel Corporation uvádí na trh svůj další procesor – Intel 486™ DX s frekvencí 25, 33 a 50 MHz. Intel 486™ DX byl prvním procesorem v rodině 486 a měl významný (více než 2krát na stejné frekvenci) zvýšení výkonu ve srovnání s rodinou 386. -mezipaměť zvýšena na 512 Kb. i486DX integroval jednotku s pohyblivou řádovou čárkou (FPU - Floating Point Unit), která dříve běžela jako externí matematický koprocesor nainstalovaný na základní desce. Navíc se jedná o první procesor, jehož jádro obsahovalo pětistupňovou pipeline. Instrukce, která prošla první fází potrubí a pokračovala ve zpracování ve druhé, tedy uvolnila první pro další instrukci. Ve svém jádru byl procesor Intel 486™DX rychlý Intel 386DX™ kombinovaný s matematickým koprocesorem a 8K mezipamětí na jedné matrici. Taková integrace umožnila zvýšit rychlost komunikace mezi bloky na velmi vysoké hodnoty.
Intel spustil reklamní kampaň se sloganem „Intel: The Computer Inside“. Čas uplyne a promění se ve slavnou reklamní kampaň „Intel Inside“.
 |
1991
Byl vytvořen vlastní procesor AMD, Am386™. Tento byl postaven částečně na základě licence, částečně interně a běžel na maximální frekvenci 40 MHz, což je vyšší frekvence než u procesoru Intel.
O něco dříve proběhl první soudní spor mezi Intelem a AMD kvůli záměru AMD prodat svůj klon Intel 386™. Po pevném posílení své pozice již Intel nepotřeboval distribuovat licence výrobcům třetích stran a nehodlal se s nikým dělit o svůj vlastní koláč. V důsledku toho AMD poprvé vstoupilo na trh procesorů x86 jako konkurent. Následovaly další společnosti. Začala tak pokračující velká konfrontace mezi oběma giganty (zbytek závodníků vypadl ze závodu), která dala světu mnoho dobrého. Nevyřčený slogan konkurenti Intelu se stala věta: "stejné jako Intel, ale za nižší cenu."
Intel zároveň vydává i486SX, kterému chybí FPU (integrovaný koprocesor), aby se snížila cena produktu, což se samozřejmě negativně projevilo na výkonu. Žádné další rozdíly oproti i486DX nebyly.
 |
1992
S uvedením procesoru Intel 486DX2 byl poprvé použit násobič frekvence sběrnice. Až do tohoto okamžiku se vnitřní frekvence jádra rovnala frekvenci externí datové sběrnice (FSB), ale byl problém ji zvýšit, protože místní periferní sběrnice (v té době VESA VL-bus) a oni sami periferie vykazoval nestabilitu při frekvenci přesahující 33 MHz. Nyní, s 33 MHz FSB, byla frekvence jádra 66 MHz kvůli násobení 2. Tato technika již dávno vstoupila do historie a dodnes se používá, pouze násobič v moderních CPU může překročit 20. Intel 486™ DX2 se stal na dlouhou dobu populárním procesorem a prodával se ve velkém množství, stejně jako jeho klony od konkurentů (AMD, Cyrix a další), které již měly určité odlišnosti od „originálu Intelu“.
 |
1993
Byl vydán první superskalární procesor x86, tedy schopný provést více než jednu instrukci za takt - Pentium (kódové označení P5). Toho bylo dosaženo přítomností dvou nezávislých paralelních dopravníků. První procesory měly frekvenci 60 a 66 MHz a přijímaly 64bitovou datovou sběrnici. Poprvé byla mezipaměť první úrovně rozdělena na dvě části: zvlášť pro instrukce a data. Ale jednou z nejvýznamnějších inovací byla zcela přepracovaná jednotka s plovoucí desetinnou čárkou (FPU). Ve skutečnosti nikdy předtím na platformě x86 nebyl tak výkonný FPU a teprve mnoho let po vydání Intel Pentium byli konkurenti schopni dosáhnout jeho výkonnostní úrovně. Do procesoru byl také poprvé zahrnut blok predikce větví, který od té doby inženýři aktivně vyvíjeli.
Sečteno a podtrženo: v každém programu existuje mnoho podmíněných přechodů, kdy v závislosti na podmínce musí provedení programu jít tak či onak. Do potrubí lze umístit pouze jednu z několika přechodových větví, a pokud se ukáže, že je vyplněna kódem nesprávné větve, je třeba ji vyčistit a znovu naplnit na několik cyklů (v závislosti na počtu fází potrubí ). K vyřešení tohoto problému se používají mechanismy predikce větví. Procesor obsahoval 3,1 milionu tranzistorů a byl vyroben 0,8mikronovým procesem. Všechny tyto změny umožnily zvednout výkon nového procesoru do nedosažitelné výše. Ve skutečnosti byla optimalizace kódu „pro procesor“ zpočátku vzácná a vyžadovala použití speciálních kompilátorů. A nejnovější procesor musel dlouhou dobu vykonávat programy určené pro procesory rodiny 486 a 386.
Ve stejném roce se na jádře P54 objevila druhá generace Pentia, ve které byly odstraněny všechny nedostatky P5. Při výrobě byly použity nové technologické postupy 0,6 a později 0,35 µm. Až do roku 1996 pokrýval nový procesor taktovací frekvence od 75 do 200 MHz.
První Pentium sehrálo důležitou roli při přechodu na nové úrovně výkonu osobních počítačů, dalo impuls a stanovilo měřítka pro vývoj budoucnosti. Ale s velkým skokem ve výkonu to nepřineslo žádné zásadní změny v architektuře x86.
1994
Uvedení procesorů Intel 486™DX4, AMD Am486DX4 a Cyrix 4x86 pokračovalo v řadě 486 a ve využití násobení frekvence datové sběrnice. Procesory měly ztrojnásobení frekvence. Procesory Intel DX4 běžely na 75 a 100 MHz, zatímco AMD Am486DX4 dosáhl 120 MHz. Systém správy napájení se stal široce používaným v procesorech. Žádné další zásadní rozdíly od 486DX2 nebyly nalezeny.
1995
Oznámeno Pentium Pro (jádro P6). Nová sběrnice procesoru, tři nezávislé pipeline, optimalizace pro 32bitový kód, od 256 Kb do 1 Mb L2-cache integrovaná do procesoru a běžící na frekvenci jádra, vylepšený mechanismus predikce větví - podle počtu inovací nový procesor téměř překonal rekordy, které dříve vytvořilo Intel Pentium.
 |
Procesor byl umístěn pro použití v serverech a měl velmi vysokou cenu. Nejpozoruhodnější je, že výpočetní jádro Pentium Pro ve skutečnosti nebylo x86 jádrem. Strojové kódy x86 přicházející do CPU byly interně dekódovány do mikrokódu podobného RISC a byl to tento mikrokód, který spouštělo jádro procesoru. Instrukční sada CISC, stejně jako instrukční sada procesoru x86, implikovala proměnnou délku instrukcí, což ztěžovalo nalezení každé jednotlivé instrukce v proudu, a proto způsobovalo potíže při vývoji programu. Příkazy CISC jsou složité a složité. Instrukce RISC jsou zjednodušené, krátké a vyžadují mnohem méně času na provedení instrukce s pevnou délkou. Použití instrukcí RISC umožňuje výrazně zvýšit paralelizaci výpočtů procesoru, to znamená použít více potrubí a v důsledku toho snížit dobu provádění instrukcí. Jádro P6 tvořilo základ dalších tří procesorů Intel – Pentium II, Celeron, Pentium III.
Letos se také odehrála významná událost – AMD koupila NexGen, který měl v té době pokročilý architektonický vývoj. Sloučení dvou inženýrských týmů by později přineslo světu procesory x86 s odlišnou mikroarchitekturou od Intelu a odstartovalo nové kolo tvrdé konkurence.
Nový procesor MediaGX společnosti Cyrix byl poprvé představen na Microprocessor Forum a obsahuje integrovaný paměťový řadič, grafický akcelerátor, rozhraní sběrnice PCI a výkon podobný Pentiu. Byl to první pokus o takto hustou integraci zařízení.
1996
Objevil se nový procesor AMD K5 se superskalárním jádrem RISC. RISC jádro s jeho instrukční sadou (ROP instrukce) je však před softwarem a koncovým uživatelem skryto a x86 instrukce jsou převedeny na RISC instrukce. Inženýři AMD použili unikátní řešení – instrukce x86 jsou částečně konvertovány, zatímco jsou umístěny v mezipaměti procesoru. V ideálním případě může procesor K5 provést až čtyři x86 instrukce za cyklus, ale v praxi jsou v průměru zpracovány pouze 2 instrukce za cyklus.
 |
Kromě toho může výkon zlepšit tradiční přeskupování procesorů RISC, přejmenování registrů a další „triky“. Procesor K5 byl duchovním dítětem společného týmu inženýrů AMD a NexGen. Maximální takt nikdy nepřesáhl 116 MHz, ale výkon K5 byl vyšší než u procesorů Pentium se stejným taktem. Pro marketingové účely bylo proto poprvé v praxi označování CPU použito hodnocení výkonu (Performance Rating), které bylo jednoznačně proti taktovací frekvenci Pentií shodné s výkonem. Procesor mu ale stále nemohl dostatečně konkurovat, protože Pentium již dosáhlo frekvence 166 MHz.
Ve stejném roce došlo k vydání Intel Pentium MMX. Hlavní inovací procesoru P55C jsou dodatečné instrukce MXX k instrukční sadě, která se od vzniku procesorů třetí generace téměř nezměnila. Technologie MMX je využití multimediálních příkazů. Speciální sada instrukcí SIMD (Single Instruction - Multiple Data - one command - multiple data) zlepšuje výkon při provádění vektorových, cyklických příkazů a zpracování velkých datových polí - při aplikaci grafických filtrů a různých speciálních efektů.
 |
Ve skutečnosti se jedná o 57 nových instrukcí navržených pro urychlení zpracování videa a zvuku. Zbývající změny v jádře spočívaly v typickém zvýšení velikosti mezipaměti, vylepšených schématech fungování mezipaměti a dalších bloků. Procesor byl vyroben pomocí 0,35mikronového procesu, 4,5 milionu tranzistorů. Maximální frekvence je 233 MHz.
Začala výroba superskalárních procesorů Cyrix 6x86 na jádře M1, což byl vlastně procesor 5. generace, jehož poznávacím znakem byly „hluboké“ pipelines a použití klasických x86 instrukcí bez dalších instrukčních sad.
Na konci roku, když Intel vyvíjel Pentium II, AMD se opět ohlásilo vydáním šesté generace procesoru K6. AMD-K6 je založeno na jádře vyvinutém inženýry NexGen pro procesor Nx686 a výrazně vylepšeném AMD. Stejně jako K5 ani jádro K6 nefungovalo na instrukcích x86, ale na mikrokódu podobném RISC. Procesor podporoval MMX příkazy a 100 MHz systémovou sběrnici a měl zvýšenou L1 cache na 64 KB. Brzy se ukázalo, že PentiumII bude pro K6 příliš tvrdé.
od roku 1997 dodnes...
V roce 1997 se již formovaly směry technického vývoje architektury x86 předních výrobců. Další etapu vývoje x86 procesorů lze označit za konfrontaci architektur, která trvá dodnes. Ušli dlouhou cestu: Intel, který dobyl 90 % trhu, AMD s ním tvrdošíjně bojuje, mnohonásobně ztrácí na výrobní kapacitě, a Cyrix, který později koupí VIA, a pak úplně, neschopný odolat konkurence, upadne do neznáma. Ostatní výrobci nebudou schopni adekvátně konkurovat a budou nuceni hledat jiné mezery na trhu. Přechod od CISC k mikroinstrukcím podobným RISC se plánuje v menší míře u Intelu, ve větší u AMD. Kromě toho jsou příkazy CISC stále přijímány na vstupu a výstupu procesorů x86. A proč vlastně začali do procesorů x86 s nativní architekturou CISC zavádět vnitřní architekturu RISC, která umožňuje prohloubení paralelizace provádění instrukcí? Ano, jen z architektury x86 CISC v minulosti čtvrté generace vše bylo vymačkané a neexistovaly žádné způsoby, jak zlepšit výkon na úrovni základních instrukčních sad.
 |
Od té doby nedošlo k žádným zásadně novým změnám a průlomům ve vývoji architektury, ačkoli moderní procesory jsou stokrát rychlejší, například 386. Inženýři vylepšují a vylepšují stávající mikroarchitektury jader a ty nové jsou jen přepracované staré. Všechna vylepšení a pokusy o zlepšení výkonu spočívají v optimalizaci stávajících řešení, zavádění různých oprav a „berliček“ pro slabé FPU, kanály a mezipaměti. Otřepaným, ale stále účinným prostředkem je neustálé navyšování množství cache paměti a frekvence sběrnice FSB. Moderní procesory mít až 2 MB vyrovnávací paměti běžící na frekvenci jádra a frekvencích systémové sběrnice dosáhnout 800 MHz a poté pomocí násobiče, protože skutečná generovaná frekvence je pouze 200 MHz. Za posledních 7 let byly do procesorů x86 zavedeny následující „inovace podpory“: mezipaměť se konečně přesunula na procesorový čip a přenesla se na frekvenci jádra, byly zavedeny jednotky pro predikci větví, které jsou neustále vylepšovány jako kompenzace za zvýšení délky (počet fází) pipeline, mechanismus pro dynamickou změnu pořadí provádění instrukcí, který snižuje počet cyklů nečinnosti, mechanismus prefetch dat pro racionálnější využití cache paměti. Další sady příkazů se množí: SSE, SSE2, SSE3, 3DNow!, 3DNow Professional. Pokud by MMX mohl být stále nazýván dodatečnou sadou instrukcí x86 s protažením, pak jsou všechny následující sady nepravděpodobné, protože k příkazům x86 není co přidat. Smyslem vzhledu těchto sad je pokusit se co nejméně používat jednotku s plovoucí desetinnou čárkou (FPU) v podobě, ve které existuje, protože díky vysokému výkonu se vyznačuje nízkou přizpůsobivostí pro vysoce přesné výpočty, vrtkavost vnitřní architektury a její nepředvídatelnost, která programátorům ztěžuje život. To znamená, že byla zavedena specializovaná výpočtová jednotka zaměřená nikoli na výpočty obecně, ale na reálné, často se vyskytující úlohy, které se navrhují provádět s obcházením klasického FPU.
 |
Tak nějak to vypadá spíš na řešení důsledků integrace matematického koprocesoru do CPU v roce 1989. V každém případě, když se nad tím zamyslíte a spočítáte, pak většinu času tráví procesor „sám na sobě“ – na všemožných transformacích, predikcích a mnoho dalšího, a ne na provádění programového kódu.
Při pohledu zpět je jasné, že ne vše šlo hladce. Zavedení multiplikačního faktoru a z toho vyplývající asynchronie, stejně jako zvýšení počtu stupňů potrubí, to všechno jsou dvousečné meče. Na jednu stranu nám to umožnilo zvýšit takt procesoru na téměř 4 GHz (a to není limit), na stranu druhou jsme dostali úzké hrdlo v podobě FSB sběrnice a problém s podmíněnými skoky. Ale všechno má svůj čas a pak to byla zjevně rozumná rozhodnutí, protože vždy existuje velmi zlý ekonomický faktor.
Nutno podotknout, že v oblasti výroby polovodičů bylo v posledních letech dosaženo skutečně brilantních úspěchů. 90nm technologický proces výroby procesorů x86 je již zvládnutý, což umožňuje dosáhnout téměř mikrovlnného rozsahu hodinové frekvence a počet tranzistorů v krystalu dosahuje 170 milionů (Pentium 4 EE).
Dříve jsme si mysleli, že procesor je hlavním zařízením v PC a že je to on, kdo udává tón pro globální výpočetní techniku. Ale vítězný pochod architektury x86, trvající více než čtvrt století, nezačal konkrétně s procesorem, ale se zařízením koncového uživatele jako celkem – IBM PC. V té době ani v IBM netušili, jaká skvělá budoucnost tento počítač čeká, a aniž by projektu přikládali jakýkoli význam, otevřeli jej všem. Je to otevřenost konceptu, úspěch softwaru a MS DOS, které vděčí za úspěch IBM PC. A procesor v něm mohl mít jakoukoli architekturu, ale náhodou si IBM vybralo i8088 a i8086 a pak se všechno začalo točit, točit ... Ale procesor x86 neskončil u tak univerzální kalkulačky pro všechny příležitosti nebo „chytré“ zařízení, všudypřítomné a schopné dělat vše tak, jak se o něm dříve snilo. A „zákon“ Gordona Moora (každé 2 roky se počet tranzistorů v procesorovém čipu zdvojnásobí) se stal zákonem pouze pro Intel, který jej postavil do popředí své marketingové politiky a zjevně je pro ni nepohodlné toto slovo odmítnout .
 |
Dnes již můžeme s klidem říci, že architektura x86 se dostala do slepé uličky. Jeho přínos k popularizaci počítače jako zařízení je obrovský a nikdo se s tím nepáře. Nicméně nemůžete být aktuální věčně. Z kdysi mladého a silného hřebce se stal starý kůň, kterého nadále zapřahají do vozu. Apetit uživatelů je neukojitelný a architektura x86 je brzy nebude schopna uspokojit. Přechod je samozřejmě spojen s titánským úsilím vzhledem k tomu, že mnohamilionová globální flotila PC ve své téměř naprosté většině používá procesory architektury x86 a hlavně software pro kód x86. Nelze změnit vše za jeden den, trvá to roky. Vývoj 64bitových procesorů a programů ale nabírá na obrátkách záviděníhodnou rychlostí, Intel představil Itanium2 a AMD už téměř rok vydává svůj Athlon 64, které architekturu x86 vůbec nemají, přestože jsou plně je s ním kompatibilní a může stále spouštět všechny staré programy. Dá se tedy říci, že AMD Athlon 64 znamenal začátek odklonu od x86 architektury a otevřel tak přechodné období.
Jak vidíte, tvrzení, že procesor je nejrychleji rostoucí PC komponentou, zdaleka nejsou nepodložená. Představte si, jakými procesory budou vybaveny počítače našich dětí. Mysli děsivě!
 |
V Odnoklassniki