V súčasnosti existujú dve najpopulárnejšie architektúry procesorov. Ide o x86, ktorý bol vyvinutý už v 80. rokoch a používa sa v osobných počítačoch a ARM, ktorý je modernejší, čo umožňuje procesorom byť menšie a ekonomickejšie. Používa sa vo väčšine mobilných zariadení alebo tabletov.
Obe architektúry majú svoje pre a proti, ako aj oblasti použitia, no nájdu sa aj spoločné črty. Mnoho odborníkov hovorí, že ARM je budúcnosť, ale stále má niektoré nevýhody, ktoré x86 nemá. V našom dnešnom článku sa pozrieme na to, ako sa architektúra ramena líši od x86. Pozrime sa na základné rozdiely medzi ARM a x86 a tiež sa pokúsme určiť, čo je lepšie.
čo je architektúra?
Procesor je hlavnou súčasťou každého výpočtového zariadenia, či už ide o smartfón alebo počítač. Jeho výkon určuje, ako rýchlo bude zariadenie fungovať a ako dlho môže bežať na batériu. Jednoducho povedané, architektúra procesora je súbor inštrukcií, ktoré možno použiť na zostavenie programov a ktoré sú implementované v hardvéri pomocou špecifických kombinácií tranzistorov procesora. Umožňujú programom interagovať s hardvérom a určujú, ako sa budú dáta prenášať a čítať z pamäte.
Zapnuté tento moment Existujú dva typy architektúr: CISC (Complex Instruction Set Computing) a RISC (Reduced Instruction Set Computing). Prvý predpokladá, že procesor bude implementovať inštrukcie pre všetky príležitosti, druhý, RISC, kladie vývojárom za úlohu vytvoriť procesor so súborom minimálnych inštrukcií potrebných na prevádzku. Inštrukcie RISC sú menšie a jednoduchšie.

architektúra x86
Architektúra procesora x86 bola vyvinutá v roku 1978 a prvýkrát sa objavila v procesoroch Intel a je typu CISC. Jeho názov je prevzatý z modelu prvého procesora s touto architektúrou – Intel 8086. Postupom času sa pre nedostatok najlepšia alternatíva Túto architektúru začali podporovať aj ďalší výrobcovia procesorov, napríklad AMD. Teraz je to štandard pre stolné počítače, notebooky, netbooky, servery a iné podobné zariadenia. Ale niekedy sa v tabletoch používajú procesory x86, to je celkom bežná prax.
Prvý procesor Intel 8086 mal 16-bitovú kapacitu, potom v roku 2000 vyšiel procesor s 32-bitovou architektúrou a ešte neskôr sa objavila 64-bitová architektúra. Podrobne sme to rozobrali v samostatnom článku. Počas tejto doby sa architektúra veľmi vyvinula, boli pridané nové sady inštrukcií a rozšírení, ktoré môžu výrazne zvýšiť výkon procesora.
x86 má niekoľko významných nevýhod. Po prvé, ide o zložitosť príkazov, ich zložitosť, ktorá vznikla v dôsledku dlhej histórie vývoja. Po druhé, takéto procesory z tohto dôvodu spotrebúvajú príliš veľa energie a generujú veľa tepla. Inžinieri x86 sa spočiatku vydali cestou získania maximálneho výkonu a rýchlosť si vyžaduje zdroje. Predtým, než sa pozrieme na rozdiely medzi arm x86, povedzme si niečo o architektúre ARM.
architektúra ARM
Táto architektúra bola predstavená o niečo neskôr po x86 - v roku 1985. Vyvinula ju slávna britská spoločnosť Acorn, vtedy sa táto architektúra nazývala Arcon Risk Machine a patrila k typu RISC, no potom bola vydaná jej vylepšená verzia Advanted RISC Machine, ktorá je dnes známa ako ARM.
Pri vývoji tejto architektúry si inžinieri dali za cieľ odstrániť všetky nedostatky x86 a vytvoriť úplne novú a najefektívnejšiu architektúru. Čipy ARM získali minimálnu spotrebu energie a nízku cenu, ale mali nízky výkon v porovnaní s x86, takže spočiatku si na osobných počítačoch nezískali veľkú popularitu.
Na rozdiel od x86 sa vývojári spočiatku snažili získať minimálne náklady na zdrojoch, majú menej procesorových inštrukcií, menej tranzistorov, ale tiež, podľa toho, menej všelijakých pridané vlastnosti. Ale výkon procesorov ARM sa v posledných rokoch zlepšuje. Vzhľadom na to a nízku spotrebu energie sa začali veľmi široko používať mobilné zariadenia, ako sú tablety a smartfóny.
Rozdiely medzi ARM a x86
A teraz, keď sme sa pozreli na históriu vývoja týchto architektúr a ich zásadné rozdiely, urobme podrobné porovnanie ARM a x86 na základe ich rôznych charakteristík, aby sme určili, ktorá je lepšia a presnejšie pochopili, aké sú ich rozdiely.
Výroba
Produkcia x86 vs arm je odlišná. Procesory x86 vyrábajú iba dve spoločnosti: Intel a AMD. Spočiatku to bola jedna spoločnosť, ale to je úplne iný príbeh. Iba tieto spoločnosti majú právo vyrábať takéto procesory, čo znamená, že iba oni budú kontrolovať smerovanie rozvoja infraštruktúry.
ARM funguje úplne inak. Spoločnosť, ktorá vyvíja ARM, nič nevydáva. Jednoducho vydajú povolenie na vývoj procesorov tejto architektúry a výrobcovia si môžu robiť, čo potrebujú, napríklad vyrábať špecifické čipy s modulmi, ktoré potrebujú.
Počet pokynov
Toto sú hlavné rozdiely medzi architektúrou arm a x86. Procesory x86 sa rýchlo vyvíjali ako výkonnejšie a produktívnejšie. Dodali vývojári veľké množstvo inštrukcie procesora a tu nie je len základná sada, ale pomerne veľa príkazov, od ktorých by sa dalo upustiť. Spočiatku sa to robilo s cieľom znížiť množstvo pamäte obsadenej programami na disku. Taktiež bolo vyvinutých mnoho možností ochrany a virtualizácie, optimalizácie a mnoho ďalšieho. To všetko si vyžaduje dodatočné tranzistory a energiu.
ARM je jednoduchší. Inštrukcií procesora je tu oveľa menej, iba tých, ktoré operačný systém potrebuje a sú skutočne využívané. Ak porovnáme x86, tak tam je použitých len 30% všetkých možných inštrukcií. Učia sa ľahšie, ak sa rozhodnete písať programy ručne, a tiež vyžadujú menej tranzistorov na implementáciu.
Spotreba energie
Ďalší záver vyplýva z predchádzajúceho odseku. Čím viac tranzistorov je na doske, tým väčšia je jej plocha a spotreba energie a platí to aj naopak.
Procesory x86 spotrebujú oveľa viac energie ako ARM. Spotrebu energie ale ovplyvňuje aj veľkosť samotného tranzistora. Napríklad procesor Intel i7 spotrebuje 47 wattov a akýkoľvek procesor smartfónu ARM spotrebuje maximálne 3 watty. Predtým sa vyrábali dosky s veľkosťou jedného prvku 80 nm, potom Intel dosiahol zmenšenie na 22 nm a tento rok sa vedcom podarilo vytvoriť dosku s veľkosťou prvku 1 nanometer. To výrazne zníži spotrebu energie bez straty výkonu.

V posledných rokoch sa spotreba energie x86 procesorov veľmi znížila, napríklad nové procesory Intel Haswell môže vydržať dlhšie na batériu. Teraz sa rozdiel medzi arm vs x86 postupne stráca.
Odvod tepla
Počet tranzistorov ovplyvňuje ďalší parameter - tvorbu tepla. Moderné zariadenia nedokáže premeniť všetku energiu na účinné pôsobenie, časť z nej sa rozptýli vo forme tepla. Účinnosť dosiek je rovnaká, čo znamená, že čím menej tranzistorov a čím menšia je ich veľkosť, tým menej tepla bude procesor generovať. Tu už nevyvstáva otázka, či ARM alebo x86 bude generovať menej tepla.
Výkon procesora
ARM nebol pôvodne navrhnutý pre maximálny výkon, v tomto x86 exceluje. Čiastočne je to spôsobené menším počtom tranzistorov. V poslednej dobe sa však zvyšuje výkon procesorov ARM a už sa dajú naplno využiť v notebookoch alebo serveroch.
závery
V tomto článku sme sa pozreli na to, ako sa ARM líši od x86. Rozdiely sú dosť vážne. V poslednej dobe sa však hranica medzi oboma architektúrami stiera. Procesory ARM sú čoraz produktívnejšie a rýchlejšie a procesory x86 vďaka zmenšeniu konštrukčného prvku dosky začínajú spotrebovávať menej energie a generovať menej tepla. Procesory ARM už nájdete na serveroch a notebookoch a x86 na tabletoch a smartfónoch.
Čo si myslíte o týchto x86 a ARM? Aká technológia je podľa vás budúcnosť? Napíšte do komentárov! Mimochodom, .
Na záver videa o vývoji architektúry ARM:
Hlavné črty architektúry
SSE4 pozostáva z 54 inštrukcií, z ktorých 47 je klasifikovaných ako SSE4.1 (nachádzajú sa iba v procesoroch Penryn). Kompletná inštrukčná sada (SSE4.1 a SSE4.2, t.j. 47 + zvyšných 7 inštrukcií) je dostupná v procesoroch Nehalem. Žiadna z inštrukcií SSE4 nefunguje so 64-bitovými registrami mmx, iba so 128-bitovými xmm0-15. Neboli vydané žiadne 32-bitové procesory s SSE4.
Pridané inštrukcie, ktoré zrýchľujú kompenzáciu pohybu vo video kodekoch, rýchle čítanie z pamäte USWC a mnoho inštrukcií na zjednodušenie vektorizácie programov kompilátormi. Okrem toho SSE4.2 pridal inštrukcie na spracovanie reťazcov 8/16 bitových znakov, výpočet CRC32, popcnt. Prvýkrát v SSE4 bol register xmm0 použitý ako implicitný argument pre niektoré inštrukcie.
Nové inštrukcie SSE4.1 zahŕňajú akceleráciu videa, vektorové primitívy, vkladanie/extrakciu, vektorové skalárne násobenie, miešanie, kontrolu bitov, zaokrúhľovanie a čítanie WC pamäte.
Nové inštrukcie SSE4.2 zahŕňajú spracovanie reťazcov, počítanie CRC32, jednobitové počítanie populácie a prácu s vektorovými primitívami.
SSE5
Nové rozšírenie x86 inštrukcií od AMD s názvom SSE5. Túto úplne novú sadu inštrukcií SSE, ktorú vytvorili špecialisti AMD, budú od roku 2009 podporovať sľubné spoločnosti zaoberajúce sa procesormi.
SSE5 prináša do klasickej x86 architektúry niektoré funkcie, ktoré boli predtým dostupné výhradne v RISC procesoroch. Inštrukčná sada SSE5 definuje 47 nových základných inštrukcií určených na zrýchlenie jednovláknových výpočtov zvýšením hustoty spracovávaných dát.
Medzi novými návodmi vynikajú dve hlavné skupiny. Prvý obsahuje pokyny, ktoré zhromažďujú výsledky násobenia. Tieto typy inštrukcií môžu byť užitočné pri organizovaní iteračných výpočtových procesov pri vykresľovaní obrázkov alebo vytváraní 3D zvukových efektov. Do druhej skupiny nových inštrukcií patria inštrukcie, ktoré fungujú na dvoch registroch a výsledok ukladajú do tretieho. Táto inovácia by mohla vývojárom umožniť vyhnúť sa zbytočným prenosom údajov medzi registrami vo výpočtových algoritmoch. SSE5 obsahuje aj niekoľko nových inštrukcií na porovnávanie vektorov, na preskupovanie a presúvanie údajov, ako aj na zmenu presnosti a zaokrúhľovania.
AMD vidí výpočtové úlohy, spracovanie multimediálneho obsahu a šifrovacie nástroje ako hlavné aplikácie pre SSE5. Očakáva sa, že vo výpočtových aplikáciách, ktoré používajú maticové operácie, môže použitie SSE5 poskytnúť 30% zvýšenie výkonu. Multimediálne úlohy, ktoré vyžadujú výkon diskrétnej kosínusovej transformácie, môžu ťažiť z 20 % zrýchlenia. A šifrovacie algoritmy vďaka SSE5 môžu dosiahnuť päťnásobné zvýšenie rýchlosti spracovania dát.
AVX
Ďalšia sada rozšírení je od spoločnosti Intel. Podporované je spracovanie čísel s pohyblivou rádovou čiarkou zabalených do 256-bitových „slov“. Pre nich je zavedená podpora rovnakých príkazov ako v rodine SSE. 128-bitové registre SSE XMM0 - XMM15 sa rozšíria na 256-bitové YMM0-YMM15
Rozšírenia procesora Intel Post 32nm sú novou sadou inštrukcií Intel, ktoré vám umožňujú konvertovať čísla s polovičnou presnosťou na čísla s jednoduchou a dvojitou presnosťou, získavať skutočné náhodné čísla v hardvéri a pristupovať k registrom FS/GS.
AVX2
Ďalší vývoj AVX. Inštrukcie SSE integer začnú pracovať s 256-bitovými registrami AVX.
AES
Rozšírenie inštrukčnej sady AES – mikroprocesorová implementácia šifrovania AES.
3DN teraz!
Súbor inštrukcií na spracovanie toku reálnych čísel s jednoduchou presnosťou. Podporované procesormi AMD od K6-2. Nepodporované procesormi Intel.
Pokyny 3DNow! použite registre MMX ako operandy (dve jednotlivé presné čísla sú umiestnené v jednom registri), takže na rozdiel od SSE nie je potrebné pri prepínaní úloh samostatne ukladať kontext 3DNow!.
64-bitový režim
Superskalar znamená, že procesor môže vykonať viac ako jednu operáciu v jednom hodinovom cykle. Superpipelining znamená, že procesor má viacero výpočtových potrubí. Pentium má dva z nich, čo mu umožňuje pri rovnakých frekvenciách byť v ideálnom prípade dvakrát tak produktívnejší ako 486, pričom vykoná 2 inštrukcie na takt.
Vlastnosťou procesora Pentium bola navyše na tú dobu úplne prepracovaná a veľmi výkonná FPU jednotka, ktorej výkon bol až do konca 90. rokov pre konkurenciu nedosiahnuteľný.
Pentium OverDrive
K jadru Pentium II bol navyše pridaný blok MMX.
Celeron
Prvý zástupca tejto rodiny bol založený na architektúre Pentium II, išlo o cartridge s plošným spojom, na ktorom bolo namontované jadro, cache druhej úrovne a cache tag. Namontované v slote 2.
Moderné Xeony sú založené na architektúre Core 2/Core i7.
procesory AMD
Am8086 / Am8088 / Am186 / Am286 / Am386 / Am486V podstate nové procesor AMD(apríl 1997), založený na jadre zakúpenom od NexGen. Tento procesor mal dizajn piatej generácie, ale patril do šiestej generácie a bol umiestnený ako konkurent Pentia II. Zahŕňa blok MMX a mierne prepracovaný blok FPU. Tieto bloky však stále fungovali o 15-20% pomalšie ako bloky s podobnými frekvenciami procesory Intel. Procesor mal 64 KB L1 cache.
Všeobecne platí, že porovnateľný výkon s Pentiom II, kompatibilita so staršími základnými doskami, skoršie uvedenie na trh (AMD predstavilo K6 o mesiac skôr ako Intel predstavil P-II) a nižšia cena ho urobili pomerne populárnym, ale výrobné problémy AMD výrazne pokazili reputáciu. tohto procesora.
K6-2Ďalší vývoj jadra K6. Tieto procesory pridali podporu pre špecializovaný 3DNow! . Skutočný výkon sa však ukázal byť výrazne nižší ako u podobne taktovaného Pentia II (bolo to spôsobené tým, že nárast výkonu so zvyšujúcou sa frekvenciou v P-II bol vyšší kvôli vnútornej vyrovnávacej pamäti) a K6-2 mohla konkurovať iba Celeronom. Procesor mal 64 KB L1 cache.
K6-IIITechnologicky úspešnejší ako K6-2, pokus o vytvorenie analógu Pentia III. Marketingový úspech to však nebol. Vyznačuje sa prítomnosťou 64 KB vyrovnávacej pamäte prvej úrovne a 256 KB vyrovnávacej pamäte druhej úrovne v jadre, čo mu umožnilo prekonať Intel Celeron pri rovnakej frekvencii hodín a nebolo výrazne horšie ako skoré Pentium III. .
K6-III+Analógový K6-III s technológiou úspory energie PowerNow! a viac vysoká frekvencia a rozšírený súbor pokynov. Pôvodne určený pre notebooky. Inštalovaný bol aj do stolných systémov s procesorovou päticou Super 7. Používa sa na inováciu stolových systémov s procesorovou päticou Socket 7 (Len na základných doskách, ktoré napájajú procesor dvoma napájacími napätiami, prvé pre I/O jednotky procesora a druhé pre jadro procesora. Nie všetci výrobcovia poskytovali duálne napájanie na prvé modely ich základných dosiek so socketom Socket 7).
Analogicky ako K6-III+ s vyrovnávacou pamäťou druhej úrovne zníženou na 128 KB.
AthlonVeľmi vydarený procesor, vďaka ktorému si AMD dokázalo opäť získať takmer stratené pozície na trhu mikroprocesorov. Vyrovnávacia pamäť prvej úrovne - 128 KB. Spočiatku sa procesor vyrábal v kazete s vyrovnávacou pamäťou druhej úrovne (512 KB) umiestnenou na doske a inštalovanou v slote A (ktorý je mechanicky, ale nie je elektricky kompatibilný so slotom 1 od Intelu). Potom som prešiel na Socket A a v jadre som mal 256 KB vyrovnávacej pamäte druhej úrovne. Pokiaľ ide o výkon - približný analóg Pentium III.
DuronOrezaná verzia Athlonu, ktorá sa od svojho rodiča líši veľkosťou vyrovnávacej pamäte druhej úrovne (iba 64 KB, ale integrovaná do čipu a pracujúca na frekvencii jadra).
Konkurent generáciám Celeron Pentium III / Pentium 4. Výkon je výrazne vyšší ako u podobných Celeronov a pri vykonávaní mnohých úloh sa vyrovná Pentiu III.
Athlon XPPokračujúci vývoj architektúry Athlonu. Výkonovo je na tom podobne ako Pentium 4. Oproti bežnému Athlonu pribudla podpora inštrukcií SSE.
SempronLacnejšia (v dôsledku zníženej vyrovnávacej pamäte druhej úrovne) verzia procesorov Athlon XP a Athlon 64.
Prvé modely Sempron boli preznačené čipmi Athlon XP na jadrách Thoroughbred a Thorton, ktoré mali 256 KB vyrovnávacej pamäte druhej úrovne a bežali na zbernici 166 (333 DDR). Neskôr sa pod značkou Sempron vyrábali (a vyrábajú) odizolované verzie Athlonu 64/Athlon II, ktoré boli konkurentmi Intel Celeron. Všetky Semprony majú zníženú vyrovnávaciu pamäť úrovne 2; mladšie modely Socket 754 mali zablokované Cool&quiet a x86-64; Modely Socket 939 mali uzamknutý dvojkanálový pamäťový režim.
OpteronPrvý procesor podporujúci architektúru x86-64.
Athlon 64Prvý neserverový procesor podporujúci architektúru x86-64.
Athlon 64 X2Pokračovanie architektúry Athlon 64 má 2 výpočtové jadrá.
Athlon FX
Mal povesť „najviac rýchly procesor na hračky." je v skutočnosti serverový procesor Opteron 1xx na stolových zásuvkách bez podpory registrovanej pamäte. Vyrábané v malých sériách. Stojí podstatne viac ako jeho „masové“ náprotivky.
PhenomĎalší vývoj architektúry Athlon 64 je dostupný vo verziách s dvomi (Athlon 64 X2 Kuma), tromi (Phenom X3 Toliman) a štyrmi (Phenom X4 Agena) jadrami.
Fenom IIProcesory VIA
Cyrix III/VIA C3Prvý procesor uvedený na trh pod značkou VIA. Vydané s rôznymi jadrami od rôznych vývojových tímov. Socket 370 konektor.
Prvé vydanie je založené na jadre Joshua, ktoré VIA získala spolu s vývojovým tímom Cyrix.
Druhé vydanie je s jadrom Samuel, vyvinutým na základe nikdy nevydaného IDT WinChip -3. Vyznačoval sa absenciou vyrovnávacej pamäte druhej úrovne, a teda extrémne nízkou úrovňou výkonu.
Tretie vydanie je s jadrom Samuel-2, vylepšenou verziou predchádzajúceho jadra, vybaveného vyrovnávacou pamäťou druhej úrovne. Procesor bol vyrobený tenšou technológiou a mal zníženú spotrebu energie. Po vydaní tohto jadra značka „VIA Cyrix III“ konečne ustúpila „VIA C3“.
Štvrté vydanie je s jadrom Ezra. Existoval aj variant Ezra-T, prispôsobený pre prácu na zbernici určenej pre procesory Intel s jadrom Tualatin. Ďalší vývoj v smere šetrenia energiou.
Piate vydanie je s jadrom Nehemiah (C5P). Toto jadro konečne dostalo plnohodnotný koprocesor, podporu inštrukcií či .
Procesory založené na jadre V33 nemali režim emulácie 8080, ale podporovali ho pomocou dvoch dodatočné pokyny, rozšírený režim adresovania.
Procesory NexGen
Nx586V marci 1994 bol predstavený procesor NexGen Nx586. Bol umiestnený ako konkurent Pentia, ale spočiatku nemal vstavaný koprocesor. Používanie vlastnej zbernice so sebou prinášalo potrebu použiť vlastné čipsety, NxVL (VESA Local Bus) a NxPCI 820C500 (PCI) a nekompatibilnú päticu procesora. Čipové sady boli vyvinuté spoločne s VLSI a Fujitsu. Nx586 bol superskalárny procesor a mohol vykonávať dve inštrukcie za cyklus. Cache L1 bola oddelená (16 KB pre inštrukcie + 16 KB pre dáta). Radič vyrovnávacej pamäte L2 bol integrovaný do procesora, pričom samotná vyrovnávacia pamäť bola umiestnená na základná doska. Rovnako ako Pentium Pro, aj Nx586 bol vo vnútri RISC procesor. Chýbajúca podpora inštrukcií CPUID v skorých modifikáciách tohto procesora viedla k tomu, že bol softvérovo definovaný ako rýchly 386 procesor. Bolo to spôsobené aj tým, že Windows 95 odmietal inštalovať na počítače s takýmito procesormi. Na vyriešenie tohto problému bola použitá špeciálna utilita (IDON.COM), ktorá prezentovala Nx586 pre Windows ako CPU triedy 586. Nx586 bol vyrobený v závodoch IBM.
Koprocesor Nx587 FPU bol tiež vyvinutý a továrensky namontovaný na hornú časť matrice procesora. Takéto „zostavy“ boli označené Nx586Pf. Pri označovaní výkonu Nx586 sa použilo hodnotenie P - od PR75 (70 MHz) po PR120 (111 MHz).
Ďalšia generácia procesorov NexGen, ktoré neboli nikdy vydané, ale slúžili ako základ pre AMD K6.
SiS procesory
SiS550Rodina SiS550 SoC je založená na licencovanom jadre Rise mP6 a je dostupná s frekvenciami od 166 do 266 MHz. Najrýchlejšie riešenia zároveň spotrebujú iba 1,8 W. Jadro má tri celočíselné 8-stupňové potrubia. Samostatná vyrovnávacia pamäť L1, 8+8 KB. Vstavaný koprocesor je pipeline. Okrem štandardnej sady portov obsahuje SiS550 128-bitové video jadro UMA AGP 4x, 5.1-kanálový zvuk a podporu 2 inštrukcií s názvom Code Morphing Software. To umožňuje procesoru prispôsobiť sa akejkoľvek sade inštrukcií a zlepšuje energetickú účinnosť, ale výkon takéhoto riešenia je samozrejme nižší ako výkon procesorov s natívnym inštrukčným systémom x86. matematický koprocesor, a varianty s koprocesorom sa mali volať U5D, ale nikdy neboli vydané.
Intel získal súdny príkaz proti predaju zelených CPU v Spojených štátoch s argumentom, že UMC používala mikrokód Intel vo svojich procesoroch bez licencie.
Vyskytli sa aj nejaké problémy so softvérom. Napríklad hra Doom odmietla bežať na tomto procesore bez zmeny konfigurácie a Windows 95 z času na čas zamrzol. Bolo to spôsobené tým, že programy našli v U5S chýbajúci koprocesor a pokusy o prístup k nemu skončili neúspešne.
Procesory vyrábané v ZSSR a Rusku
KR1810VM86BLX IC Design/ICT procesory
Dizajn a inštitút BLX IC počítačová technológia Od roku 2001 Čína vyvíja procesory založené na MIPS s hardvérovým prekladom x86 inštrukcií. Tieto procesory vyrába STMicroelectronics. Uvažuje sa o partnerstve s TSMC.
Godson (Longxin, Loongson, Dragon)
Godson je 32-bitový RISC procesor založený na MIPS. Technológia - 180 nm. Predstavený v roku 2002. Frekvencia - 266 MHz, o rok neskôr - verzia s frekvenciou 500 MHz.
Godson 2
- Godson 2 je 64-bitový RISC procesor založený na MIPS III. 90 nm technológia. Pri rovnakej frekvencii je 10-krát rýchlejší ako jeho predchodca. Predstavené 19. apríla 2005.
- Godson-2E - 500 MHz, 750 MHz, neskôr - 1 GHz. Technológia - 90 nm. 47 miliónov tranzistorov, spotreba - 5...7,5W. Prvý Godson s hardvérovým prekladom x86 príkazov a minie sa naň až 60 % výkonu procesora. Predstavené v novembri 2006.
- Godson 2F - 1,2 GHz, vyrábaný od marca 2007. V porovnaní s predchodcom je deklarovaný 20-30% nárast produktivity.
- Godson 2H - plánované vydanie v roku 2011. Bude vybavený vstavaným video jadrom a pamäťovým radičom a je určený pre spotrebiteľské systémy.
- Godson 3 - 4 jadrá, 65 nm technológia. Spotreba energie je cca 20W.
- Godson 3B - 8 jadier, technológia 65 nm (plánovaný prechod na 28 nm), taktovacia frekvencia do 1 GHz. Plocha kryštálov - 300 mm². Výkon s pohyblivou rádovou čiarkou je 128 GigaFLOPS. Príkon 8-jadrového Godsonu je 3-40 W. Preklad do kódu x86 sa vykonáva pomocou sady 200 inštrukcií, pričom približne 20 % výkonu procesora sa vynakladá na preklad. Procesor má 256-bitovú vektorovú procesorovú jednotku SIMD. Procesor je určený na použitie v serveroch a vstavaných systémoch.
Štruktúra ľubovoľnej inštrukcie je nasledovná:
- Predpony (každá z nich je voliteľná):
- Jednobajtová predpona pre zmenu režimu adresovania AddressSize (hodnota 67h).
- Jednobajtová predpona zmeny segmentu (hodnoty 26h, 2Eh, 36h, 3Eh, 64h a 65h).
- Jednobajtová predpona BranchHint na označenie preferovanej vetvy vetvy (hodnoty 2Eh a 3Eh).
- Dvojbajtová alebo trojbajtová komplexná predpona Vex (prvý bajt má vždy hodnotu C4h pre dvojbajtovú verziu alebo C5h pre trojbajtovú verziu).
- Jednobajtová predpona Lock na zabránenie modifikácii pamäte inými procesormi alebo jadrami (hodnota F0h).
- Jednobajtová predpona OperandsSize na zmenu veľkosti operandu (hodnota 66h).
- Jeden bajt Povinná predpona na objasnenie inštrukcie (hodnoty F2h a F3h).
- Jednobajtová predpona Repeat znamená opakovanie (hodnoty F2h a F3h).
- Jednobajtová štruktúrovaná predpona Rex je potrebná na označenie 64-bitových alebo rozšírených registrov (má hodnoty 40h..4Fh).
- Úniková predpona. Vždy pozostáva aspoň z jedného bajtu 0Fh. Po tomto byte voliteľne nasleduje byte 38h alebo 3Ah. Navrhnuté na objasnenie pokynov.
- Bajty, ktoré presne definujú inštrukciu, sú:
- Bajt operačného kódu (ľubovoľná konštantná hodnota).
- Opcode2 bajt (ľubovoľná konštantná hodnota).
- Params byte (má zložitú štruktúru).
- Byte ModRm sa používa pre operandy v pamäti (má zložitú štruktúru).
- Bajt SIB sa používa aj pre pamäťové operandy a má zložitú štruktúru.
- Údaje zabudované do pokynov (voliteľné):
- Posun alebo adresa v pamäti. Celé číslo so znamienkom veľkosti 8, 16, 32 alebo 64 bitov.
- Prvý alebo jediný okamžitý operand (Immediate). Môže mať veľkosť 8, 16, 32 alebo 64 bitov.
- Druhý bezprostredný operand (Immediate2). Ak je prítomný, má zvyčajne veľkosť 8 bitov.
V zozname vyššie a nižšie sú v prípade technických názvov akceptované názov „iba latinské, arabské číslice“ a znamienko mínus „-“ s podčiarkovníkom „_“ a prípad je CamelCase (akékoľvek slovo začína veľkým písmenom, a potom len malé písmená, aj keď je skratka: „ UTF-8“ → „Utf8“ – všetky slová spolu). Predpony AddressSize, Segment, BranchHint, Lock, OperandsSize a Repeat môžu byť zmiešané. Zostávajúce prvky musia ísť presne v určenom poradí. A môžete vidieť, že bajtové hodnoty niektorých predpôn sú rovnaké. Ich účel a dostupnosť určujú samotné pokyny. Predpony nahradenia segmentov možno použiť s väčšinou inštrukcií, ale predpony BranchHint možno použiť len s inštrukciami podmienenej vetvy. Podobne je to aj s predponami Povinné a Opakovanie – niekde spresňujú pokyny a niekde označujú opakovanie. Predpona OperandSize spolu s povinnými predponami sú tiež klasifikované ako predpony inštrukcií SIMD. Samostatne by sa malo povedať o predpone Vex. Nahrádza predpony Rex, Mandatory, Escape a OperandsSize a zhutňuje ich do seba. Nie je dovolené s ním používať predponu Lock. Samotnú predponu zámku možno pridať, keď je cieľom operand v pamäti.
Prehľadný zoznam všetkých režimov záujmu z hľadiska kódovania pokynov:
- 16-bitový („Real Mode“, reálny režim s adresovaním segmentov).
- 32-bitový („Protected Mode“, chránený režim s modelom s plochou pamäťou).
- 64-bitový („Long Mode“, ako 32-bitový chránený modelom s plochou pamäťou, ale adresy sú už 64-bitové).
V zátvorkách sú anglické názvy režimov zhodné s oficiálnymi. Existujú aj syntetické režimy ako neskutočný (Unreal x86 Mode), ale všetky vychádzajú z týchto troch (v podstate ide o hybridy, ktoré sa líšia len veľkosťou adresy, operandov atď.). Každý z nich používa „natívny“ režim adresovania, ale možno ho zmeniť na alternatívny s predponou OperandsSize. V 16-bitovom režime bude povolený 32-bitový režim adresovania, v 32-bitovom režime - 16-bitový a v 64-bitovom režime - 32-bitový. Ak to však urobíte, adresa sa rozšíri o nuly (ak je menšia) alebo sa jej najvýznamnejšie bity vynulujú (ak je väčšia).
4.6. Vlastnosti architektúry moderných x86 procesorov
4.6.1. Architektúra procesora Intel Pentium(P5/P6)
Procesory rodiny Pentium majú množstvo architektonických a konštrukčných prvkov v porovnaní s predchádzajúcimi modelmi mikroprocesorov Intel. Najcharakteristickejšie z nich sú:
Harvardská architektúra s oddelením toku príkazov a údajov zavedením samostatných blokov vnútornej vyrovnávacej pamäte na ukladanie príkazov a údajov, ako aj zberníc na ich prenos;
Superskalárna architektúra, ktorá zabezpečuje súčasné vykonávanie niekoľkých príkazov v paralelne pracujúcich zariadeniach;
Dynamické vykonávanie príkazov, ktoré implementuje zmenu sekvencie príkazov pomocou rozšíreného súboru registrov (premenovanie registrov) a efektívnej predikcie vetvenia;
Duálna nezávislá zbernica obsahujúca samostatnú zbernicu pre prístup k vyrovnávacej pamäti L2 (bežiaca na frekvencii procesora) a systémovú zbernicu na prístup k pamäti a externých zariadení(beží rýchlosťou hodín základnej dosky).
Hlavné charakteristiky rodiny procesorov Pentium sú nasledovné:
32-bitová vnútorná štruktúra;
Použitie systémovej zbernice s 36 adresovými bitmi a 64 dátovými bitmi;
Samostatná interná vyrovnávacia pamäť L1 pre inštrukcie a dáta s kapacitou 16 KB;
Podporuje zdieľanú L2 inštrukciu a dátovú vyrovnávaciu pamäť s veľkosťou až 2 MB;
Potrubné vykonávanie príkazov;
Predpovedanie smeru vetvenia softvéru s vysokou presnosťou;
Zrýchlené vykonávanie operácií s pohyblivou rádovou čiarkou;
Prioritná kontrola pri prístupe do pamäte;
Podpora implementácie viacprocesorových systémov;
Dostupnosť interných nástrojov, ktoré poskytujú samočinné testovanie, ladenie a monitorovanie výkonu.
Nová mikroarchitektúra Procesory Pentium (ryža. 4.6)a neskôr je založená na metóde superskalárne spracovanie .
Pod superskalarita znamená prítomnosť viac jeden pipeline na spracovanie príkazov (na rozdiel od skalárnej – single-pipeline architektúry).
Obrázok 4.6 – Bloková schéma architektúry Pentium MP
V Pentium MP sú príkazy distribuované cez dva nezávislé vykonávacie kanály (U a V). Dopravník U môže vykonávať ľubovoľnú rodinu príkazov IA-32, vrátane celočíselných príkazov a príkazov s pohyblivou rádovou čiarkou. Dopravník V navrhnuté tak, aby vykonávali jednoduché celočíselné inštrukcie a niektoré inštrukcie s pohyblivou rádovou čiarkou. Príkazy možno posielať do každého z týchto zariadení súčasne, a keď riadiace zariadenie vydá pár príkazov v jednom hodinovom cykle, zložitejší príkaz prejde do potrubia U a menej zložitý prejde do potrubia V.
Takéto párové spracovanie príkazov (párovanie) je však možné len pre obmedzenú podmnožinu celočíselných príkazov. Skutočné aritmetické inštrukcie nemožno spustiť v spojení s celočíselnými inštrukciami. Súčasné vydávanie dvoch príkazov je možné len vtedy, ak neexistujú žiadne závislosti registrov.
Jednou z hlavných vlastností šiestej generácie mikroprocesorov architektúry IA-32 je dynamický(špekulatívna) poprava. Tento výraz znamená nasledujúci súbor možností:
- predikcia hlbokej vetvy(s pravdepodobnosťou >90% môžete predpovedať ďalších 10-15 prechodov);
- analýza toku údajov(pozrite sa na program 20-30 krokov dopredu a zistite závislosť príkazov od údajov alebo zdrojov);
- dopredné vykonávanie príkazov(MP P6 môže vykonávať príkazy v inom poradí, ako je poradie v programe).
Vnútorná organizácia MP P6 zodpovedá teda architektúre RISC blok načítania inštrukcií, čítanie toku inštrukcií IA-32 z L1 cache inštrukcií, dekóduje ich do série mikrooperácií. Tok mikrooperácií spadá do zmena poradia vyrovnávacej pamäte (skupina inštrukcií). Obsahuje ako mikrooperácie, ktoré ešte neboli vykonané, tak tie, ktoré už boli vykonané, no zatiaľ neovplyvnili stav procesora.
Na dekódovanie pokynov tri paralelné dekodér: dva pre jednoduché a jeden pre zložité pokyny.
Každá inštrukcia IA-32 je dekódovaná v 1-4 mikrooperáciách. Vykonávajú sa mikrooperácie päť paralelných pohonov: dva pre celočíselná aritmetika, dve za skutočná aritmetika A blok pamäťového rozhrania. Takto je možné vykonať až päť mikrooperácií za cyklus hodín.
Jednotka pohonu schopný vybrať pokyny z fondu v akomkoľvek poradí. Zároveň vďaka blok predikcie vetvy je možné vykonávať inštrukcie po podmienených vetvách. Blok redundancie neustále monitoruje v zásobe inštrukcií tie mikrooperácie, ktoré sú pripravené na vykonanie (zdrojové dáta nezávisia od výsledku iných nevykonaných inštrukcií) a nasmeruje ich na voľné výkonné zariadenie príslušného typu. Jeden z celočíselných akčných členov dodatočne kontroluje, či sú predpovede vetvenia správne. Keď sa zistí nesprávne predpovedaná vetva, všetky mikrooperácie nasledujúce po prechode sa z fondu odstránia a príkazový kanál sa naplní pokynmi na novej adrese.
Vzájomná závislosť inštrukcií od hodnoty registrov architektúry IA-32 môže vyžadovať čakanie na uvoľnenie registrov. Na vyriešenie tohto problému sú navrhnuté 40 interných všeobecných registrov, používané v reálnych výpočtoch.
Odstrániť blok sleduje výsledok špekulatívne vykonaných mikrooperácií. Ak mikrooperácia už nie je závislá od iných mikrooperácií, jej výsledok sa prenesie do stavu procesora a odstráni sa z vyrovnávacej pamäte. Blok mazania potvrdzuje vykonanie inštrukcií (až tri mikrooperácie na cyklus hodín) v poradí, v akom sa objavujú v programe, berúc do úvahy prerušenia, výnimky, body prerušenia a zmeškania predikcie vetvenia.
Opísaná schéma je znázornená na obr. 4.7.

Obrázok 4.7 – Bloková schéma mikroprocesora Pentium Pro
4.6.2. SIMD rozšírenia MMX
Mnohé algoritmy na prácu s multimediálnymi dátami umožňujú najjednoduchšie prvky paralelizácie, kedy je možné jednu operáciu vykonávať paralelne na viacerých číslach. Tento prístup sa nazýva SIMD – jednoinštrukcia s viacerými dátami (jedna inštrukcia – viac dát). Táto technológia bola prvýkrát implementovaná v generácii P55 (mikroprocesor Pentium MMX).
MMX (Multi-Media eXtension) je SIMD nadstavba pre streamové spracovanie celočíselných dát, realizovaná na báze FPU bloku (pomocou FPU registrov).
Jedna MMX inštrukcia môže vykonávať aritmetickú alebo logickú operáciu na "dávkach" celých čísel zabalených v MMX registroch. Napríklad inštrukcia PADDSB pridá 8 bajtov jedného "paketu" k zodpovedajúcim ôsmim bajtom iného paketu, čím efektívne vykoná sčítanie ôsmich párov čísel jednou inštrukciou.
4.6.3. Procesory Pentium Pro, Pentium II, Pentium III
Procesor Pentium II kombinuje najlepšie vlastnosti procesorov Intel: výkon procesora Pentium Pro a možnosti technológie MMX. Táto kombinácia poskytuje výrazné zvýšenie výkonu procesorov Pentium II v porovnaní s predchádzajúcimi procesormi architektúry IA-32.
Procesor obsahuje samostatné interné 16 KB inštrukčné a dátové cache bloky a 512 KB zdieľanú neblokujúcu L2 cache.
Zvýšenie výkonu IA-32 bolo dosiahnuté nielen optimalizáciou potrubia inštrukcií a pridaním vykonávacích jednotiek, ale napríklad aj zavedením vyrovnávacej pamäte do jadra procesora. Rodina IA-32 po prvýkrát v procesoroch Intel-486 predstavila 8 KB on-chip L1 cache. V procesoroch Pentium sa veľkosť vyrovnávacej pamäte zdvojnásobila. Prví zástupcovia P6 (Pentium Pro) obsahovali aj L2 cache 256 alebo 512 KB. Takéto riešenie sa však v tom čase ukázalo ako príliš drahé a nerentabilné, preto bola technológia predstavená v Pentiu II. Dual Independent Bus (DIB) – dvojitý nezávislý autobus. Na prístup k vyrovnávacej pamäti a na prístup externá pamäť boli použité samostatné pneumatiky. Rovnaké architektonické riešenie bolo použité v prvých modeloch Pentium III. Počnúc rokom 1999 (Pentium III Coppermine) bola vyrovnávacia pamäť L2 opäť vrátená do procesora.
Vývojom myšlienky SIMD pre reálne čísla bola technológia SSE (streamované rozšírenia SIMD), prvýkrát predstavený v procesoroch Pentium III. Blok SSE dopĺňa technológiu MMX o osem 128-bitových registrov XMM0-XMM7 a 32-bitový riadiaci a stavový register MXCSR.
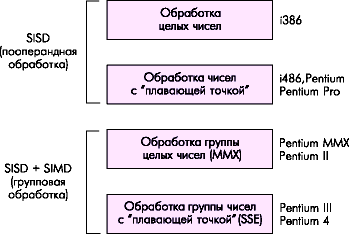
Obrázok 4.9 - Vývoj spracovania dát v procesoroch Intel Pentium
4.6.4. Pentium 4 (P7) – mikroarchitektúra Net Burst
Procesor Pentium 4 je 32-bitový zástupca rodiny IA-32, z hľadiska mikroarchitektúry patrí do novej, siedmej (podľa klasifikácie Intel) generácie. Zo softvérového hľadiska ide o procesor IA-32 s ďalším rozšírením inštrukčného systému - SSE2. Pokiaľ ide o sadu softvérovo prístupných registrov, Pentium 4 replikuje procesor Pentium III. Z externého, hardvérového hľadiska ide o procesor s novým typom systémovej zbernice, v ktorom sa okrem zvýšenia taktovacej frekvencie uplatňujú už známe princípy dvojitej (2x) a štvornásobnej (4x) synchronizácie, a prijíma sa množstvo opatrení na zabezpečenie prevádzky na predtým nepredstaviteľných frekvenciách. Mikroarchitektúra procesora s názvom Net Burst je navrhnutá s ohľadom na vysoké frekvencie jadra (viac ako 1,4 GHz) aj systémovej zbernice (400 MHz).
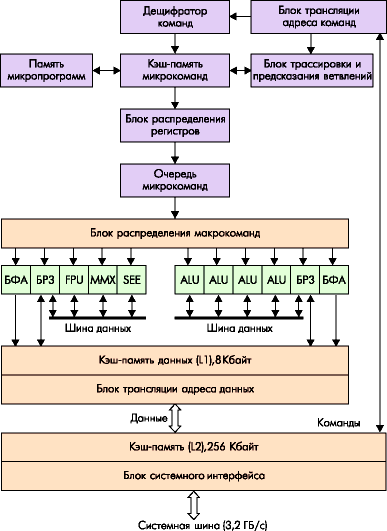
Obrázok 4.10 – Mikroarchitektúra NetBurst
Procesor Pentium 4 je jednočipový. Okrem samotného výpočtového jadra obsahuje dve úrovne vyrovnávacej pamäte. Sekundárna vyrovnávacia pamäť, spoločná pre inštrukcie a dáta, má veľkosť 256 KB a šírku zbernice 256 bitov (32 bajtov), ako napr. najnovšie procesory Pentium III. Sekundárna cache zbernica pracuje na frekvencii jadra, ktorá poskytuje jej priepustnosť 32x1,4 = 44,8 GB/s pri 1,4 GHz. Sekundárna vyrovnávacia pamäť má kontrolu ECC na detekciu a opravu chýb. Primárna dátová vyrovnávacia pamäť má rovnako vysokú priepustnosť (44,8 GB/s), no jej veľkosť bola znížená na polovicu (8 KB oproti 16 v Pentiu III). Neexistuje žiadna primárna vyrovnávacia pamäť inštrukcií v obvyklom zmysle; bola nahradená vyrovnávacou pamäťou sledovania. Ukladá sekvencie mikrooperácií, do ktorých sa dekódujú inštrukcie. Zmestí sa sem až 12K mikroinštrukcií.
Rozhranie systémovej zbernice procesora je navrhnuté len pre konfigurácie s jedným procesorom. Rozhranie v mnohom pripomína zbernicu P6, protokol je zameraný aj na súčasné vykonávanie viacerých transakcií. Na zabezpečenie vysokej priepustnosti bolo prijatých niekoľko opatrení. Procesor Pentium 4 má frekvenciu zbernice 400 MHz s „quad pumped“ - frekvencia hodín systémovej zbernice je 100 MHz, ale frekvencia prenosu adries a dát je vyššia. Nové informácie je možné prenášať po linkách so spoločnou synchronizáciou pri každom takte s frekvenciou 100 MHz. Pri 2 a 4-násobnom prenose sa používa synchronizácia zo zdroja dát.
Akčné členy MP (ALU) pracujú s dvojnásobnou frekvenciou, čo umožňuje vykonávať väčšinu celočíselných inštrukcií v polovici hodinového cyklu. V porovnaní s predchádzajúcimi generáciami IA-32 obsahuje Pentium 4 najdlhšiu inštrukčnú pipeline, ktorá pozostáva z 20 stupňov a tzv. hyperpipeline. V súvislosti s touto funkciou mnohí odborníci poznamenávajú, že mikroarchitektúra NetBurst bude mať maximálny výkon vykonávanie predvídateľných (lineárnych a cyklických) častí programu, charakteristických pre aplikácie, na ktoré je určené Pentium 4. Na nepredvídateľne sa vetviacich programoch, medzi ktoré patria napríklad kancelárske aplikácie, sa dlhý hyperpipeline ukazuje ako menej efektívny ako P6 pipeline, ak by sa dal pretaktovať na frekvencie 1,4 GHz a vyššie. Na čiastočnú kompenzáciu tohto nedostatku boli výrazne optimalizované mechanizmy špekulatívneho vykonávania a predikcie vetvenia.
Materiál v kapitole 4 je založený na syntéze prác.
Vylúčenie zodpovednosti
Pravdepodobne najpresnejší dôvod vzhľadu tohto materiálu možno formulovať takto: „nie je až tak potrebné, aby existoval, ale skôr je zvláštne, že ešte neexistoval“. A skutočne: v komentároch k výsledkom testov neustále pracujeme s pojmami ako „kapacita vyrovnávacej pamäte“, „rýchlosť zbernice procesora“, „podpora rozšírených inštrukčných sád“, ale na stránke nie je jediný článok, ktorý by obsahoval vysvetlenia všetkých týchto výrazov. Toto opomenutie malo byť, samozrejme, odstránené. Tento článok s podtitulom „Často kladené otázky CPU x86“ je pokusom o to. Samozrejme, niektoré jeho sekcie možno pripísať nielen x86 procesorom, a nielen ich desktopovým (určeným na inštaláciu do PC) verziám, no na takýto globalizmus rozhodne necielime. Preto si prosím pamätajte, že na účely tohto materiálu, pokiaľ nie je výslovne uvedené inak, slovo „procesor“ znamená „procesor x86 určený na inštaláciu do stolných počítačov“. Možno sa v procese ďalšieho vylepšovania a rozširovania v článku objavia časti venované serverovým CPU alebo aj procesorom iných architektúr, ale to je záležitosť budúcnosti...
Úvod
Kód a dáta: základný princíp procesora
Ak sa tu teda nesnažíme prezentovať „krátky“ kurz informatiky pre strednú školu, tak jediné, čo by som vám rád pripomenul, je, že procesor (až na ojedinelé výnimky) nevykonáva programy napísané v nejakom programovacom programe. jazyk (jeden z nich, možno aj poznáte), ale nejaký druh „strojového kódu“. To znamená, že príkazy sú sekvencie bajtov umiestnených v pamäti počítača. Niekedy sa príkaz môže rovnať jednému bajtu, niekedy trvá niekoľko bajtov. Tam sa v hlavnej pamäti (RAM, RAM) nachádzajú aj dáta. Môžu byť v samostatnej oblasti alebo môžu byť „zmiešané“ s kódom. Rozdiel medzi kódom a údajmi je v tom, že údaje sú to, čo nad čím Procesor vykonáva niektoré operácie. A kód sú príkazy, ktoré mu hovoria, aký druh operácie? musí vyrábať. Pre zjednodušenie si môžeme program a jeho dáta predstaviť ako postupnosť bajtov určitej konečnej dĺžky, umiestnených súvisle (nekomplikujme to) v spoločnom pamäťovom poli. Napríklad máme pamäťové pole dlhé 1 000 000 bajtov a náš program (spolu s údajmi) má bajty očíslované od 1 000 do 20 000. Ostatné bajty sú iné programy alebo ich dáta, alebo jednoducho voľná pamäť, ktorá nie je obsadená ničím užitočným.
Takže „strojový kód“ sú inštrukcie procesora umiestnené v pamäti. Tam sa nachádzajú aj údaje. Aby mohol procesor vykonať inštrukciu, musí ju prečítať z pamäte. Aby mohol procesor vykonať operáciu s dátami, musí ich prečítať z pamäte a prípadne po vykonaní určitej akcie na nich zapísať späť do pamäte v aktualizovanej (zmenenej) podobe. Príkazy a dáta sú identifikované svojou adresou, ktorá je v podstate sériovým číslom pamäťového miesta.
Všeobecné princípy interakcie
procesor a RAM
Niekoho môže prekvapiť, že pomerne veľká časť v FAQ venovaná x86 CPU je venovaná vysvetleniu funkcií pamäte v moderné systémy ah, na základe tohto typu procesora. Fakty sú však tvrdohlavá vec: samotné procesory x86 teraz obsahujú toľko blokov zodpovedných špeciálne za optimalizáciu ich práce s RAM, že by bolo úplne smiešne ignorovať toto úzke prepojenie. Dá sa dokonca povedať toto: keďže riešenia súvisiace s optimalizáciou práce s pamäťou sa stali neoddeliteľnou súčasťou samotných procesorov, potom možno pamäť samotnú považovať za akýsi „prídavok“, ktorého fungovanie má priamy vplyv na rýchlosť. CPU. Bez pochopenia zvláštností interakcie medzi procesorom a pamäťou nie je možné pochopiť, prečo konkrétny procesor (ten či onen systém) vykonáva programy pomalšie alebo rýchlejšie.
Pamäťový ovládač
Takže vyššie sme už hovorili o tom, že príkazy aj údaje vstupujú do procesora Náhodný vstup do pamäťe. V skutočnosti je všetko trochu komplikovanejšie. Vo väčšine moderných systémov x86 (teda počítačov založených na procesoroch x86) nemôže procesor ako zariadenie vôbec pristupovať k pamäti, pretože nemá zodpovedajúce uzly. Preto sa obracia na „stredné“ špecializované zariadenie nazývané pamäťový radič, ktorý sa zase obracia na čipy RAM umiestnené na pamäťových moduloch. Pravdepodobne ste videli moduly - sú to dlhé úzke textolitové "dosky" (v skutočnosti malé dosky) s množstvom mikroobvodov, ktoré sú vložené do špeciálnych konektorov na základnej doske. Úloha radiča RAM je teda jednoduchá: slúži ako akýsi „most“* medzi pamäťou a zariadeniami, ktoré ju používajú (mimochodom, to zahŕňa nielen procesor, ale o tom trochu neskôr). Pamäťový radič je spravidla súčasťou čipovej sady - sady čipov, ktorá je základom základnej dosky. Rýchlosť výmeny dát medzi procesorom a pamäťou do značnej miery závisí od rýchlosti radiča, čo je jedna z najdôležitejších súčastí ovplyvňujúcich celkový výkon počítača.
* - mimochodom, pamäťový radič je fyzicky umiestnený v čipe čipovej sady, ktorý sa tradične nazýva „severný most“.
Procesorová zbernica
Každý procesor je nevyhnutne vybavený zbernicou procesora, ktorá sa v prostredí CPU x86 zvyčajne nazýva FSB (Front Side Bus). Táto zbernica slúži ako komunikačný kanál medzi procesorom a všetkými ostatnými zariadeniami v počítači: pamäť, grafická karta, pevný disk, a tak ďalej. Ako však už vieme z predchádzajúcej časti, medzi samotnou pamäťou a procesorom sa nachádza pamäťový radič. V súlade s tým: procesor komunikuje cez FSB s pamäťovým radičom, ktorý zase komunikuje prostredníctvom špeciálnej zbernice (nazvime to bez ďalšieho „pamäťová zbernica“) s modulmi RAM na doske. Opakujeme však: keďže klasický x86 CPU má len jednu „externú“ zbernicu, slúži nielen na prácu s pamäťou, ale aj na komunikáciu medzi procesorom a všetkými ostatnými zariadeniami.
Rozdiely medzi tradičnými
x86 architektúra CPU a K8/AMD64
Revolučný prístup AMD spočíva v tom, že jeho procesory s architektúrou AMD64 (a mikroarchitektúrou, ktorá sa bežne nazýva „K8“) sú vybavené mnohými „externými“ zbernicami. V tomto prípade sa jedna alebo viac zberníc HyperTransport používa na komunikáciu so všetkými zariadeniami okrem pamäte a samostatná skupina jednej alebo dvoch (v prípade dvojkanálového radiča) zberníc sa používa výlučne na prevádzku procesora s pamäťou. Výhoda integrácie pamäťového radiča priamo do procesora je zrejmá: „cesta od jadra k pamäti“ sa výrazne skráti, čo vám umožní pracovať s RAM rýchlejšie. Je pravda, že tento prístup má aj nevýhody. Napríklad, ak sa predtým zariadeniam páčili pevný disk alebo grafické karty by mohli pracovať s pamäťou cez dedikovaný, nezávislý radič - potom v prípade architektúry AMD64 sú nútené pracovať s RAM cez radič umiestnený na procesore. Pretože CPU v tejto architektúre je jediným zariadením s priamym prístupom k pamäti. De facto v konfrontácii „externý kontrolór vs. integrovaná“, vznikla parita: na jednej strane je AMD v súčasnosti jediným výrobcom desktopových x86 procesorov s integrovaným pamäťovým radičom, na druhej strane sa zdá, že spoločnosť je s týmto riešením celkom spokojná a nechystá sa ho opustiť . Po tretie, Intel sa tiež nevzdá externého ovládača a je celkom spokojný s „klasickou schémou“, overenou rokmi.
RAM
Šírka pamäťovej zbernice, N-kanálové pamäťové radiče
Od dnešného dňa má všetka pamäť používaná v moderných x86 desktopových systémoch 64-bitovú širokú zbernicu. To znamená, že v jednom hodinovom cykle môže byť na tejto zbernici súčasne prenesené množstvo informácií, ktoré je násobkom 8 bajtov (8 bajtov pre zbernice SDR, 16 bajtov pre zbernice DDR). Jediná vec, ktorá vyniká, je pamäť typu RDRAM, ktorá sa používala v systémoch založených na procesoroch Intel Pentium 4 na úsvite architektúry NetBurst, ale teraz je tento smer uznávaný ako slepá ulička pre počítače x86 (mimochodom V tom mala prsty tá istá spoločnosť Intel, ktorú svojho času aktívne propagovala tento typ Pamäť). Určitý zmätok spôsobujú iba dvojkanálové radiče, ktoré poskytujú súčasnú prevádzku s dvoma samostatnými 64-bitovými zbernicami, kvôli čomu niektorí výrobcovia uvádzajú určitú „128-bitovú“ schopnosť. Toto je, samozrejme, čistá profanácia. Aritmetika na úrovni 1. ročníka, žiaľ, v tomto prípade nefunguje: 2x64 sa vôbec nerovná 128. Prečo? Áno, už len preto, že ani najmodernejšie x86 CPU (pozri sekciu FAQ „64-bitové rozšírenia klasickej architektúry x86 (IA32) nižšie“) nedokážu pracovať so 128-bitovou zbernicou a 128-bitovým adresovaním. Zhruba povedané: dve nezávislé paralelné cesty, každá so šírkou 2 metre, môžu poskytnúť súčasný prejazd dvoch áut širokých 2 metre - v žiadnom prípade však jedného, širokého 4 metre. Rovnakým spôsobom môže N-kanálový pamäťový radič zvýšiť rýchlosť práce s dátami N-krát (a potom viac teoreticky ako prakticky) - ale nie je v žiadnom prípade schopný zvýšiť bitovú kapacitu týchto dát. Šírka pamäťovej zbernice vo všetkých moderných radičoch používaných v systémoch x86 je 64 bitov – bez ohľadu na to, či je tento radič umiestnený v čipsete alebo v samotnom procesore. Niektoré radiče sú vybavené dvoma nezávislými 64-bitovými kanálmi, čo však nijako neovplyvňuje šírku pamäťovej zbernice - iba rýchlosť čítania a zápisu informácií.
Rýchlosť čítania a zápisu
Rýchlosť čítania a zápisu informácií do pamäte je teoreticky obmedzená výlučne šírkou pásma samotnej pamäte. Napríklad dvojkanálový pamäťový radič DDR400 je teoreticky schopný poskytnúť rýchlosť čítania a zápisu informácií rovnajúcu sa 8 bajtom (šírka zbernice) * 2 (počet kanálov) * 2 (protokol DDR, ktorý zabezpečuje prenos 2 dátových paketov na hodinový cyklus) * 200"000"000 (skutočná prevádzková frekvencia pamäťovej zbernice je 200 MHz, to znamená 200"000"000 hodinových cyklov za sekundu). Hodnoty získané ako výsledok praktických testov sú spravidla o niečo nižšie ako teoretické: je to kvôli „nedokonalému“ dizajnu pamäťového radiča plus režijné náklady (oneskorenia) spôsobené prevádzkou ukladania do vyrovnávacej pamäte. podsystému samotného procesora (pozrite si časť o vyrovnávacej pamäti procesora nižšie). Hlavný „úlovok“ však nie je ani v prekryvoch spojených s prevádzkou ovládača a cachovacieho subsystému, ale v tom, že rýchlosť „lineárneho“ čítania alebo zápisu nie je jedinou charakteristikou, ktorá ovplyvňuje skutočnú rýchlosť procesor s RAM. Aby sme pochopili, aké komponenty tvoria skutočnú rýchlosť procesora a pamäte, musíme okrem lineárnej rýchlosti čítania alebo zápisu zohľadniť aj takú charakteristiku, ako je napr. latencia.
Latencia
Latencia nie je menšia dôležitá charakteristika z hľadiska rýchlosti pamäťového subsystému, ako rýchlosť „čerpania dát“, ale v podstate úplne iná. Vysoká rýchlosť výmeny dát je dobrá, keď je ich veľkosť relatívne veľká, ale ak potrebujeme „po troškách z rôznych adries“, potom prichádza do popredia latencia. Čo to je? Vo všeobecnosti čas potrebný na začatie čítania informácií z konkrétnej adresy. A skutočne: od okamihu, keď procesor odošle príkaz na čítanie (zápis) do pamäťového radiča, až do okamihu, keď sa táto operácia vykoná, uplynie určitý čas. Navyše sa to vôbec nerovná času, ktorý je potrebný na prenos dát. Po prijatí príkazu na čítanie alebo zápis z procesora mu pamäťový radič „naznačí“, s ktorou adresou chce pracovať. Prístup k ľubovoľnej náhodne zvolenej adrese nie je možné dosiahnuť okamžite, vyžaduje si to určitý čas. Nastane oneskorenie: adresa je zadaná, ale pamäť ešte nie je pripravená poskytnúť k nej prístup. Vo všeobecnosti sa toto oneskorenie nazýva latencia. U odlišné typy pamäť je iná. Napríklad pamäť DDR2 má v priemere oveľa vyššie latencie ako DDR (pri rovnakej frekvencii prenosu dát). V dôsledku toho, ak sú údaje v programe umiestnené „chaoticky“ a v „malých častiach“, rýchlosť ich čítania sa stáva oveľa menej dôležitou ako rýchlosť prístupu k „začiatku časti“, pretože oneskorenia pri prechode na ďalšia adresa ovplyvňuje výkon systému oveľa viac ako rýchlosť čítania alebo zápisu.
„Konkurencia“ medzi rýchlosťou čítania (zápisu) a latenciou je jednou z hlavných bolestí hlavy vývojárov moderných systémov: bohužiaľ, zvýšenie rýchlosti čítania (zápisu) takmer vždy vedie k zvýšeniu latencie. Napríklad pamäť typu SDR (PC66, PC100, PC133) má v priemere lepšiu (nižšiu) latenciu ako DDR. Na druhej strane DDR2 má ešte vyššiu latenciu (teda horšiu) ako DDR.
Malo by byť zrejmé, že „celková“ latencia pamäťového subsystému závisí nielen od seba, ale aj od pamäťového radiča a jeho umiestnenia - všetky tieto faktory tiež ovplyvňujú latenciu. Preto sa AMD v procese vývoja architektúry AMD64 rozhodla vyriešiť problém vysokej latencie „jedným ťahom“ integráciou radiča priamo do procesora – s cieľom „skrátiť vzdialenosť“ medzi jadrom procesora a modulov RAM čo najviac. Myšlienka bola úspešná, ale za vysokú cenu: teraz systém založený na špecifickom CPU s architektúrou AMD64 môže pracovať iba s pamäťou, pre ktorú je jeho radič navrhnutý. Zrejme aj preto sa Intel zatiaľ neodhodlal k takémuto razantnému kroku a radšej konal tradičnými metódami: vylepšením pamäťového radiča v čipsete a mechanizmu Prefetch v procesore (podrobnosti pozri nižšie).
Na záver poznamenávame, že pojmy „rýchlosť čítania/zápisu“ a „latencia“ sa vo všeobecnosti vzťahujú na akýkoľvek typ pamäte – vrátane nielen klasickej DRAM (SDR, Rambus, DDR, DDR2), ale aj vyrovnávacej pamäte (pozri nižšie).
Procesor: Všeobecné informácie
Koncept architektúry
Architektúra ako kompatibilita kódu
Určite ste sa často stretli s pojmom „x86“ alebo „Intel-kompatibilný procesor“ (alebo „IBM PC kompatibilný“ - ale to sa týka počítača). Niekedy sa používa aj výraz „kompatibilný s Pentium“ (prečo Pentium - pochopíte o niečo neskôr). Čo sa vlastne skrýva za všetkými týmito názvami? V súčasnosti vyzerá z pohľadu autora najsprávnejšie nasledujúca jednoduchá formulácia: moderný x86 procesor je procesor schopný správne vykonávať strojový kód architektúry IA32 (architektúra 32-bitových procesorov Intel). Pri prvom priblížení ide o kód vykonávaný procesorom i80386 (populárne známym ako „386“), ale hlavná inštrukčná sada IA32 bola nakoniec vytvorená s vydaním procesora Intel Pentium Pro. Čo znamená „core set“ a aké sú ďalšie? Najprv odpovedzme na prvú časť otázky. „Základný“ v tomto prípade znamená, že iba pomocou tejto sady inštrukcií je možné napísať akýkoľvek program, ktorý sa dá vo všeobecnosti napísať pre procesor x86 (alebo IA32, ak chcete).
Okrem toho má architektúra IA32 „oficiálne“ rozšírenia (ďalšie inštrukčné sady) od vývojára samotnej architektúry Intel: MMX, SSE, SSE2 a SSE3. Existujú aj „neoficiálne“ (nie Intel) rozšírené sady príkazov: EMMX, 3DNow! a Rozšírené 3DNow! - boli vyvinuté spoločnosťou AMD. „Oficiálne“ a „neoficiálne“ sú však v tomto prípade relatívnym pojmom – de facto to všetko súvisí s tým, že niektoré rozšírenia inštrukčnej sady uznáva Intel ako vývojár pôvodnej sady a niektoré sú nie, zatiaľ čo vývojári softvéru používajú to, čo je pre nich najlepšie, všetko vyhovuje. Pokiaľ ide o rozšírené súbory inštrukcií, existuje jedno jednoduché pravidlo dobrej etikety: pred ich použitím by mal program skontrolovať, či ich procesor podporuje. Niekedy sa vyskytujú odchýlky od tohto pravidla (a môžu viesť k nesprávnemu fungovaniu programov), ale objektívne ide o problém nesprávne napísaného softvéru, nie procesora.
Na čo slúžia doplnkové sady príkazov? V prvom rade zvýšiť výkon pri vykonávaní určitých operácií. Jeden príkaz zo sekundárnej sady zvyčajne vykoná akciu, ktorá by vyžadovala malý program pozostávajúci z príkazov z hlavnej sady. Opäť platí pravidlo, že procesor vykoná jednu inštrukciu rýchlejšie ako sekvenciu, ktorú nahrádza. Avšak v 99% prípadov nič, čo by nebolo možné vykonať pomocou základných príkazov, nie je možné vykonať pomocou príkazov z doplnkovej sady.
Vyššie uvedená kontrola programom na podporu prídavných inštrukčných sád procesorom by teda mala vykonávať veľmi jednoduchú funkciu: ak napríklad procesor podporuje SSE, tak budeme počítať rýchlo a pomocou inštrukcií zo sady SSE. Ak nie, budeme počítať pomalšie pomocou príkazov z hlavnej sady. Správne napísaný program sa musí správať týmto spôsobom. V súčasnosti však takmer nikto nekontroluje podporu MMX procesora, pretože všetky CPU vydané za posledných 5 rokov zaručene podporujú túto zostavu. Pre referenciu je tu tabuľka, ktorá sumarizuje informácie o podpore rôznych rozšírených príkazových sád rôznymi desktopovými (určenými pre stolné PC) procesormi.
| CPU | |||||||
| Intel Pentium II | |||||||
| Intel Celeron až do 533 MHz | |||||||
| Intel Pentium III | |||||||
| Intel Celeron 533-1400 MHz | |||||||
| Intel Pentium 4 | |||||||
| Intel Celeron od 1700 MHz | |||||||
| Intel Celeron D | |||||||
| Intel Pentium 4 eXtreme Edition | |||||||
| Intel Pentium eXtreme Edition | |||||||
| Intel Pentium D | |||||||
| AMD K6 | |||||||
| AMD K6-2 | |||||||
| AMD K6-III | |||||||
| AMD Athlon | |||||||
| AMD Duron až do 900 MHz | |||||||
| AMD Athlon XP | |||||||
| AMD Duron od 1000 MHz | |||||||
| AMD Athlon 64 / Athlon FX | |||||||
| AMD Sempron | |||||||
| AMD Athlon 64 X2 | |||||||
| VIA C3 |
*v závislosti od úpravy
V súčasnosti sú všetky populárne desktopy softvér(operačné systémy Windows a Linux, kancelárske balíky, počítačové hry, atď.) sa vyvíja špeciálne pre procesory x86. Beží (s výnimkou „zle spravených“ programov) na akomkoľvek x86 procesore bez ohľadu na to, kto ho vyrobil. Preto namiesto výrazov „kompatibilný s Intelom“ alebo „kompatibilný s Pentium“ zameraných na vývojárov pôvodnej architektúry začali používať neutrálny názov: „procesor kompatibilný s x86“, „procesor s architektúrou x86“. V tomto prípade „architektúra“ znamená kompatibilitu s určitým súborom inštrukcií, teda možno povedať „architektúru procesora z pohľadu programátora“. Existuje iný výklad toho istého pojmu.
Architektúra ako charakteristika rodiny procesorov
„Zhelezyachniki“ - ľudia, ktorí nepracujú hlavne so softvérom, ale s hardvérom, chápu „architektúru“ trochu iným spôsobom (aj keď je správnejšie, že to, čo nazývajú „architektúra“, sa nazýva „mikroarchitektúra“, ale de facto predpona „ mikro“ sa často vynecháva). Pre nich je „architektúra CPU“ určitým súborom vlastností, ktoré sú vlastné celej rodine procesorov, zvyčajne vyrábaných mnoho rokov (inými slovami „interný dizajn“, „organizácia“ týchto procesorov). Takže napríklad každý špecialista na x86 CPU vám povie, že procesor s ALU pracujúcimi s dvojnásobnou frekvenciou, QDR zbernicou, Trace cache a možno aj podporou technológie Hyper-Threading je „procesor architektúry NetBurst“ (nebuďte znepokojený neznámymi pojmami - všetky budú vysvetlené o niečo neskôr). A procesory Intel Pentium Pro, Pentium II a Pentium III sú „architektúra P6“. Pojem „architektúra“ vo vzťahu k procesorom je teda trochu nejednoznačný: možno ho chápať ako kompatibilitu s určitou jedinou sadou inštrukcií, ako aj ako súbor hardvérových riešení, ktoré sú vlastné určitej pomerne širokej skupine procesorov. Samozrejme, takýto dualizmus jedného zo základných konceptov nie je príliš pohodlný, ale je to tak a je nepravdepodobné, že sa v blízkej budúcnosti niečo zmení...
64-bitové rozšírenia klasickej architektúry x86 (IA32).
Nie je to tak dávno, čo obaja poprední výrobcovia x86 CPU ohlásili dve takmer identické* technológie (avšak AMD to radšej nazýva architektúra), vďaka ktorým získali klasické x86 (IA32) CPU status 64-bit. V prípade AMD túto technológiu dostal názov „AMD64“ (64-bit architektúra AMD), v prípade Intel - „EM64T“ (technológia vylepšenej 64-bitovej pamäte). Tiež vážení starší ľudia, ktorí poznajú históriu problému, niekedy používajú názov „x86-64“ - ako všeobecné označenie pre všetky 64-bitové rozšírenia architektúry x86, ktoré nie sú viazané na registrované ochranné známky žiadneho výrobcu. De facto použitie jedného z troch vyššie uvedených názvov závisí viac od osobných preferencií používateľa ako od skutočných rozdielov - pretože rozdiely medzi AMD64 a EM64T sú na špičke veľmi tenkej ihly. Samotné AMD navyše len krátko pred ohlásením vlastných procesorov založených na tejto architektúre predstavilo „značkový“ názov „AMD64“ a ešte predtým celkom pokojne vo vlastných dokumentoch používalo neutrálnejšie „x86-64“. Avšak, tak či onak, všetko sa týka jednej veci: niektoré interné procesorové registre sa stali 64-bitovými namiesto 32-bitových, 32-bitové kódové inštrukcie x86 dostali svoje 64-bitové analógy, navyše množstvo adresovateľná pamäť (vrátane nielen fyzickej, ale aj virtuálnej) sa mnohonásobne zvýšila (v dôsledku skutočnosti, že adresa získala 64-bitový formát namiesto 32-bitového). Množstvo marketingových špekulácií na tému „64-bit“ prekročilo všetky rozumné hranice, preto by sme mali prednosti tejto inovácie zvážiť obzvlášť dôkladne. Takže: čo sa vlastne zmenilo a čo nie?
* - Argumenty, že Intel „bezočivo skopíroval EM64T z AMD64“, neobstoja v kritike. A už vôbec nie preto, že to tak nie je – ale preto, že to vôbec nie je „drzé“. Existuje taký koncept: „krížová licenčná zmluva“. Ak dôjde k takejto dohode, znamená to, že všetok vývoj jednej spoločnosti v určitej oblasti sa automaticky stane dostupným inej spoločnosti, rovnako ako vývoj inej spoločnosti bude automaticky dostupný prvej. Intel využil krížové licencovanie na vývoj EM64T, pričom ako základ použil AMD64 (čo nikto nikdy nepoprel). AMD využilo rovnakú dohodu na zavedenie podpory pre ďalšie inštrukčné sady SSE2 a SSE3 vyvinuté spoločnosťou Intel do svojich procesorov. A nie je v tom nič hanebné: keďže sme sa dohodli na „zdieľaní“ vývoja, znamená to, že sa musíme podeliť.
Čo sa nezmenilo? V prvom rade rýchlosť procesorov. Bola by nehorázna hlúposť predpokladať, že ten istý procesor pri prepnutí z bežného 32-bitového do 64-bitového režimu (a všetky súčasné x86 CPU nevyhnutne podporujú 32-bitový režim) bude pracovať 2-krát rýchlejšie. Samozrejme, v niektorých prípadoch môže dôjsť k určitému zrýchleniu pri použití 64-bitovej celočíselnej aritmetiky – ale počet týchto prípadov je veľmi obmedzený a neovplyvňujú väčšinu moderného používateľského softvéru. Mimochodom: prečo sme použili výraz „64-bitová celočíselná aritmetika“? Ale pretože bloky operácií s pohyblivou rádovou čiarkou (pozri nižšie) vo všetkých x86 procesoroch už dávno nie sú 32-bitové. A dokonca ani 64-bit. Klasický x87 FPU (pozri nižšie), ktorý sa konečne stal súčasťou CPU v časoch starého dobrého 32-bitového Intel Pentium - bol už 80-bitový. Operandy inštrukcií SSE a SSE2/3 sú 128-bitové! V tomto ohľade je architektúra x86 dosť paradoxná: napriek tomu, že formálne zostali procesory tejto architektúry 32-bitové pomerne dlho - bitová kapacita tých blokov, kde „b O„vyššia bitová kapacita“ bola skutočne potrebná – zvyšovala sa úplne nezávisle od zvyšku. Napríklad procesory AMD Athlon XP a Intel Pentium 4 „Northwood“ kombinovali jednotky, ktoré pracovali s 32-bitovými, 80-bitovými a 128-bitovými operandmi. Len hlavná inštrukčná sada (zdedená od prvého procesora architektúry IA32 - Intel 386) a adresovanie pamäte (maximálne 4 gigabajty, nepočítajúc „perverzie“ ako Intel PAE) zostali 32-bitové.
Skutočnosť, že procesory AMD a Intel sa stali „formálne 64-bitovými“, nám v praxi priniesla iba tri vylepšenia: vzhľad príkazov na prácu so 64-bitovými celými číslami, zvýšenie počtu a/alebo bitovej hĺbky registrov, a zvýšenie pamäte maximálneho adresovateľného objemu. Poznámka: nikto nepopiera skutočné výhody týchto inovácií (najmä tretej!). Rovnako ako nikto nepopiera zásluhy AMD pri presadzovaní myšlienky „modernizácie“ (v dôsledku zavedenia 64-bitových) procesorov x86. Chceme len varovať pred nadmernými očakávaniami: nemali by ste dúfať, že počítač zakúpený „v cenovej triede VAZ“ sa stane „štýlovým Mercedesom“ bez inštalácie 64-bitového softvéru. Na svete nie sú žiadne zázraky...
Jadro procesora
Rozdiely medzi jadrami rovnakej mikroarchitektúry
„Jadro procesora“ (zvyčajne jednoducho „jadro“ kvôli stručnosti) je špecifické stelesnenie [mikro]architektúry (t. j. „architektúra v hardvérovom zmysle slova“), ktorá je štandardom pre celú sériu. spracovateľov. Napríklad NetBurst je mikroarchitektúra, ktorá je základom mnohých dnešných procesorov Intel: Celeron, Pentium 4, Xeon. Mikroarchitektúra stanovuje všeobecné princípy: dlhý kanál, použitie určitého typu vyrovnávacej pamäte kódu prvej úrovne (Trace cache) a ďalšie „globálne“ funkcie. Jadro je konkrétnejšie uskutočnenie. Napríklad procesory mikroarchitektúry NetBurst so zbernicou 400 MHz, 256 kilobajtovou vyrovnávacou pamäťou druhej úrovne a bez Podpora Hyper-Threading je viac-menej úplný popis jadra Willamette. Ale jadro Northwood má vyrovnávaciu pamäť druhej úrovne 512 kilobajtov, hoci je tiež založené na NetBurst. Jadro AMD Thunderbird je založené na mikroarchitektúre K7, ale nepodporuje inštrukčnú sadu SSE, ale jadro Palomino áno.
Môžeme teda povedať, že „jadro“ je špecifickým stelesnením určitej mikroarchitektúry „v kremíku“, ktorá má (na rozdiel od samotnej mikroarchitektúry) určitý súbor striktne definovaných charakteristík. Mikroarchitektúra je amorfná, popisuje všeobecné princípy návrhu procesora. Jadrom je konkrétne mikroarchitektúra „prerastená“ všetkými druhmi parametrov a charakteristík. Pre procesory je extrémne zriedkavé zmeniť mikroarchitektúru pri zachovaní rovnakého mena. A naopak, takmer každý názov procesora počas svojej existencie aspoň niekoľkokrát „zmenil“ svoje jadro. Napríklad všeobecný názov série procesorov AMD je „Athlon XP“ - ide o jednu mikroarchitektúru (K7), ale až štyri jadrá (Palomino, Thoroughbred, Barton, Thorton). Rôzne jadrá postavené na rovnakej mikroarchitektúre môžu mať okrem iného rôzne úrovne výkonu.
audity
Revízia je jednou z modifikácií jadra, ktorá sa veľmi mierne líši od predchádzajúcej, a preto si nezaslúži označenie „nové jadro“. Výrobcovia procesorov si spravidla nerobia ťažkú hlavu z vydania ďalšej revízie, deje sa to „v prevádzkovom stave“. Takže aj keď si kúpite rovnaký procesor, s úplne podobným názvom a charakteristikami, ale s odstupom približne šiestich mesiacov, je dosť možné, že v skutočnosti bude mierne odlišný. Vydanie novej revízie je zvyčajne spojené s niektorými menšími vylepšeniami. Podarilo sa nám napríklad mierne znížiť spotrebu energie, znížiť napájacie napätie, prípadne optimalizovať niečo iné, prípadne sa podarilo odstrániť pár drobných chýb. Z hľadiska výkonu si nepamätáme jediný príklad, kedy by sa jedna revízia jadra líšila od druhej tak výrazne, že by malo zmysel o tom hovoriť. Aj keď je táto možnosť čisto teoreticky možná – bol napríklad optimalizovaný jeden z procesorových blokov zodpovedných za vykonávanie niekoľkých príkazov. Aby sme to zhrnuli, môžeme povedať, že najčastejšie sa neoplatí obťažovať revíziami procesora: vo veľmi zriedkavých prípadoch zmena revízie spôsobí niektoré zásadné zmeny v procesore. Stačí vedieť, že niečo také existuje - výlučne pre všeobecný rozvoj.
Frekvencia jadra
Spravidla sa tento parameter hovorovo označuje ako „frekvencia procesora“. Hoci vo všeobecnom prípade je definícia „pracovnej frekvencie jadra“ stále správnejšia, pretože nie je vôbec potrebné, aby všetky komponenty CPU pracovali na rovnakej frekvencii ako jadro (najčastejším príkladom opaku bol starý „slot“ x86 CPU – Intel Pentium II a Pentium III pre Slot 1, AMD Athlon pre Slot A – ich vyrovnávacia pamäť L2 fungovala na 1/2 a niekedy dokonca na 1/3 frekvencie jadra). Ďalšou bežnou mylnou predstavou je presvedčenie, že frekvencia jadra jednoznačne určuje výkon. V skutočnosti je to dvakrát nesprávne: po prvé, každé konkrétne jadro procesora (v závislosti od toho, ako je navrhnuté, koľko vykonávacích jednotiek obsahuje rôzne druhy, atď. atď.) môže vykonávať rôzny počet príkazov v jednom hodinovom cykle, ale frekvencia je len počet takýchto hodinových cyklov za sekundu. Takto (porovnanie nižšie je, samozrejme, veľmi zjednodušené a teda veľmi ľubovoľné), procesor, ktorého jadro vykoná 3 inštrukcie za takt, môže mať o tretinu nižšiu frekvenciu ako procesor vykonávajúci 2 inštrukcie za takt - a zároveň mať úplne podobný výkon.
Po druhé, aj v rámci toho istého jadra zvýšenie frekvencie nevedie vždy k úmernému zvýšeniu výkonu. Tu budú pre vás veľmi užitočné znalosti, ktoré ste mohli získať z časti „Všeobecné princípy interakcie medzi procesorom a RAM“. Faktom je, že rýchlosť vykonávania príkazov jadrom procesora nie je jediným ukazovateľom, ktorý ovplyvňuje rýchlosť vykonávania programu. Rovnako dôležitá je rýchlosť, akou príkazy a dáta prichádzajú do CPU. Predstavme si, čisto teoreticky, takýto systém: rýchlosť procesora je 10 000 príkazov za sekundu, rýchlosť pamäte je 1 000 bajtov za sekundu Otázka: aj keď predpokladáme, že jeden príkaz nezaberá viac ako jeden bajt a nemáme žiadne vôbec dáta, akou rýchlosťou sa bude v takomto systéme vykonávať program? Správne: nie viac ako 1000 príkazov za sekundu a výkon CPU s tým nemá absolútne nič spoločné: budeme limitovaní nie tým, ale rýchlosťou pri ktorých príkazy vstupujú do procesora. Mali by ste teda pochopiť: nie je možné nepretržite zvyšovať jednu jadrovú frekvenciu bez súčasného zrýchlenia pamäťového subsystému, pretože v tomto prípade, počnúc od určitej fázy, zvýšenie frekvencie CPU už nebude mať vplyv na zvýšenie výkonu systému ako celku.
Vlastnosti tvorby názvov procesorov
Predtým, keď bola obloha modrejšia, pivo chutilo lepšie a dievčatá boli krajšie, spracovatelia sa volali jednoducho: meno výrobcu + titul modelový rad+ frekvencia. Napríklad: "AMD K6-2 450 MHz". V súčasnosti sa obaja významní výrobcovia od tejto tradície vzdialili a namiesto frekvencie používajú nejaké nepochopiteľné čísla, ktoré naznačujú, kto vie čo. Nasledujúce dve časti sú venované krátkemu vysvetleniu, čo tieto čísla vlastne znamenajú.
Hodnotenie od AMD
Dôvod, prečo AMD „odstránilo“ frekvenciu z názvu svojich procesorov a nahradilo ju nejakým abstraktným číslom, je dobre známy: po objavení sa procesora Intel Pentium 4, ktorý pracuje na veľmi vysokých frekvenciách, začali vedľa neho procesory AMD „vyzerať zle vo výklade“ - kupujúci neveril, že CPU s frekvenciou napríklad 1500 MHz môže predbehnúť CPU s frekvenciou 2000 MHz. Preto bola frekvencia v názve nahradená hodnotením. Formálna („de jure“, takpovediac) interpretácia tohto hodnotenia od AMD znela v rôznych časoch trochu inak, ale nikdy neznela v takej podobe, v akej ho vnímali používatelia: procesor AMD s určitým hodnotením by mal byť aspoň ako nie pomalší ako procesor Intel Pentium 4 s frekvenciou zodpovedajúcou tomuto hodnoteniu. Medzitým nebolo pre nikoho žiadnym zvláštnym tajomstvom, že práve táto interpretácia bola konečným cieľom zavedenia hodnotenia. Vo všeobecnosti každý všetko dokonale pochopil, ale AMD sa usilovne tvárilo, že to s tým nemá nič spoločné :). Netreba jej to vyčítať: v súťaži platia úplne iné pravidlá ako v rytierskych súbojoch. Výsledky nezávislých testov navyše ukázali: AMD vo všeobecnosti prideľuje svojim procesorom pomerne spravodlivé hodnotenie. V skutočnosti, pokiaľ je to tak, sotva má zmysel protestovať proti používaniu hodnotenia. Pravda, jedna otázka ostáva otvorená: na čo (samozrejme nás zaujíma de facto stav, a nie vysvetlivky marketingového oddelenia) sa bude hodnotenie procesorov AMD viazať o niečo neskôr, keď Intel začne vyrábať nejaké iný procesor namiesto Pentia 4?
Číslo procesora od Intelu
Čo si musíte hneď zapamätať: Číslo procesora (ďalej len PN) pre procesory Intel nie je hodnotenie. Nie hodnotenie výkonu, ani hodnotenie čohokoľvek iného. V skutočnosti je to jednoducho „položka“, riadková položka v zozname zásob, ktorej jediným účelom je zabezpečiť, aby sa riadok reprezentujúci jeden procesor líšil od riadku reprezentujúceho iného. V rámci série (prvá číslica PN) môžu ostatné dve číslice v zásade niečo povedať, ale vzhľadom na prítomnosť tabuliek, ktoré ukazujú úplnú zhodu medzi PN a skutočnými parametrami, nevidíme veľký zmysel zapamätať si, ktoré - to sú medziľahlé korešpondencie. Motivácia Intelu pre zavedenie PN (namiesto špecifikácie frekvencie CPU) je zložitejšia ako u AMD. Potreba zaviesť PN (ako to vysvetľuje samotný Intel) je primárne spôsobená tým, že dvaja hlavní konkurenti majú rozdielny prístup k otázke jedinečnosti názvu CPU. Napríklad pre AMD môže názov „Athlon 64 3200+“ znamenať štyri procesory s mierne odlišnými technické vlastnosti(ale s rovnakým „hodnotením“). Intel je toho názoru, že názov procesora musí byť jedinečný, a preto sa spoločnosť predtým musela „vyhýbať“ pridávaním rôznych písmen k hodnote frekvencie v názve, čo viedlo k zmätku. Teoreticky mala PN tento zmätok odstrániť. Je ťažké povedať, či bol cieľ dosiahnutý: napriek tomu zostal rad procesorov Intel pomerne zložitý. Na druhej strane je to nevyhnutné, pretože sortiment výrobkov je príliš veľký. Bez ohľadu na všetko ostatné sa však jeden de facto efekt určite dosiahol: teraz už len odborníci, ktorí problematike rozumejú, dokážu podľa mena procesora rýchlo a presne povedať „z pamäte“ o čo ide a aký bude jeho výkon v porovnaní s inými procesormi. CPU. aká je dobrá? Ťažko povedať. Radi by sme sa zdržali komentárov.
Meranie rýchlosti „v megahertzoch“ – ako je to možné?
To nie je v žiadnom prípade možné, pretože rýchlosť sa nemeria v megahertzoch, rovnako ako vzdialenosť sa nemeria v kilogramoch. Páni marketéri však už dávno pochopili, že vo verbálnom súboji fyzika a psychológa vždy vyhráva ten druhý – a bez ohľadu na to, kto má vlastne pravdu. Preto čítame o „ultrarýchlom 1066 MHz FSB“ a bolestne sa snažíme pochopiť, ako možno rýchlosť merať pomocou frekvencie. V skutočnosti, keďže sa takýto zvrátený trend zakorenil, musíte mať jasno v tom, čo to znamená. Máme na mysli nasledovné: ak „opravíme“ šírku zbernice na N bitov, potom jej priepustnosť bude skutočne závisieť od toho, na akej frekvencii zbernica pracuje a koľko dát je schopná preniesť za cyklus hodín. Na bežnej procesorovej zbernici s „jednou“ rýchlosťou (takouto zbernicou bol napríklad procesor Intel Pentium III) sa za jeden hodinový cyklus prenesie 64 bitov, teda 8 bajtov. Ak je teda prevádzková frekvencia zbernice 100 MHz (100 "000" 000 hodinových cyklov za sekundu), potom sa rýchlosť prenosu dát bude rovnať 8 bajtom * 100 "000" 000 hertzom ~= 763 megabajtov za sekundu (a ak sa počíta v „desatinných megabajtoch“, v ktorých je obvyklé uvažovať dátové toky, potom ešte krajšie - 800 megabajtov za sekundu). Ak teda zbernica DDR beží na rovnakej frekvencii 100 megahertzov, ktorá je schopná preniesť dvojnásobné množstvo dát v jednom hodinovom cykle, rýchlosť sa zvýši presne dvakrát. Preto by sa podľa paradoxnej logiky pánov marketérov mala táto zbernica volať „200 MHz“. A ak je to tiež zbernica QDR (Quad Data Rate), potom sa v skutočnosti ukáže ako „400 MHz“, pretože v jednom hodinovom cykle prenáša štyri dátové pakety. Hoci skutočná prevádzková frekvencia všetkých troch vyššie opísaných autobusov je rovnaká - 100 megahertzov. Takto sa „megahertz“ stal synonymom rýchlosti.
Zbernica QDR (so „štvornásobnou“ rýchlosťou), ktorá pracuje pri skutočnej frekvencii 266 megahertzov, sa teda magicky ukáže ako „1066 megahertz“. Číslo „1066“ v tomto prípade predstavuje skutočnosť, že jej priepustnosť je presne 4-krát väčšia ako priepustnosť „jednorýchlostnej“ zbernice pracujúcej na rovnakej frekvencii. Už ste zmätení?.. Zvyknite si! Toto nie je nejaká teória relativity, tu je všetko oveľa komplikovanejšie a zanedbané... Tu je však najdôležitejšie zapamätať si jednu jednoduchú zásadu: ak robíme takú zvrátenosť, ako je porovnávanie rýchlosti dvoch autobusov s navzájom „v megahertzoch“, potom musia mať rovnakú šírku. Inak to dopadá ako na jednom fóre, kde človek vážne tvrdil, že priepustnosť AGP2X („133 MHz“, ale 32-bitový zbernica) - vyššia ako šírka pásma FSB Pentia III 800 (skutočná frekvencia 100 MHz, šírka 64 bitov).
Niekoľko slov o niektorých pikantných vlastnostiach protokolov DDR a QDR
Ako už bolo spomenuté vyššie, v režime DDR sa cez zbernicu prenesie dvojnásobné množstvo informácií v jednom hodinovom cykle a v režime QDR je to štvornásobok. Je pravda, že v dokumentoch zameraných viac na glorifikáciu úspechov výrobcov ako na objektívne pokrytie reality, z nejakého dôvodu vždy zabudnú uviesť jedno malé „ale“: Režimy dvojnásobnej a štvornásobnej rýchlosti sú povolené len počas paketového prenosu dát. To znamená, že ak by sme si vyžiadali pár megabajtov z pamäte z adresy X na adresu Y, tak áno, tieto dva megabajty sa prenesú dvojnásobnou/štvornásobnou rýchlosťou. Samotná požiadavka na údaje sa však odosiela cez zbernicu „jednou“ rýchlosťou - Vždy ! Ak teda máme veľa požiadaviek a veľkosť odosielaných údajov nie je príliš veľká, množstvo údajov, ktoré „putujú“ po zbernici jednou rýchlosťou (a požiadavka sú tiež údaje), bude takmer rovná množstvu, ktoré sa prenáša dvojnásobnou alebo štvornásobnou rýchlosťou. Zdá sa, že nám nikto otvorene neklamal, zdá sa, že DDR a QDR naozaj fungujú, ale... ako sa hovorí v jednom starom vtipe: „buď niekomu ukradol kožuch, alebo mu niekto ukradol kožuch, ale niečo nie je v poriadku s kožuchom..." ;)
Veľký blokový procesor
Cache
Všeobecný popis a princíp činnosti
Všetky moderné procesory majú vyrovnávaciu pamäť (v angličtine - cache). Cache je špeciálny typ pamäte (hlavnou vlastnosťou, ktorá zásadne odlišuje vyrovnávaciu pamäť od RAM, je prevádzková rýchlosť), čo je druh „vyrovnávacej pamäte“ medzi radičom pamäte a procesorom. Táto vyrovnávacia pamäť slúži na zvýšenie rýchlosti práce s RAM. Ako? Teraz skúsme vysvetliť. Zároveň sme sa rozhodli opustiť prirovnania zaváňajúce materskou školou, ktoré sa často vyskytujú v populárnej literatúre na spracovateľskú tematiku (bazény spojené potrubím rôznych priemerov atď. atď.). Veď človek, ktorý dočítal článok až sem a nezaspal, zrejme znesie a „strávi“ čisto technické vysvetlenie, bez bazénov, mačiek a púpav.
Predstavte si teda, že máme veľa relatívne pomalej pamäte (nech je to RAM s veľkosťou 10 000 000 bajtov) a relatívne málo veľmi rýchlej pamäte (nech je to vyrovnávacia pamäť s veľkosťou len 1024 bajtov). Ako môžeme použiť tento nešťastný kilobajt na zvýšenie rýchlosti práce s celou pamäťou vo všeobecnosti? Tu by sa však malo pamätať na to, že údaje počas prevádzky programu spravidla nie sú bezmyšlienkovite hádzané z miesta na miesto - zmeniť. Načítali z pamäte hodnotu nejakej premennej, pridali k nej nejaké číslo a zapísali ju späť na to isté miesto. Pole sme spočítali, zoradili vzostupne a znova zapísali do pamäte. To znamená, že v jednom bode program nepracuje s celou pamäťou, ale spravidla s jej relatívne malým fragmentom. Aké riešenie sa ponúka samo? Správne: nahrajte tento fragment do „rýchlej“ pamäte, spracujte ho tam a potom ho zapíšte späť do „pomalej“ pamäte (alebo ho jednoducho odstráňte z vyrovnávacej pamäte, ak sa údaje nezmenili). Vo všeobecnosti presne takto funguje vyrovnávacia pamäť procesora: akékoľvek informácie načítané z pamäte končia nielen v procesore, ale aj vo vyrovnávacej pamäti. A ak sú znova potrebné rovnaké informácie (rovnaká adresa v pamäti), procesor najskôr skontroluje: je vo vyrovnávacej pamäti? Ak existuje, informácie sa prevezmú odtiaľ a prístup k pamäti vôbec nenastane. Podobne pri zápise: informácia, ak sa jej objem zmestí do vyrovnávacej pamäte, sa tam zapíše a až potom, keď procesor dokončí operáciu zápisu a začne vykonávať ďalšie príkazy, sú údaje zapísané do vyrovnávacej pamäte paralelne s prácou jadra procesora„pomaly vyložený“ do pamäte RAM.
Samozrejme, množstvo prečítaných a zapisovaných dát počas celej činnosti programu je oveľa väčšie ako veľkosť vyrovnávacej pamäte. Niektoré z nich preto treba z času na čas vymazať, aby sa do vyrovnávacej pamäte zmestili nové, relevantnejšie. Najjednoduchším známym mechanizmom na zabezpečenie tohto procesu je sledovanie času posledného prístupu k údajom umiestneným vo vyrovnávacej pamäti. Ak teda potrebujeme umiestniť nové údaje do vyrovnávacej pamäte a je už „plná kapacita“, kontrolér, ktorý spravuje vyrovnávaciu pamäť, sa pozrie na to, ku ktorému fragmentu vyrovnávacej pamäte sa nepristupovalo najdlhšie? Práve tento fragment je prvým kandidátom na „odchod“ a namiesto neho sa zaznamenávajú nové údaje, s ktorými je potrebné teraz pracovať. Vo všeobecnosti takto funguje mechanizmus ukladania do vyrovnávacej pamäte v procesoroch. Vyššie uvedené vysvetlenie je, samozrejme, veľmi primitívne; v skutočnosti je všetko ešte komplikovanejšie, ale dúfame, že ste dokázali získať všeobecnú predstavu o tom, prečo procesor potrebuje vyrovnávaciu pamäť a ako to funguje.
Aby bolo jasné, aká dôležitá je cache, uvedieme jednoduchý príklad: rýchlosť výmeny dát medzi procesorom Pentium 4 a jeho cache je viac ako 10-krát (!) vyššia ako rýchlosť jeho práce s pamäťou. V skutočnosti sú moderné procesory schopné pracovať na plnú kapacitu iba s vyrovnávacou pamäťou: akonáhle budú čeliť potrebe čítať dáta z pamäte, všetky ich vychvaľované megahertzy jednoducho začnú „ohrievať vzduch“. Opäť jednoduchý príklad: procesor vykoná najjednoduchšiu inštrukciu v jednom hodinovom cykle, to znamená, že za sekundu dokáže vykonať toto množstvo jednoduché pokyny, aká je jeho frekvencia (v skutočnosti ešte viac, ale to si necháme na neskôr...). Ale čakacia doba na dáta z pamäte môže byť v najhoršom prípade aj viac ako 200 cyklov! Čo robí procesor, kým čaká na potrebné dáta? Ale nerobí nič. Len tak stáť a čakať...
Viacúrovňové ukladanie do vyrovnávacej pamäte
Špecifický dizajn moderných procesorových jadier viedol k tomu, že systém vyrovnávacej pamäte v drvivej väčšine CPU musí byť viacúrovňový. Cache prvej úrovne (najbližšie k jadru) je tradične rozdelená na dve (zvyčajne rovnaké) polovice: vyrovnávaciu pamäť inštrukcií (L1I) a vyrovnávaciu pamäť údajov (L1D). Toto rozdelenie zabezpečuje takzvaná „harvardská architektúra“ procesora, ktorá je dnes najpopulárnejším teoretickým vývojom pre stavbu moderných CPU. V L1I sa teda akumulujú iba príkazy (s tým pracuje dekodér, pozri nižšie) a v L1D sa akumulujú iba dáta (tie následne spravidla končia vo vnútorných registroch procesora). „Nad L1“ je vyrovnávacia pamäť druhej úrovne - L2. Spravidla má väčší objem a je už „zmiešaný“ - nachádzajú sa tam príkazy aj údaje. L3 (tretia úroveň cache) spravidla úplne kopíruje štruktúru L2 a zriedka sa nachádza v moderných x86 CPU. L3 je najčastejšie ovocím kompromisu: použitím pomalšej a užšej zbernice môže byť veľmi veľká, ale zároveň rýchlosť L3 stále zostáva vyššia ako rýchlosť pamäte (aj keď nie taká vysoká ako vyrovnávacia pamäť L2). ). Algoritmus pre prácu s viacúrovňovou vyrovnávacou pamäťou sa však vo všeobecnosti nelíši od algoritmu pre prácu s jednoúrovňovou vyrovnávacou pamäťou, len pridáva ďalšie iterácie: najprv sa informácie hľadajú v L1, ak tam nie sú - v L2, potom - v L3 a až potom, ak nie je nájdená na jednej úrovni vyrovnávacej pamäte - sa pristupuje k hlavnej pamäti (RAM).
Dekodér
V skutočnosti exekučné jednotky všetkých moderných desktopových x86 procesorov... vôbec nepracujú s kódom v x86 štandarde. Každý procesor má svoj vlastný „vnútorný“ príkazový systém, ktorý nemá nič spoločné s príkazmi (teda „kódom“), ktoré prichádzajú zvonku. Vo všeobecnosti sú príkazy vykonávané jadrom oveľa jednoduchšie, primitívnejšie ako príkazy štandardu x86. Je to práve preto, aby procesor „navonok vyzeral“ ako CPU x86 a existuje taký blok ako dekodér: je zodpovedný za konverziu „externého“ kódu x86 na „interné“ príkazy vykonávané jadrom (v tomto pomerne často sa jeden príkaz x86 kódu prevedie na o niečo jednoduchší „interný“). Dekodér je veľmi dôležitou súčasťou moderného procesora: jeho rýchlosť určuje, ako konštantný bude tok príkazov prichádzajúcich do vykonávacích jednotiek. Nedokážu totiž pracovať s x86 kódom, takže to, či budú niečo robiť alebo budú nečinné, do veľkej miery závisí od rýchlosti dekodéra. Intel implementoval pomerne neobvyklý spôsob, ako urýchliť proces dekódovania príkazov v procesoroch architektúry NetBurst – pozri nižšie o vyrovnávacej pamäti Trace.
Vykonávacie (funkčné) zariadenia
Po prejdení všetkých úrovní vyrovnávacej pamäte a dekodéra sa príkazy konečne dostanú k tým blokom, pre ktoré bol celý tento chaos zorganizovaný: predvádzanie zariadení. V skutočnosti sú to vykonávacie zariadenia jediný potrebný prvok procesor. Môžete to urobiť bez vyrovnávacej pamäte - rýchlosť sa zníži, ale programy budú fungovať. Môžete to urobiť bez dekodéra - vykonávacie zariadenia budú zložitejšie, ale procesor bude stále fungovať. Predsa len, skoré x86 procesory (i8086, i80186, 286, 386, 486, Am5x86) si ako-tak poradili aj bez dekodéra. Bez vykonávacích zariadení sa to nezaobíde, pretože sú to tie, ktoré vykonávajú programový kód. Na prvý pohľad sa tradične delia na dve časti veľké skupiny: Aritmetické logické jednotky (ALU) a jednotky s pohyblivou rádovou čiarkou (FPU).
Aritmetické logické zariadenia
ALU sú tradične zodpovedné za dva typy operácií: aritmetické operácie (sčítanie, odčítanie, násobenie, delenie) s celými číslami, logické operácie s znova celými číslami (logické „a“, logické „alebo“, „výlučné alebo“ a podobne). Čo v skutočnosti vyplýva z ich názvu. V moderných procesoroch je spravidla niekoľko jednotiek ALU. Na čo - pochopíte neskôr, po prečítaní časti „Superskalarita a vykonávanie príkazov mimo poradia“. Je jasné, že ALU môže vykonávať len tie inštrukcie, ktoré sú na to určené. Špeciálny blok je zodpovedný za distribúciu príkazov prichádzajúcich z dekodéra do rôznych vykonávacích zariadení, ale to je, ako sa hovorí, „príliš zložité záležitosti“ a sotva má zmysel vysvetľovať ich v materiáli, ktorý je venovaný iba povrchnému oboznámeniu sa s základné princípy fungovania moderného x86 CPU.
Jednotka s pohyblivou rádovou čiarkou*
FPU je zodpovedný za vykonávanie príkazov, ktoré pracujú s číslami s pohyblivou rádovou čiarkou, okrem toho na ňom tradične „zavesia všetkých psov“ vo forme najrôznejších doplnkových súborov príkazov (MMX, 3DNow!, SSE, SSE2, SSE3.. .) - bez ohľadu na to, či pracujú s číslami s pohyblivou rádovou čiarkou alebo s celými číslami. Rovnako ako v prípade ALU môže byť v FPU niekoľko samostatných blokov, ktoré môžu pracovať paralelne.
* - podľa tradícií ruskej matematickej školy nazývame FPU „plávajúca výpočtová jednotka“ čiarka“, hoci doslova jeho názov (Plávajúci Bod Unit) sa prekladá ako „...s pohyblivou rádovou čiarkou“ - podľa amerického štandardu na písanie takýchto čísel.
Registre procesora
Registre sú v podstate rovnaké pamäťové bunky, ale „geograficky“ sú umiestnené priamo v jadre procesora. Samozrejme, rýchlosť práce s registrami je mnohonásobne väčšia ako rýchlosť práce s pamäťovými bunkami umiestnenými v hlavnej RAM (tu všeobecne rádovo...) a s cache akejkoľvek úrovne. Preto väčšina inštrukcií v architektúre x86 zahŕňa vykonávanie akcií špecificky s obsahom registrov, a nie s obsahom pamäte. Celkový objem registrov procesora je však spravidla veľmi malý - nedá sa ani porovnať s objemom vyrovnávacích pamätí prvej úrovne. Preto de facto kód programu (nie v jazyku vysoký stupeň, menovite binárny, „stroj“) často obsahuje nasledujúcu postupnosť operácií: načítať informácie z RAM do jedného z registrov procesora, načítať ďalšie informácie (aj z RAM) do iného registra, vykonať nejakú akciu s obsahom týchto registrov, umiestniť výsledok v treťom - a potom znova vytiahnite výsledok z registra do hlavnej pamäte.
Procesor v detailoch
Vlastnosti cache
Frekvencia vyrovnávacej pamäte a zbernica
Vo všetkých moderných procesoroch x86 pracujú všetky úrovne vyrovnávacej pamäte na rovnakej frekvencii ako jadro procesora, ale nie vždy to tak bolo (tento problém už bol spomenutý vyššie). Rýchlosť práce s vyrovnávacou pamäťou však nezávisí len od frekvencie, ale aj od šírky zbernice, ktorou je pripojená k jadru procesora. Ako si (dúfam) pamätáte z predchádzajúceho čítania, rýchlosť prenosu dát je v podstate súčinom frekvencie zbernice (počet hodinových cyklov za sekundu) a počtu bajtov, ktoré sa prenesú po zbernici v jednom hodinovom cykle. Počet bajtov prenesených za cyklus hodín možno zvýšiť zavedením protokolov DDR a QDR (Double Data Rate and Quad Data Rate) – alebo jednoducho zväčšením šírky zbernice. V prípade vyrovnávacej pamäte je druhá možnosť populárnejšia, v neposlednom rade kvôli „chutným funkciám“ DDR/QDR opísaným vyššie. Samozrejme, minimálna rozumná šírka zbernice cache je šírka externej zbernice samotného procesora, teda k dnešnému dňu - 64 bitov. Presne to robí AMD v duchu zdravého minimalizmu: v jeho procesoroch je šírka L1 L2 zbernice 64 bitov, no zároveň je obojsmerná, to znamená, že je schopná súčasne vysielať a prijímať informácie. . Intel opäť postupoval v duchu „zdravého gigantizmu“: vo svojich procesoroch, počnúc Pentiom III „Coppermine“, má zbernica L1 L2 šírku... 256 bitov! Podľa zásady „kaša sa nedá pokaziť maslom“, ako sa hovorí. Je pravda, že táto zbernica je jednosmerná, to znamená, že v jednom okamihu funguje buď len na vysielanie, alebo len na príjem. Debata o tom, ktorý prístup je lepší (obojsmerná zbernica, ale užšia, alebo jednosmerná zbernica) pokračuje dodnes... ale aj mnohé ďalšie spory ohľadom technických riešení, ktoré používajú dvaja hlavní konkurenti na trhu x86 CPU .
Exkluzívna a neexkluzívna vyrovnávacia pamäť
Koncepty exkluzívneho a neexkluzívneho ukladania do vyrovnávacej pamäte sú veľmi jednoduché: v prípade neexkluzívnej vyrovnávacej pamäte je možné duplikovať informácie na všetkých úrovniach ukladania do vyrovnávacej pamäte. L2 teda môže obsahovať dáta, ktoré sú už v L1I a L1D, a L3 (ak existuje) môže obsahovať úplnú kópiu celého obsahu L2 (a teda L1I a L1D). Exkluzívna vyrovnávacia pamäť, na rozdiel od neexkluzívnej, poskytuje jasné rozlíšenie: ak sú informácie obsiahnuté na určitej úrovni vyrovnávacej pamäte, potom nie sú prítomné na žiadnej inej úrovni. Výhoda exkluzívnej cache je zrejmá: celková veľkosť cache informácií sa v tomto prípade rovná celkovému objemu cache všetkých úrovní – na rozdiel od neexkluzívnej cache, kde je veľkosť cache informácií (v najhoršom prípade ) sa rovná objemu najväčšej úrovne vyrovnávacej pamäte. Nevýhoda exkluzívnej vyrovnávacej pamäte je menej zrejmá, ale existuje: je potrebný špeciálny mechanizmus, ktorý monitoruje skutočnú „exkluzivitu“ (napríklad pri vymazávaní informácií z vyrovnávacej pamäte L1 sa pred tým automaticky spustí proces ich kopírovania do L2). ).
Neexkluzívnu vyrovnávaciu pamäť tradične používa Intel, exkluzívnu (od nástupu procesorov Athlon založených na jadre Thunderbird) používa AMD. Vo všeobecnosti tu vidíme klasickú konfrontáciu medzi objemom a rýchlosťou: vďaka exkluzivite pri rovnakých objemoch L1/L2 získava AMD väčšiu celkovú veľkosť informácií vo vyrovnávacej pamäti – vďaka tomu však funguje aj pomalšie (oneskorenia spôsobené prítomnosťou mechanizmus exkluzivity). Asi treba podotknúť, že Intel v poslednom čase kompenzuje nedostatky neexkluzívnej cache jednoduchým, hlúpym, no výrazným spôsobom: zvyšovaním jej objemu. Pre špičkové procesory tejto spoločnosti sa 2 MB L2 cache stala takmer štandardom - a AMD so svojimi 128 KB L1C+L1D a maximálne 1 MB L2 tieto 2 MB ešte „neprekonalo“ ani kvôli exkluzivite. .
Okrem toho zvýšenie celkového objemu informácií uložených vo vyrovnávacej pamäti zavedením exkluzívnej architektúry vyrovnávacej pamäte má zmysel len vtedy, ak je nárast objemu pomerne veľký. A m. Pre AMD je to relevantné, pretože... jeho súčasné CPU majú celkový objem L1D+L1I 128 KB. Pre procesory Intel, ktorých objem L1D je maximálne 32 KB a L1I má niekedy úplne inú štruktúru (pozri o vyrovnávacej pamäti Trace), by zavedenie exkluzívnej architektúry prinieslo oveľa menší prínos.
Existuje tiež všeobecná mylná predstava, že architektúra vyrovnávacej pamäte procesorov Intel je „inkluzívna“. Nie naozaj. NIE JE exkluzívny. Inkluzívna architektúra to poskytuje na „nižšej“ úrovni vyrovnávacej pamäte nemôže nie je nič, čo by nebolo na „vyššom“. Nie exkluzívna architektúra priznáva duplikácia údajov na rôznych úrovniach.
Trace cache
Koncept Trace cache je ukladať do prvej úrovne inštrukcií cache (L1I) nie tie inštrukcie, ktoré sa čítajú z pamäte, ale už dekódované sekvencie (pozri dekodér). Ak sa teda určitá inštrukcia x86 vykonáva opakovane a stále je v L1I, procesorový dekodér ju nemusí znova konvertovať na sekvenciu inštrukcií „interného kódu“, keďže L1I túto sekvenciu obsahuje v už dekódovanej forme. Koncept Trace cache veľmi dobre zapadá do všeobecného konceptu architektúry Intel NetBurst, ktorá je zameraná na vytváranie procesorov s veľmi vysokými frekvenciami jadra. Avšak užitočnosť Trace cache pre [relatívne] CPU s nižšou frekvenciou je stále otázna, pretože zložitosť organizácie Trace cache sa stáva porovnateľnou s úlohou navrhnúť konvenčný rýchly dekodér. Preto, aj keď vzdávame hold originalite nápadu, stále by sme povedali, že Trace cache nemožno považovať za univerzálne riešenie „pre všetky príležitosti“.
Superskalarita a vykonávanie inštrukcií mimo poradia
Hlavnou črtou všetkých moderných procesorov je, že sú schopné spustiť vykonávanie nielen príkazu, ktorý má byť (podľa programového kódu) v danom čase vykonaný, ale aj ďalších po ňom nasledujúcich. Uveďme si jednoduchý (kanonický) príklad. Vykonajme nasledujúcu postupnosť príkazov:
1) A = B + C
2) Z = X + Y
3) K = A + Z
Je ľahké vidieť, že príkazy (1) a (2) sú od seba úplne nezávislé - nepretínajú sa ani v zdrojových údajoch (premenné B a C v prvom prípade, X a Y v druhom), ani v umiestnenie výsledku (premenná A v v prvom prípade a Z v druhom prípade). Preto, ak v súčasnosti máme viac ako jeden voľný vykonávací blok, tieto príkazy môžu byť rozdelené medzi ne a vykonávané súčasne, a nie postupne*. Ak teda vezmeme čas vykonania každého príkazu rovný N cyklov procesora, potom by v klasickom prípade vykonanie celej sekvencie trvalo N*3 hodinových cyklov a v prípade paralelného vykonania iba N*2 hodinových cyklov. (keďže príkaz (3) nie je možné vykonať bez čakania na výsledok predchádzajúcich dvoch).
* - miera paralelizmu samozrejme nie je nekonečná: príkazy je možné vykonávať paralelne iba vtedy, ak je v danom čase k dispozícii primeraný počet voľných blokov (FU), a presne tí, ktorí „rozumejú“ príslušným príkazom. Najjednoduchší príklad: blok patriaci ALU nie je fyzicky schopný vykonať inštrukciu určenú pre FPU. Platí to aj naopak.
V skutočnosti je to ešte komplikovanejšie. Ak teda máme nasledujúcu postupnosť:
1) A = B + C
2) K = A + M
3) Z = X + Y
Potom sa zmení front vykonávania príkazov procesora! Keďže príkazy (1) a (3) sú na sebe nezávislé (ani v zdrojových údajoch, ani v umiestnení výsledku), môžu sa vykonávať paralelne – a budú sa vykonávať paralelne. Príkaz (2) sa však vykoná až po nich (tretí) - keďže na to, aby bol výsledok výpočtu správny, je potrebné, aby sa pred ním vykonal príkaz (1). Preto sa mechanizmus diskutovaný v tejto časti nazýva „vykonanie príkazov mimo poradia“ (vykonanie mimo poradia alebo skrátene „OoO“): v prípadoch, keď poradie vykonania nemôže žiadnym spôsobom ovplyvniť Výsledkom je, že príkazy sa odosielajú na vykonanie v nesprávnom poradí, v poradí, v akom sa nachádzajú v programovom kóde, ale v takom, ktoré umožňuje dosiahnuť maximálny výkon.
Teraz by vám malo byť konečne jasné, prečo moderné CPU potrebujú toľko vykonávacích jednotiek rovnakého typu: poskytujú možnosť paralelného vykonávania niekoľkých príkazov, ktoré by sa v prípade „klasického“ prístupu k návrhu procesora museli vykonávať. v poradí, v akom sú obsiahnuté zdrojový kód, jeden po druhom.
Procesory vybavené mechanizmom na paralelné vykonávanie niekoľkých po sebe idúcich inštrukcií sa zvyčajne nazývajú „superskalárne“. Nie všetky superskalárne procesory však podporujú spustenie mimo poradia. V prvom príklade nám teda stačí „jednoduchá superskalarita“ (vykonávanie dvoch po sebe idúcich príkazov súčasne) – ale v druhom príklade sa bez preskupenia príkazov nezaobídeme, ak chceme dosiahnuť maximálny výkon. Všetky moderné x86 CPU majú obe vlastnosti: sú superskalárne a podporujú vykonávanie inštrukcií mimo poradia. Zároveň v histórii x86 existovali aj „jednoduché superskaláry“, ktoré nepodporovali OoO. Napríklad klasický desktopový x86 superskalár bez OoO bol Intel Pentium.
Aby sme boli spravodliví, stojí za zmienku, že ani Intel, ani AMD, ani žiadny iný (vrátane už zosnulých) x86 CPU výrobca nemá žiadnu zásluhu na vývoji konceptov superskalarity a OoO. Prvý superskalárny počítač podporujúci OoO vyvinul Seymour Cray už v 60. rokoch 20. storočia. Pre porovnanie: Intel vydal svoj prvý superskalárny procesor (Pentium) v roku 1993, prvý superskalár s OoO (Pentium Pro) - v roku 1995; Prvý OoO superskalár (K5) od AMD bol vydaný v roku 1996. Komentáre, ako sa hovorí, sú zbytočné...
Predbežné (predbežné) dekódovanie
a ukladanie do vyrovnávacej pamäte
Predikcia pobočky
Každý viac či menej zložitý program obsahuje príkazy podmieneného skoku: „Ak je určitá podmienka pravdivá, prejdite na vykonanie jednej časti kódu, ak nie, prejdite na inú. Z pohľadu rýchlosti vykonávania programového kódu moderným procesorom, ktorý podporuje vykonávanie mimo poradia, je každý príkaz podmieneného skoku skutočne božou metlou. Koniec koncov, kým nie je známe, ktorá časť kódu po podmienenom skoku bude „relevantná“, nie je možné ho začať dekódovať a vykonávať (pozri vykonávanie mimo poradia). Aby sa nejako zosúladil koncept vykonávania mimo poradia s príkazmi podmieneného skoku, je určený špeciálny blok: blok predikcie vetvenia. Ako už názov napovedá, v podstate sa zaoberá „proroctvami“: pokúša sa predpovedať, na ktorú časť kódu bude príkaz podmieneného skoku ukazovať, a to ešte pred jeho vykonaním. V súlade s pokynmi „bežného vnútrojadrového proroka“ procesor vykonáva veľmi skutočné akcie: „prorokovaná“ časť kódu sa načíta do vyrovnávacej pamäte (ak tam nie je) a dokonca začne dekódovať a vykonávať svoje príkazy. . Okrem toho medzi vykonávanými príkazmi môžu byť aj pokyny podmieneného skoku a ich výsledky sú tiež predpovedané, čo generuje celý reťazec zatiaľ neoverené predpovede! Samozrejme, ak je jednotka predikcie vetvy nesprávna, všetka práca vykonaná v súlade s jej predpoveďami sa jednoducho zruší.
Algoritmy používané jednotkou na predikciu vetiev v skutočnosti vôbec nie sú majstrovskými dielami umelej inteligencie. Väčšinou sú jednoduché... a hlúpe. Pretože príkaz podmieneného skoku sa najčastejšie nachádza v slučkách: určité počítadlo nadobudne hodnotu X a po každom prechode slučky sa hodnota počítadla zníži o jednotku. V súlade s tým, pokiaľ je hodnota počítadla väčšia ako nula, vykoná sa prechod na začiatok slučky a potom, čo sa rovná nule, vykonávanie pokračuje ďalej. Blok predikcie vetvenia jednoducho analyzuje výsledok vykonania príkazu podmieneného skoku a verí, že ak N-krát za sebou je výsledkom skok na určitú adresu, potom sa v N+1 prípadoch vykoná skok na rovnakú adresu. Napriek všetkému primitivizmu však táto schéma funguje dobre: napríklad, ak počítadlo nadobudne hodnotu 100 a „prah operácie“ prediktora vetvy (N) sa rovná dvom prechodom v rade na rovnakú adresu - je ľahké vidieť, že 97 prechodov z 98 bude predpovedaných správne!
Samozrejme, napriek pomerne vysokej účinnosti jednoduchých algoritmov sa mechanizmy predikcie vetvenia v moderných CPU stále zdokonaľujú a stávajú sa zložitejšími - tu však hovoríme o boji o jednotky percent: napríklad o zvýšenie účinnosti jednotka predikcie vetvy z 95 percent na 97, alebo dokonca z 97 % na 99...
Predbežné načítanie údajov
Blok predvýberu dát (Prefetch) je princípom fungovania veľmi podobný bloku predikcie vetvy – rozdiel je len v tom, že v tomto prípade nehovoríme o kóde, ale o dátach. Všeobecný princíp činnosti je rovnaký: ak vstavaný obvod analýzy prístupu k údajom v RAM rozhodne, že sa čoskoro sprístupní určitá pamäťová časť, ktorá ešte nebola načítaná do vyrovnávacej pamäte, vydá príkaz na načítanie tejto pamäťovej časti do vyrovnávaciu pamäť ešte skôr, ako ju bude potrebovať spustiteľný program. „Inteligentne“ (efektívne) fungujúca jednotka predbežného vyzdvihnutia môže výrazne skrátiť čas prístupu k požadovaným údajom, a teda zvýšiť rýchlosť vykonávania programu. Mimochodom: kompetentný Prefetch veľmi dobre kompenzuje vysokú latenciu pamäťového subsystému, načítava potrebné údaje do vyrovnávacej pamäte, a tým vyrovnáva oneskorenia pri prístupe k nim, ak nie sú vo vyrovnávacej pamäti, ale v hlavnej RAM. .
V prípade chyby v jednotke prefetch dát sa však samozrejme nevyhneme negatívnym dôsledkom: Načítaním de facto “nepotrebných” dát do cache, Prefetch z nej vytesní ďalšie (možno len tie, ktoré sú potrebné). Navyše „predvídaním“ operácie čítania vzniká dodatočná záťaž pamäťového radiča (de facto v prípade chyby úplne zbytočná).
Algoritmy predbežného načítania, podobne ako algoritmy bloku predikcie vetvy, tiež nežiaria inteligenciou: spravidla sa tento blok snaží sledovať, či sa informácie čítajú z pamäte s určitým „krokom“ (podľa adresy), a na základe tejto analýzy , snaží sa predpovedať, z akej adresy sa budú dáta čítať pri ďalšej činnosti programu. Rovnako ako v prípade bloku predikcie vetvy však jednoduchosť algoritmu vôbec neznamená nízku efektivitu: v priemere blok predbežného načítania údajov „útočí“ častejšie, ako robí chyby (a to ako v predchádzajúcom prípade , je primárne spôsobené tým, že „masívne“ čítanie údajov z pamäte sa spravidla vyskytuje počas vykonávania rôznych cyklov).
Záver
Som ten králik, ktorý nemôže začať žuť trávu, kým...
nepochopí do všetkých detailov, ako prebieha proces fotosyntézy!
(vyjadrenie osobného postoja jedného z autorových blízkych priateľov)
Je dosť možné, že pocity, ktoré ste mali po prečítaní tohto článku, sa dajú opísať približne takto: „Namiesto toho, aby som prstami vysvetľoval, ktorý procesor je lepší, zobrali a zaťažili môj mozog kopou konkrétnych informácií, ktoré treba ešte pochopiť. a pochopil, a koniec nie je v dohľade!" Úplne normálna reakcia: ver mi, dobre ti rozumieme. Povedzme si ešte viac (a nech vám spadne koruna z hlavy!): ak si myslíte, že na túto jednoduchú otázku („ktorý procesor je lepší?“) dokážeme odpovedať sami, tak sa veľmi mýlite. nemôžem. Pre niektoré úlohy je lepší jeden, pre iné - iný a potom je iná cena, dostupnosť, obľúbenosť konkrétneho používateľa pre určité značky... Problém nemá jednoznačné riešenie. Keby áno, určite by ho niekto našiel a stal by sa najznámejším pozorovateľom v histórii nezávislých skúšobní.
Chcel by som ešte raz zdôrazniť: Aj keď ste úplne asimilovali a pochopili všetky informácie uvedené v tomto materiáli, stále nebudete môcť predpovedať, ktorý z týchto dvoch procesorov bude vo vašich úlohách rýchlejší, ak sa pozriete iba na ich vlastnosti.. Po prvé, pretože tu nie sú zohľadnené všetky vlastnosti procesorov. Po druhé, pretože existujú aj parametre CPU, ktoré je možné prezentovať len v numerickej forme s veľmi veľkým rozsahom. Takže pre koho (a pre čo) je toto všetko napísané? Predovšetkým - pre tých istých „králikov“, ktorí určite chcú vedieť, čo sa deje vo vnútri zariadení, ktoré každý deň používajú. Prečo? Možno sa len cítia lepšie, keď vedia, čo sa okolo nich deje? :)
V blízkej budúcnosti sa plánuje rozšírenie FAQ:
- Časť venovaná viacprocesorovým systémom: vysvetlenie pojmu SMP, technológia Hyper-Threading, N-processing, N-core.
- Časť venovaná fyzicka charakteristika CPU: typy puzdier, zásuvky, spotreba energie atď.
Dnes už nikoho neprekvapí, že obľúbená rodinná fotografia, uložená a chránená pred zákernými prekvapeniami v podobe napríklad vody od nešťastných susedov na najvyššom poschodí, ktorí zabudli zavrieť kohútik, môže predstavovať nejaký druh nezrozumiteľnej množiny čísel a zároveň zostávajú rodinnou fotografiou. Domáci počítač sa stala takou samozrejmosťou ako „škatuľka“ s modrou obrazovkou. Nebol by som prekvapený, keby sa čoskoro domáci počítač považoval za rovnocenný s domácimi elektrickými spotrebičmi. Mimochodom, „motor pokroku“, ktorý pozná každý, je to, čo nám Intel prorokuje a podporuje myšlienku digitálnej domácnosti.
Osobný počítač si teda našiel svoje miesto vo všetkých sférach ľudského života. Jeho vzhľad a vznik ako integrálneho prvku spôsobu života sa už stal históriou. Keď hovoríme o PC, máme na mysli systémy kompatibilné s IBM PC, a to celkom správne. Máloktorý čitateľ niekedy na vlastné oči videl systém, ktorý nie je kompatibilný s počítačmi IBM, a tým menej používaný.
Všetky IBM PC a kompatibilné počítače sú založené na procesoroch x86. Úprimne, niekedy sa mi zdá, že nejde len o architektúru procesora, ale aj o architektúru celého PC, ako ideológiu štruktúry systému ako celku. Ťažko povedať, kto koho ťahal so sebou, či sa vývojári periférnych zariadení a finálnych produktov prispôsobili architektúre x86, alebo naopak priamo či nepriamo formovali vývojovú cestu x86 procesorov. História x86 nie je hladká asfaltová cesta, ale súbor vývojárskych krokov rôzneho stupňa závažnosti a geniality, ktoré sú silne prepojené s ekonomickými faktormi. Znalosť histórie x86 procesorov nie je vôbec potrebná. Porovnávať procesora dnešnej reality s jeho dávnymi predkami je jednoducho zbytočné. Aby sme však mohli sledovať všeobecné vývojové trendy a pokúsiť sa urobiť predpoveď, je potrebný exkurz do historickej minulosti architektúry x86. Samozrejme, seriózne historické dielo môže zabrať viac ako jeden zväzok a je zbytočné si nárokovať objektívne a široké pokrytie danej témy. Preto sa nebudeme zaoberať peripetiami „životnosti“ každej generácie procesorov x86, ale obmedzíme sa na najdôležitejšie udalosti v celom epose x86.
1968
Štyria zamestnanci Fairchild Semiconductor: Bob Noyce, manažér a vynálezca integrovaného obvodu v roku 1959, Gordon Moore, ktorý viedol výskum a vývoj, Andy Grove, špecialista na chemické inžinierstvo, a Arthur Rock, ktorý poskytoval finančnú podporu, založili Intel. Tento názov je odvodený od Integral Electronic.
1969
Bývalý riaditeľ marketingového oddelenia Fairchild Semiconductor Jerry Sanders a niekoľko jeho podobne zmýšľajúcich ľudí založili spoločnosť AMD (Advanced Micro Devices), ktorá začala vyrábať mikroelektronické zariadenia.
1971
Pri plnení jednej z objednávok na čipy RAM navrhol zamestnanec Intelu Ted Hoff vytvorenie univerzálneho „inteligentného“ integrovaného obvodu. Vývoj viedol Federico Fagin. V dôsledku toho sa zrodil prvý mikroprocesor Intel 4004.
1978
Celé obdobie pred tým je prehistóriou, hoci je neoddeliteľné od udalostí, ktoré sa stali potom. Tento rok sa začala éra x86 – Intel vytvoril mikroprocesor i8086, ktorý mal frekvencie 4,77,8 a 10 MHz. Smiešne frekvencie? Áno, toto sú frekvencie moderných kalkulačiek, ale tu sa to všetko začalo. Čip bol vyrobený 3-μm technológiou a mal interný 16-bitový dizajn a 16-bitovú zbernicu. To znamená, že sa objavila 16-bitová podpora a následne 16-bitové operačné systémy a programy.
O niečo neskôr, v tom istom roku, bol vyvinutý i8088, ktorého hlavným rozdielom bola 8-bitová externá dátová zbernica, zaisťujúca kompatibilitu s predtým používaným 8-bitovým hardvérom a pamäťou. Argumentom v jeho prospech bola aj jeho kompatibilita s i8080/8085 a Z-80 a relatívne nízka cena. Nech je to akokoľvek, IBM si vybralo i8088 ako CPU pre svoje prvé PC. Odvtedy sa procesor Intel stane neoddeliteľnou súčasťou osobný počítač a samotný počítač sa bude dlho volať IBM PC.
 |
1982
i80286 oznámil. „Dvestosemdesiaty šiesty“ sa stal prvým procesorom x86, ktorý prenikol do sovietskeho a postsovietskeho priestoru veľké množstvo. Hodinové frekvencie 6, 8, 10 a 12 MHz, vyrobené 1,5-μm procesnou technológiou a obsahovali asi 130 000 tranzistorov. Tento čip mal plnú 16-bitovú podporu. Prvýkrát, s príchodom i80286, sa objavil taký koncept ako „chránený režim“, ale potom vývojári softvéru nevyužili jeho schopnosti naplno. Procesor dokázal prepnutím do chráneného režimu adresovať viac ako 1 MB pamäte, no po úplnom reštarte bolo možné vrátiť sa späť a segmentovaná organizácia prístupu do pamäte si vyžadovala značné dodatočné úsilie pri písaní programového kódu. To viedlo k tomu, že i80286 sa používal skôr ako rýchly i8086.
 |
Výkon čipu v porovnaní s 8086 (a najmä v porovnaní s i8088) sa niekoľkonásobne zvýšil a dosiahol 2,6 milióna operácií za sekundu. V tých rokoch začali výrobcovia aktívne využívať otvorenú architektúru IBM PC. Zároveň sa začalo obdobie klonovania x86 procesorov od Intelu výrobcami tretích strán. Čip bol vyrobený inými spoločnosťami ako presná kópia. Intel 80286 sa stal základom najnovšieho PC podľa týchto štandardov, IBM PC/AT a jeho početných klonov. Hlavnými výhodami nového procesora boli zvýšená produktivita a ďalšie režimy adresovania. A čo je najdôležitejšie - kompatibilita s existujúcim softvérom. Procesor bol samozrejme licencovaný aj výrobcami tretích strán...
V tom istom roku AMD uzavrelo licenčnú zmluvu s Intelom a na jej základe začalo s výrobou klonov x86 procesorov.
1985
Tento rok sa odohrala azda najvýznamnejšia udalosť v histórii procesorov s architektúrou x86 – Intel vydal prvý procesor i80386. Dalo by sa povedať, že to bolo revolučné: 32-bitový multitaskingový procesor so schopnosťou súčasne vykonávať niekoľko programov. V podstate väčšina moderných procesorov nie je nič iné ako rýchle 386-ky. Moderný softvér používa rovnakú architektúru 386, len moderné procesory robia to isté, len rýchlejšie. Intel 386™ bol veľkým vylepšením oproti i8086 a i80286. V podstate väčšina moderných procesorov nie je nič iné ako rýchle 386-ky. Moderný softvér používa rovnakú architektúru 386, len moderné procesory robia to isté, len rýchlejšie. Intel 386™ bol veľkým vylepšením oproti i8086 a i80286. Intel 386™ výrazne zlepšil správu pamäte v porovnaní s i80286 a vstavané možnosti multitaskingu umožnili vývoj operačný systém Microsoft Windows a OS/2.
 |
Na rozdiel od i80286 sa Intel 386™ mohol voľne prepínať z chráneného režimu do reálneho režimu a späť a mal nový režim – virtuálny 8086. V tomto režime mohol procesor vykonávať niekoľko rôznych softvérových vlákien súčasne, pretože každé z nich bežalo na izolované „virtuálne“ 86. auto. Procesor zaviedol ďalšie režimy adresovania pamäte s variabilnou dĺžkou segmentu, čo výrazne zjednodušilo tvorbu aplikácií. Procesor bol vyrobený 1-mikrónovým technologickým procesom. Prvýkrát bol procesor Intel predstavený v niekoľkých modeloch, ktoré tvorili rodinu 386. Tu začína slávna marketingová hra Intelu, ktorá neskôr vyústila do rozdelenia jedného vyvinutého jadra na dva komerčné varianty, nazývané v určitom okruhu používateľov a špecialistov: „Pentium pre bohatých, Celeron pre chudobných“. Aj keď je tu zlé, že vlci sú dobre kŕmení a ovce sú v bezpečí.
Boli vydané nasledujúce modely:
386DX na 16, 20, 25 a 33 MHz mal 4 GB adresovateľnej pamäte;
386SX s frekvenciou 16, 20, 25 a 33 MHz mal na rozdiel od 386DX skôr 16-bitovú ako 32-bitovú dátovú zbernicu a podľa toho 16 MB adresovateľnej pamäte (podobným spôsobom bol svojho času procesor i8088 „vytvorené“ z i8086 zmenšením bitovej šírky externej zbernice, aby sa zabezpečila kompatibilita s existujúcimi externými zariadeniami);
386SL v októbri 1990 - mobilná verzia Procesor Intel 386SX s frekvenciou 20 a 25 MHz.
1989
Spoločnosť Intel Corporation uvádza na trh svoj ďalší procesor – Intel 486™ DX s frekvenciami 25, 33 a 50 MHz. Intel 486™ DX bol prvým procesorom v rodine 486 a mal výrazný (viac ako 2x pri rovnakej frekvencii) zvýšenie výkonu v porovnaní s rodinou 386. Pridal 8 KB L1 cache integrovanú do čipu a maximálnu veľkosť L2 -cache zvýšená na 512 Kb. Model i486DX integroval jednotku s pohyblivou rádovou čiarkou (FPU – Floating Point Unit), ktorá predtým fungovala ako externý matematický koprocesor nainštalovaný na základnej doske. Navyše ide o prvý procesor, ktorého jadro obsahovalo päťstupňovú pipeline. Príkaz, ktorý prešiel prvou fázou potrubia, zatiaľ čo pokračoval v spracovaní v druhej, uvoľnil prvý podľa pokynov. Vo svojom jadre bol procesor Intel 486™DX rýchly Intel 386DX™ kombinovaný s matematickým koprocesorom a 8 KB vyrovnávacej pamäte na jednom čipe. Táto integrácia umožnila zvýšiť rýchlosť komunikácie medzi blokmi na veľmi vysoké hodnoty.
Intel spustil reklamnú kampaň so sloganom „Intel: The Computer Inside“. Čas uplynie a zmení sa na slávnu reklamnú kampaň „Intel Inside“.
 |
1991
Bol vytvorený vlastný procesor AMD - Am386™. Tento bol postavený čiastočne na základe licencie a čiastočne podľa vlastného návrhu a bežal na maximálnej frekvencii 40 MHz, ktorá bola vyššia ako u procesora Intel.
O niečo skôr sa medzi Intelom a AMD uskutočnilo prvé súdne konanie týkajúce sa zámeru AMD predať svoj klon Intel 386™. Po pevnom posilnení svojej pozície Intel už nepotreboval distribuovať licencie výrobcom tretích strán a nemienil sa s nikým deliť o svoj vlastný koláč. V dôsledku toho spoločnosť AMD prvýkrát vstúpila na trh procesorov x86 ako konkurent. Ostatné spoločnosti nasledovali príklad. Tak sa začala veľká konfrontácia medzi týmito dvoma gigantmi, ktorá trvá dodnes (ostatní súťažiaci vypadli), ktorá dala svetu veľa dobrého. Nevyslovený slogan Konkurenti Intelu sa stala fráza: „rovnaké ako Intel, ale za nižšiu cenu“.
Intel zároveň vydáva i486SX, v ktorom pre zníženie ceny produktu chýba FPU jednotka (integrovaný koprocesor), čo sa samozrejme negatívne odrazilo na výkone. Neboli žiadne iné rozdiely oproti i486DX.
 |
1992
S uvedením procesora Intel 486DX2 bol prvýkrát použitý multiplikačný faktor frekvencie zbernice. Až do tohto bodu sa frekvencia vnútorného jadra rovnala frekvencii externej dátovej zbernice (FSB), ale nastal problém s jej zvýšením, keďže lokálne periférne zbernice (v tom čase VESA VL-bus) a dokonca aj periférií vykazovali nestabilitu pri frekvenciách nad 33 MHz. Teraz pri frekvencii zbernice FSB 33 MHz bola frekvencia taktovania jadra 66 MHz kvôli násobeniu 2. Táto technika sa zapísala do histórie na dlhú dobu a používa sa dodnes, len násobič v moderných CPU môže prekročiť 20. Intel 486™ DX2 sa stal populárnym procesorom na dlhú dobu a predával sa v obrovských množstvách, no podobne ako jeho klony od konkurentov (AMD, Cyrix a iné), ktoré už mali určité rozdiely od „originálu Intelu“.
 |
1993
Bol vydaný prvý superskalárny procesor x86, ktorý je schopný vykonať viac ako jednu inštrukciu za cyklus hodín - Pentium (kódové označenie P5). To sa dosiahlo dvoma nezávislými paralelne bežiacimi dopravníkmi. Prvé procesory mali frekvencie 60 a 66 MHz a prijímali 64-bitovú dátovú zbernicu. Po prvýkrát bola vyrovnávacia pamäť L1 rozdelená na dve časti: oddelenú pre inštrukcie a dáta. Ale jednou z najvýznamnejších inovácií bola úplne aktualizovaná jednotka s pohyblivou rádovou čiarkou (FPU). V skutočnosti predtým na platforme x86 nebol taký výkonný FPU a až mnoho rokov po vydaní Intel Pentium boli konkurenti schopní dosiahnuť jeho úroveň výkonu. Do procesora bol tiež po prvýkrát zahrnutý blok predikcie vetvenia, ktorý odvtedy inžinieri aktívne vyvíjali.
Pointa je toto: v každom programe existuje veľa podmienených prechodov, keď v závislosti od podmienky musí spustenie programu ísť jednou alebo druhou cestou. Do potrubia môže byť umiestnená iba jedna z niekoľkých vetiev prechodu a ak skončí naplnená kódom z nesprávnej vetvy, musí sa vyčistiť a znova naplniť niekoľko hodinových cyklov (v závislosti od počtu fáz potrubia) . Na vyriešenie tohto problému sa používajú mechanizmy predikcie vetvenia. Procesor obsahoval 3,1 milióna tranzistorov a bol vyrobený 0,8-μm procesom. Všetky tieto zmeny umožnili zdvihnúť výkon nového procesora do nedosiahnuteľných výšin. V skutočnosti bola optimalizácia kódu „pre procesor“ spočiatku zriedkavá a vyžadovala si použitie špeciálnych kompilátorov. A na najnovšom procesore museli dlho spúšťať programy určené pre procesory rodiny 486 a 386.
V tom istom roku sa na jadre P54 objavila druhá generácia Pentia, v ktorej boli odstránené všetky nedostatky P5. Pri výrobe boli použité nové technologické postupy 0,6, neskôr 0,35-μm. Do roku 1996 pokrýval nový procesor taktovacie frekvencie od 75 do 200 MHz.
Prvé Pentium zohralo dôležitú úlohu pri prechode na nové úrovne výkonu osobného počítača, dalo impulz a stanovilo smernicu vývoja do budúcnosti. No napriek veľkému výkonnostnému skoku nepriniesol žiadne zásadné zmeny do x86 architektúry.
1994
Vznikajúce Intel 486™DX4, AMD Am486DX4 a Cyrix 4x86 pokračovali v rade 486 a využívali násobenie frekvencie dátovej zbernice. Procesory mali strojnásobenie frekvencií. Procesory Intel DX4 pracovali na frekvenciách 75 a 100 MHz a AMD Am486DX4 dosahovali 120 MHz. Systémy správy napájania sa stali široko používanými v procesoroch. Žiadne ďalšie zásadné rozdiely oproti 486DX2 neboli.
1995
Pentium Pro (jadro P6) ohlásené. Nová zbernica procesora, tri nezávislé pipeline, optimalizácia pre 32-bitový kód, od 256 Kb do 1 Mb L2 cache integrovaná v procesore, pracujúca na frekvencii jadra, vylepšený mechanizmus predikcie vetvenia - podľa počtu inovácií nový procesor takmer prekonal rekordy, ktoré predtým stanovilo Intel Pentium.
 |
Procesor bol umiestnený na použitie v serveroch a mal veľmi vysokú cenu. Najpozoruhodnejšie je, že výpočtové jadro Pentium Pro v skutočnosti nebolo jadrom architektúry x86. Strojové kódy x86 vstupujúce do CPU boli interne dekódované do mikrokódu podobného RISC a toto vykonávalo jadro procesora. Inštrukčná sada CISC, podobne ako inštrukčná sada procesora x86, znamenala premenlivú dĺžku inštrukcie, ktorá určovala obtiažnosť nájdenia každej jednotlivej inštrukcie v prúde, a preto spôsobovala ťažkosti pri vývoji programu. Tímy CISC sú zložité a komplexné. RISC príkazy sú zjednodušené, krátke, vyžadujú podstatne menej času na vykonanie príkazu s pevnou dĺžkou. Použitie inštrukcií RISC vám umožňuje výrazne zvýšiť paralelizáciu výpočtov procesora, to znamená použiť viac potrubí, a tým skrátiť čas vykonávania inštrukcií. Jadro P6 tvorilo základ ďalších troch procesorov Intel – Pentium II, Celeron, Pentium III.
V tomto roku došlo aj k významnej udalosti – AMD kúpilo NexGen, ktorý mal v tom čase pokročilý architektonický vývoj. Spojenie dvoch inžinierskych tímov by neskôr svetu prinieslo procesory x86 s mikroarchitektúrou odlišnou od Intelu a dalo impulz novému kolu tvrdej konkurencie.
Na Microprocessor Forum bol prvýkrát predstavený nový procesor MediaGX od Cyrixu a jeho charakteristickou črtou je integrovaný pamäťový radič, grafický akcelerátor, rozhranie PCI zbernice a výkon porovnateľný s výkonom Pentia. Išlo o prvý pokus o takúto tesnú integráciu zariadení.
1996
Objavil sa nový procesor AMD K5 so superskalárnym jadrom RISC. Avšak jadro RISC a jeho inštrukčná sada (inštrukcie ROP) sú pred softvérom a koncovým používateľom skryté a inštrukcie x86 sú konvertované na inštrukcie RISC. Inžinieri AMD použili unikátne riešenie – inštrukcie x86 sú čiastočne konvertované počas ich umiestňovania do vyrovnávacej pamäte procesora. V ideálnom prípade dokáže procesor K5 vykonať až štyri x86 inštrukcie za takt, ale v praxi sa v priemere spracujú len 2 inštrukcie za takt.
 |
Okrem toho zmeny v poradí výpočtov, premenovanie registrov a iné „triky“ tradičné pre RISC procesory môžu zvýšiť výkon. Procesor K5 bol duchovným dieťaťom spoločného tímu inžinierov z AMD a NexGen. Maximálna rýchlosť hodín nikdy neprekročila 116 MHz, ale výkon K5 bol vyšší ako u procesorov Pentium s rovnakým taktom. Preto sa na marketingové účely po prvýkrát v praxi označovania CPU použilo hodnotenie výkonu, ktoré bolo jasne v kontraste s taktom Pentia, ktorý bol výkonovo rovnocenný. Procesor mu ale stále nedokázal dostatočne konkurovať, keďže Pentium už dosiahlo frekvenciu 166 MHz.
V tom istom roku bol vydaný Intel Pentium MMX. Hlavnou inováciou procesora P55C sú dodatočné inštrukcie MXX k inštrukčnej sade, ktorá od vzniku procesorov tretej generácie neprešla takmer žiadnymi zmenami. Technológia MMX je využitie príkazov zameraných na prácu s multimediálnymi dátami. Špeciálna sada príkazov SIMD (Single Instruction - Multiple Data) zlepšuje výkon pri vykonávaní vektorových, cyklických príkazov a spracovaní veľkého množstva dát - pri aplikácii grafických filtrov a rôznych špeciálnych efektov.
 |
V podstate ide o 57 nových inštrukcií navrhnutých na urýchlenie spracovania videa a zvuku. Zvyšnými zmenami jadra bolo typické zvýšenie vyrovnávacej pamäte, zlepšenie fungovania vyrovnávacej pamäte a ďalšie bloky. Procesor bol vyrobený pomocou 0,35-mikrónového procesu, 4,5 milióna tranzistorov. Maximálna frekvencia 233 MHz.
Výroba superskalárnych procesorov Cyrix 6x86 sa začala na jadre M1, čo bol vlastne procesor 5. generácie, ktorého charakteristickým znakom boli „hlboké“ pipelines a použitie klasických x86 inštrukcií bez ďalších inštrukčných sád.
Koncom roka, keď Intel vyvíjal PentiumII, AMD dalo o sebe opäť vedieť vydaním šiestej generácie procesora K6. AMD-K6 je založený na jadre vyvinutom inžiniermi NexGen pre procesor Nx686 a výrazne modifikovanom AMD. Podobne ako K5, aj jadro K6 nefungovalo s x86 inštrukciami, ale s RISC-like mikrokódom. Procesor podporoval MMX príkazy a 100-MHz systémovú zbernicu a mal L1 cache zväčšenú na 64 KB. Čoskoro sa ukázalo, že PentiumII bude pre K6 príliš tvrdé.
od roku 1997 do dnes...
V roku 1997 sa už vyvinuli smery inžinierskeho vývoja architektúry x86 od popredných výrobcov. Ďalšia etapa vývoja x86 procesorov sa dá charakterizovať ako konfrontácia medzi architektúrami, ktorá trvá dodnes. Do pretekov vo veľkom vstúpil Intel, ktorý obsadil 90 % trhu, AMD s ním tvrdohlavo bojuje, mnohokrát stráca na výrobnej kapacite, a Cyrix, ktorý neskôr kúpi VIA, a potom nedokáže odolať konkurencia, upadne do tmy. Ostatní výrobcovia nebudú schopní primerane konkurovať a budú nútení hľadať iné medzery na trhu. Plánuje sa prechod z CISC na mikroinštrukcie podobné RISC, v menšej miere pre Intel a viac pre AMD. Okrem toho príkazy CISC stále prichádzajú na vstup a výstup procesorov x86. Prečo vlastne začali zavádzať internú RISC architektúru do x86 procesorov s jej natívnou CISC architektúrou, ktorá umožňuje hlbšiu paralelizáciu vykonávania príkazov? Áno, len z architektúry CISC x86 v minulosti štvrtej generácie všetko bolo vyžmýkané a nezostali žiadne možnosti na zlepšenie výkonu na úrovni základných inštrukčných sád.
 |
Odvtedy nedošlo k žiadnym zásadným novým zmenám alebo prelomom vo vývoji architektúry, hoci moderné procesory sú stokrát rýchlejšie, napríklad 386. Inžinieri zdokonaľujú a vylepšujú existujúce základné mikroarchitektúry a nové sú len prepracované staré. Všetky vylepšenia a pokusy o zvýšenie výkonu spočívajú v optimalizácii existujúcich riešení, zavádzaní rôznych opráv a „bariel“ pre slabé FPU, organizačné systémy potrubia a vyrovnávacie pamäte. Ošibaným, no stále účinným prostriedkom je neustále zvyšovanie veľkosti vyrovnávacej pamäte a frekvencie zbernice FSB. Moderné procesory mať až 2 MB vyrovnávacej pamäte pracujúcej na frekvencii jadra a frekvenciách systémové zbernice dosiahnuť 800 MHz a potom pomocou multiplikátora, keďže skutočná vygenerovaná frekvencia je len 200 MHz. Za posledných 7 rokov boli do procesorov x86 zavedené tieto „podporné inovácie“: vyrovnávacia pamäť sa konečne presunula na procesorový čip a preniesla na frekvenciu jadra, zaviedli sa jednotky predikcie vetvenia, ktoré sa neustále zdokonaľujú ako kompenzácia za zvýšenie dĺžky (počet etáp) pipeline, mechanizmus dynamickej zmeny poradia vykonávania inštrukcie, zníženie počtu nečinných cyklov, mechanizmus predbežného načítania dát pre racionálnejšie využitie vyrovnávacej pamäte. Pribúdajú ďalšie sady príkazov: SSE, SSE2, SSE3, 3DNow!, 3DNow Professional. Ak by sa MMX dalo stále nazývať dodatočnou sadou inštrukcií x86, potom sú všetky nasledujúce sady nepravdepodobné, pretože k inštrukciám x86 už nie je čo pridať. Zmyslom vzhľadu týchto sád je snažiť sa čo najmenej využívať jednotku s pohyblivou rádovou čiarkou (FPU) v takej forme, v akej sa nachádza, pretože pri vysokom výkone sa vyznačuje nízkou prispôsobivosťou pre vysokú presnosť. výpočty, rozmarnosť vnútornej architektúry a jej nepredvídateľnosť, čo sťažuje život programátorom. To znamená, že v skutočnosti zaviedli špecializovanú výpočtovú jednotku zameranú nie na výpočty všeobecne, ale na skutočné, často sa vyskytujúce úlohy, ktoré sa majú vykonávať s obchádzaním klasickej FPU.
 |
Akosi to vyzerá skôr na boj s dôsledkami integrácie matematického koprocesora do CPU v roku 1989. V každom prípade, ak o tom premýšľate a počítate, procesor trávi väčšinu času „na sebe“ - na všetkých druhoch transformácií, predpovedí a oveľa viac, a nie na vykonávaní programového kódu.
Pri pohľade späť je jasné, že nie všetko išlo hladko. Zavedenie multiplikačného faktora a výsledná asynchrónnosť, ako aj zvýšenie počtu stupňov potrubia, to všetko sú dvojsečné meče. Na jednej strane to umožnilo zvýšiť takt procesora na takmer 4 GHz (a to nie je limit), na strane druhej sme dostali úzke hrdlo v podobe zbernice FSB a problém s podmienenými vetvami. . Ale všetko má svoj čas a potom to boli zrejme rozumné rozhodnutia, keďže vždy je prítomný veľmi zlý ekonomický faktor.
Treba poznamenať, že v oblasti výroby polovodičov boli v posledných rokoch dosiahnuté skutočne brilantné úspechy. 90-nanometrový technologický proces výroby x86 procesorov je už zvládnutý, čo umožňuje dosiahnuť blízko mikrovlnného rozsahu hodinové frekvencie a počet tranzistorov v kryštáli dosahuje 170 miliónov (Pentium 4 EE).
Sme zvyknutí si myslieť, že procesor je hlavným zariadením v PC a že udáva tón globálnej informatizácii. Ale víťazný pochod architektúry x86, ktorý trval viac ako štvrťstoročie, nezačal konkrétne s procesorom, ale so zariadením koncového používateľa ako celkom – IBM PC. V tom čase IBM netušilo, aká skvelá budúcnosť čaká tento počítač, a bez toho, aby projektu pripisovali akýkoľvek význam, ho sprístupnili každému. Za úspechom IBM PC stojí otvorenosť konceptu, úspech softvéru a MS DOS. A procesor v ňom mohol mať akúkoľvek architektúru, ale náhodou si IBM vybralo i8088 a i8086 a potom sa všetko začalo točiť a točiť... Ale procesor x86 sa nakoniec neukázal ako druh univerzálny počítač na všetky príležitosti alebo „inteligentné“ zariadenie, všadeprítomné a schopné robiť všetko, o čom sme predtým snívali. A „zákon“ Gordona Moorea (každé 2 roky sa počet tranzistorov v procesorovom čipe zdvojnásobí) sa stal zákonom len pre Intel, ktorý ho postavil do popredia svojej marketingovej politiky a je zrejme nepohodlné toto slovo odmietnuť. .
 |
Dnes môžeme s istotou povedať, že architektúra x86 sa dostala do slepej uličky. Jej prínos k popularizácii počítača ako zariadenia je obrovský a nikto s tým nenamieta. Nemôžete však byť relevantní večne. Z niekdajšieho mladého a silného žrebca sa stal starý kokot, ktorý je naďalej zapriahnutý do vozíka. Apetít používateľov je neukojiteľný a architektúra x86 ich čoskoro nebude môcť uspokojiť. Prechod je samozrejme spojený s herkulovským úsilím vzhľadom na skutočnosť, že svetová flotila počítačov za niekoľko miliónov dolárov v takmer absolútnej väčšine používa procesory architektúry x86, a čo je najdôležitejšie, používa softvér pre kód x86. Nemôžete všetko zmeniť za jeden deň, trvá to roky. Ale vývoj 64-bitových procesorov a programov naberá na obrátkach závideniahodnou rýchlosťou, Intel predstavil Itanium2 a AMD už takmer rok vydáva svoje Athlon 64, ktoré architektúru x86 vôbec nemajú, hoci sú plne je s ním kompatibilný a stále môže spúšťať všetky staré programy. Dá sa teda povedať, že AMD Athlon 64 znamenal začiatok odklonu od architektúry x86 a otvoril tak prechodné obdobie.
Ako vidíte, tvrdenia, že procesor je najrýchlejšie rastúcim komponentom PC, nie sú ani zďaleka nepodložené. Predstavte si, akými procesormi budú vybavené počítače našich detí. Je to desivé pomyslieť!
 |
V Odnoklassniki