АЛЕКСЕЙ БЕРЕЖНОЙ, системный администратор. Главные направления деятельности: виртуализация и гетерогенные сети. Еще одно увлечение помимо написания статей – популяризация бесплатного ПО
Резервное копирование
Теория и практика. Краткое изложение
Чтобы организовать систему резервного копирования наиболее эффективно, нужно выстроить настоящую стратегию сохранения и восстановления информации
Резервное копирование (или, как его еще называют, бэкап – от английского слова «backup») является важным процессом в жизни любой ИТ-структуры. Это парашют для спасения в случае непредвиденной катастрофы. В то же время резервное копирование используется для создания своего рода исторического архива бизнес-деятельности компании на протяжении определенного периода ее жизни. Работать без бэкапа – все равно, что жить под открытым небом – погода может испортиться в любой момент, а спрятаться негде. Но как его правильно организовать, чтобы не потерять важных данных и не потратить на это фантастические суммы?
Обычно в статьях на тему организации резервного копирования рассматриваются в основном технические решения, и лишь изредка уделяется внимание теории и методике организации сохранения данных.
В данной статье речь пойдет как раз об обратном: основное внимание уделено общим понятиям, а технические средства будут затронуты только в качестве примеров. Это позволит абстрагироваться от аппаратного и программного обеспечения и ответить на два главных вопроса: «Зачем мы это делаем?», «Можем ли мы это делать быстрее, дешевле и надежнее?».
Цели и задачи резервного копирования
В процессе организации резервного копирования ставятся две основные задачи: восстановление инфраструктуры при сбоях (Disaster Recovery) и ведение архива данных в целях последующего обеспечения доступа к информации за прошлые периоды.
Классическим примером резервной копии для Disaster Recovery является образ системной партиции сервера, созданный программой Acronis True Image.
Примером архива может выступить ежемесячная выгрузка баз данных из «1С», записанная на кассеты с последующим хранением в специально отведенном месте.
Есть несколько факторов, по которым отличают резервную копию для быстрого восстановления от архива:
- Период хранения данных. У архивных копий он достаточно длительный. В некоторых случаях регламентируется не только требованиями бизнеса, но и законодательно. У копий для аварийного восстановления он сравнительно небольшой. Обычно создают одну или две (при повышенных требованиях к надежности) резервные копии для Disaster Recovery c максимальным интервалом в сутки-двое, после чего они перезаписываются свежими. В особо критичных случаях возможно и более частое обновление резервной копии для аварийного восстановления, например, раз в несколько часов.
- Быстрота доступа к данным. Скорость доступа к длительно хранящемуся архиву в большинстве случаев не критична. Обычно необходимость «поднять данные за период» возникает в момент сверки документов, возврата к предыдущей версии и т.д., то есть не в аварийном режиме. Другое дело – аварийное восстановление, когда необходимые данные и работоспособность сервисов должны быть возвращены в кратчайшие сроки. В этом случае скорость доступа к резервной копии является крайне важным показателем.
- Состав копируемой информации. В архивной копии обычно содержатся только пользовательские и бизнес-данные за указанный период. В копии, предназначенной для аварийного восстановления, помимо этих данных, содержатся либо образы систем, либо копии настроек операционной системы и прикладного программного обеспечения, а также другой информации, необходимой для восстановления.
Иногда возможно совмещение этих задач. Например, годовой набор ежемесячных полных «снимков» файлового сервера, плюс изменения, сделанные в течении недели. В качестве инструмента для создания такой резервной копии подойдет True Image.
Самое главное – четко понимать, для чего делается резервирование. Приведу пример: вышел из строя критичный SQL-сервер по причине отказа дискового массива. На складе есть подходящее аппаратное обеспечение, поэтому решение проблемы состояло только в восстановлении программного обеспечения и данных. Руководство компании обращается с понятным вопросом: «Когда заработает?» – и неприятно удивляется, узнав, что на восстановление уйдет целых четыре часа. Дело в том, что на протяжении всего срока службы сервера регулярно осуществлялось резервное копирование исключительно баз данных без учета необходимости восстановить сам сервер со всеми настройками, включая программное обеспечение самой СУБД. Попросту говоря, наши герои сохраняли только базы данных, а про систему забыли.
Приведу другой пример. Молодой специалист на протяжении всего периода своей работы создавал посредством программы ntbackup одну-единственную копию файлового сервера под управлением Windows Server 2003, включая данные и System State в общую папку другого компьютера. По причине дефицита дискового пространства эта копия постоянно перезаписывалась. Через некоторое время его попросили восстановить предыдущий вариант многостраничного отчета, который был поврежден при сохранении. Понятное дело, что, не имея архивной истории с выключенным Shadow Copy , он не смог выполнить этот запрос.
|
На заметку Shadow Copy , дословно – «теневая копия». Обеспечивает создание мгновенных копий файловой системы таким образом, что дальнейшие изменения оригинала никак не оказывают на них влияния. С помощью данной функции возможно создавать несколько скрытых копий файла за определенный период времени, а также на лету резервные копии файлов, открытых для записи. За работу Shadow Copy отвечает служба Volume Copy Shadow Service. System State , дословно – «состояние системы». Копирование System State создает резервные копии критических компонентов операционных систем семейства Windows. Это позволяет восстановить инсталлированную ранее систему после разрушения. При копировании System State происходит сохранение реестра, загрузочных и других важных для системы файлов, в том числе для восстановления Active Directory, Certificate Service database, COM+Class Registration database, SYSVOL-директории. В ОС семейства UNIX непрямым аналогом копирования System State является сохранение содержимого каталогов /etc, /usr/local/etc и других необходимых для восстановления состояния системы файлов. |
Какой из этого следует вывод: нужно применять оба типа резервного копирования: и для аварийного восстановления, и для архивного хранения. При этом необходимо обязательно определить перечень копируемых ресурсов, время выполнения заданий, а также где, как и сколько времени будут храниться резервные копии.
При небольших объемах данных и не очень сложной ИТ-инфраструктуре можно попытаться совместить обе эти задачи в одной, например, делать ежедневное полное копирование всех дисковых разделов и баз данных. Но все же лучше различать две цели и подбирать под каждую из них правильное средство. Соответственно под каждую задачу используется свой инструмент, хотя есть и универсальные решения, как тот же пакет Acronis True Image или программа ntbackup
Понятно, что, определяя цели и задачи резервного копирования, а также решения для реализации, необходимо исходить из требований бизнеса.
При реализации задачи аварийного восстановления можно использовать разные стратегии.
В одних случаях необходимо прямое восстановление системы на «голое железо» (bare metal). Это можно выполнить, к примеру, с помощью программы Acronis True Image в комплекте с модулем Universal Restore. В этом случае конфигурацию сервера удается вернуть в строй за очень короткий срок. Например, раздел с операционной системой в 20 Гб вполне реально поднять из резервной копии за восемь минут (при условии, что архивная копия доступна по сети 1 Гб/с).
В другом варианте целесообразнее просто «вернуть» настройки на только что проинсталлированную систему, как, например, копирование в UNIX-подобных системах конфигурационных файлов из папки /etc и других (в Windows этому приблизительно соответствует копирование и восстановление System State). Конечно, при таком подходе сервер введется в работу не ранее, чем будет проинсталлирована операционная система и восстановлены необходимые установки, что займет гораздо более длительный срок. Но в любом случае решение, каким быть Disaster Recovery, проистекает из потребностей бизнеса и ресурсных ограничений.
Принципиальное отличие резервного копирования от систем избыточного резервирования
Это еще один интересный вопрос, который хотелось бы затронуть. Под системами избыточного резервирования оборудования подразумевается внесение некоторой избыточности в аппаратное обеспечение с целью сохранения работоспособности в случае внезапного выхода из строя одного из компонентов. Прекрасный пример в данном случае – RAID-массив (Redundant Array of Independent Disks). В случае отказа одного диска можно избежать потери информации и безопасно произвести замену, сохранив данные за счет специфичной организации самого дискового массива (подробнее о RAID читайте в ).
Мне доводилось слышать фразу: «У нас очень надежное оборудование, везде стоят RAID-массивы, поэтому резервные копии нам не нужны». Да, конечно, тот же самый RAID-массив убережет данные от разрушения при выходе из строя одного жесткого диска. Но вот от повреждения данных компьютерным вирусом или от неумелых действий пользователя это не спасет. Не спасет RAID и при крахе файловой системы в результате несанкционированной перезагрузки.
|
Кстати Важность отличия резервного копирования от систем избыточного резервирования следует оценивать еще при составлении плана копирования данных, касается ли это организации или домашних компьютеров. Спросите себя, зачем вы делаете копии. Если речь идет о резервном копировании, то подразумевается сохранение данных при случайном (умышленном) действии. Избыточное резервирование дает возможность сохранить данные, в том числе и резервные копии, при выходе оборудования из строя. Сейчас на рынке появилось множество недорогих устройств, обеспечивающих надежное резервирование с помощью RAID-массивов или облачных технологий (например, Amazon S3). Рекомендуется использовать одновременно оба вида резервирования информации. Андрей Васильев, генеральный директор компании Qnap Россия |
Приведу один пример. Бывают случаи, когда события развиваются по следующему сценарию: при выходе диска из строя происходит восстановление данных за счет механизма избыточности, в частности, с помощью сохраненных контрольных сумм. При этом наблюдается значительное снижение быстродействия, сервер подвисает, управление практически потеряно. Системный администратор, не видя другого выхода, перезагружает сервер холодным перезапуском (попросту говоря, нажимает на «RESET»). В результате такой перегрузки «по живому» возникают ошибки файловой системы. Самое лучшее, чего можно ожидать в этом случае, – длительная работа программы проверки диска в целях восстановления целостности файловой системы. В худшем варианте придется попрощаться с файловой системой и озадачиться вопросом, откуда, как и в какие сроки можно восстановить данные и работоспособность сервера.
У вас не получится избежать резервного копирования и при наличии кластерной архитектуры. Отказоустойчивый кластер, по сути, сохраняет работоспособность вверенных ему сервисов при выходе из строя одного из серверов. В случае вышеперечисленных проблем, таких как, вирусная атака или повреждение данных из-за пресловутого «человеческого фактора», никакой кластер не спасет.
Единственное, что может выступить в качестве неполноценной замены резервного копирования для Disaster Recovery, – наличие зеркального резервного сервера с постоянным реплицированием данных с основного сервера на резервный (по принципу Primary Standby). В этом случае при выходе из строя основного сервера его задачи будут подхвачены резервным, и даже не придется переносить данные. Но такая система является довольно дорогостоящей и трудоемкой при организации. Не забываем еще про необходимость постоянной репликации.
Становится понятно, что такое решение рентабельно только в случае критичных сервисов при наличии высоких требований к отказоустойчивости и минимальном времени восстановления. Как правило, такие схемы применяются в очень крупных организациях с высоким товарно-денежным оборотом. А неполноценной заменой резервному копированию эта схема является потому, что все равно при повреждении данных компьютерным вирусом, неумелыми действиями пользователя или некорректной работой приложения, могут быть затронуты данные и программное обеспечение на обоих серверах.
И уж, конечно, никакая система избыточного резервирования не решит задачу ведения архива данных в течение определенного периода.
Понятие «окно бэкапа»
Выполнение резервного копирования вызывает серьезную нагрузку на резервируемый сервер. Особенно это актуально для дисковой подсистемы и сетевых соединений. В некоторых случаях, когда процесс копирования имеет достаточно высокий приоритет, это может привести к недоступности тех или иных сервисов. Кроме этого, копирование данных в момент внесения изменений связано со значительными трудностями. Конечно, есть технические средства, позволяющие избежать проблем при сохранении целостности данных и в этом случае, но по возможности такого копирования на лету лучше избегать.
Выход при решении этих вышеописанных проблем напрашивается сам собой: перенести запуск процесса создания копий на неактивный период времени, когда взаимное влияние резервного копирования и других работающих систем будет минимально. Этот временной период называется «окно бэкапа». Например, для организации, работающей по формуле 8х5 (пять восьмичасовых рабочих дней в неделю), таким «окном» обычно являются выходные дни и ночные часы.
Для систем, работающих по формуле 24х7 (всю неделю круглосуточно), в качестве такого периода используется время минимальной активности, когда нет высокой нагрузки на серверы.
Виды резервного копирования
Чтобы избежать излишних материальных затрат при организации резервного копирования, а также по возможности не выходить за рамки окна бэкапа, разработано несколько технологий backup, которые применяют в зависимости от конкретной ситуации.
Полное резервное копирование (или Full backup)
Является главным и основополагающим методом создания резервных копий, при котором выбранный массив данных копируется целиком. Это наиболее полный и надежный вид резервного копирования, хотя и самый затратный. В случае необходимости сохранить несколько копий данных общий хранимый объем будет увеличиваться пропорционально их количеству. Для предотвращения подобного расточительства используют алгоритмы сжатия, а также сочетание этого метода с другими видами резервного копирования: инкрементным или дифференциальным. И, конечно, полное резервное копирование незаменимо в случае, когда нужно подготовить резервную копию для быстрого восстановления системы с нуля.
Инкрементное копирование
В отличие от полного резервного копирования в этом случае копируются не все данные (файлы, сектора и т.д.), а только те, что были изменены с момента последнего копирования. Для выяснения времени копирования могут применяться различные методы, например, в системах под управлением операционных систем семейства Windows используется соответствующий атрибут файла (архивный бит), который устанавливается, когда файл был изменен, и сбрасывается программой резервного копирования. В других системах может использоваться дата изменения файла. Понятно, что схема с применением данного вида резервного копирования будет неполноценной, если время от времени не проводить полное резервное копирование. При полном восстановлении системы нужно провести восстановление из последней копии, созданной Full backup, а потом поочередно «накатить» данные из инкрементных копий в порядке их создания.
Для чего используется этот вид копирования? В случае создания архивных копий он необходим, чтобы сократить расходуемые объемы на устройствах хранения информации (например, сократить число используемых ленточных носителей). Также это позволит минимизировать время выполнения заданий резервного копирования, что может быть крайне важно в условиях, когда приходится работать в плотном графике 24х7 или прокачивать большие объемы информации.
У инкрементного копирования есть один нюанс, который нужно знать. Поэтапное восстановление возвращает и нужные удаленные файлы за период восстановления. Приведу пример. Допустим, по выходным дням выполняется полное копирование, а по будням инкрементное. Пользователь в понедельник создал файл, во вторник его изменил, в среду переименовал, в четверг удалил. Так вот при последовательном поэтапном восстановлении данных за недельный период мы получим два файла: со старым именем за вторник до переименования, и с новым именем, созданным в среду. Это произошло потому, что в разных инкрементных копиях хранились разные версии одного и того же файла, и в итоге будут восстановлены все варианты. Поэтому при последовательном восстановлении данных из архива «как есть» имеет смысл резервировать больше дискового пространства, чтобы смогли поместиться в том числе и удаленные файлы.
Дифференциальное резервное копирование
Отличается от инкрементного тем, что копируются данные с последнего момента выполнения Full backup. Данные при этом помещаются в архив «нарастающим итогом». В системах семейства Windows этот эффект достигается тем, что архивный бит при дифференциальном копировании не сбрасывается, поэтому измененные данные попадают в архивную копию, пока полное копирование не обнулит архивные биты.
В силу того, что каждая новая копия, созданная таким образом, содержит данные из предыдущей, это более удобно для полного восстановления данных на момент аварии. Для этого нужны только две копии: полная и последняя из дифференциальных, поэтому вернуть к жизни данные можно гораздо быстрее, чем поэтапно накатывать все инкременты. К тому же этот вид копирования избавлен от вышеперечисленных особенностей инкрементного, когда при полном восстановлении старые файлы, подобно птице Феникс, возрождаются из пепла. Возникает меньше путаницы.
Но дифференциальное копирование значительно проигрывает инкрементному в экономии требуемого пространства. Так как в каждой новой копии хранятся данные из предыдущих, суммарный объем зарезервированных данных может быть сопоставим с полным копированием. И, конечно, при планировании расписания (и расчетах, поместится ли процесс бэкапа во временное «окно») нужно учитывать время на создание последней, самой «толстой», дифференциальной копии.
Топология резервного копирования
Рассмотрим какие бывают схемы резервного копирования.
Децентрализованная схема
Ядром этой схемы является некий общий сетевой ресурс (см. рис. 1). Например, общая папка или FTP-сервер. Необходим и набор программ для резервного копирования, время от времени выгружающих информацию с серверов и рабочих станций, а также других объектов сети (например, конфигурационные файлы с маршрутизаторов) на этот ресурс. Данные программы установлены на каждом сервере и работают независимо друг от друга. Несомненным плюсом является простота реализации этой схемы и ее дешевизна. В качестве программ копирования подойдут штатные средства, встроенные в операционную систему, или программное обеспечение, такое как СУБД. Например, это может быть программа ntbackup для семейства Windows, программа tar для UNIX-like операционных систем или набор скриптов, содержащих встроенные команды SQL-сервера для выгрузки баз данных в файлы резервных копий. Еще одним плюсом является возможность использования различных программ и систем, лишь бы все они могли получить доступ к целевому ресурсу для хранения резервных копий.
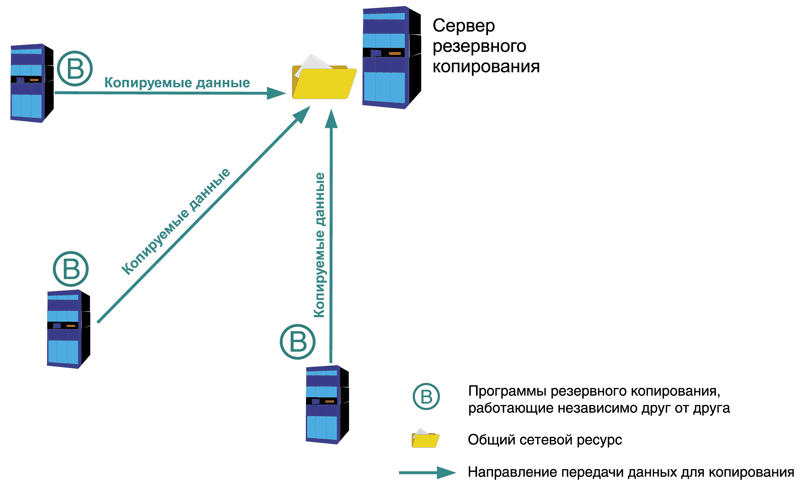
Минусом является неповоротливость этой схемы. Так как программы установлены независимо друг от друга, то и настраивать приходится каждую по отдельности. Довольно тяжело учитывать особенности расписания и распределять временные интервалы, чтобы избежать конкуренции за целевой ресурс. Мониторинг также затруднен, процесс копирования с каждого сервера приходится отслеживать отдельно от других, что в свою очередь может привести к высоким трудозатратам.
Поэтому данная схема применяется в небольших сетях, а также в ситуации, когда невозможно организовать централизованную схему резервного копирования имеющимися средствами. Более подробное описание этой схемы и практическую организацию можно найти в .
Централизованное резервное копирование
В отличие от предыдущей схемы в этом случае используется четкая иерархическая модель, работающая по принципу «клиент-сервер». В классическом варианте на каждый компьютер устанавливаются специальные программы-агенты, а на центральный сервер – серверный модуль программного пакета. Эти системы также имеют специализированную консоль управления серверной частью. Схема управления выглядит следующим образом: с консоли создаем задания для копирования, восстановления, сбора информации о системе, диагностики и так далее, а сервер дает агентам необходимые инструкции для выполнения указанных операций.
Именно по такому принципу работает большинство популярных систем резервного копирования, таких как Symantec Backup Exec, CA Bright Store ARCServe Backup, Bacula и другие (см. рис. 2).
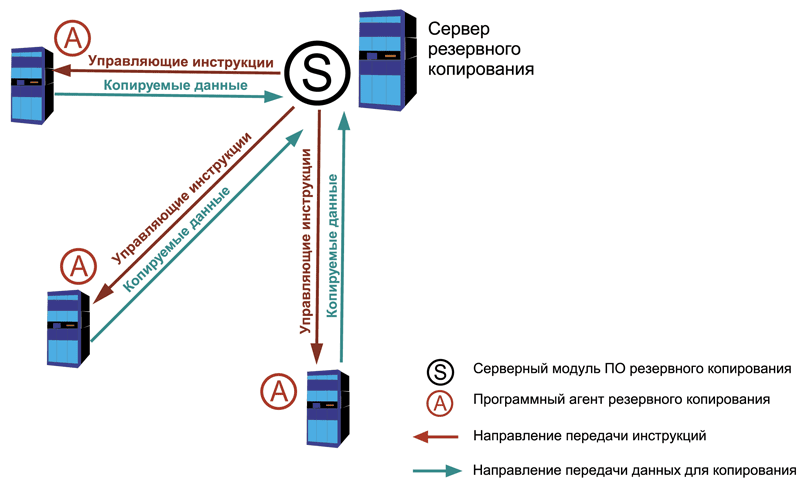
Помимо различных агентов для большинства операционных систем существуют разработки для резервного копирования популярных баз данных и корпоративных систем, например, для MS SQL Server, MS Exchange, Oracle Database и так далее.
Для совсем небольших компаний в некоторых случаях можно попробовать упрощенный вариант централизованной схемы резервного копирования без применения программ-агентов (см. рис. 3). Также эта схема может быть задействована, если не реализован специальный агент для используемого ПО резервного копирования. Вместо этого серверный модуль будет использовать уже существующие службы и сервисы. Например, «выгребать» данные из скрытых общих папок на Windows-серверах или копировать файлы по протоколу SSH c серверов под управлением UNIX-систем. Данная схема имеет весьма существенные ограничения, связанные с проблемами сохранения файлов, открытых для записи. В результате подобных действий открытые файлы будут либо пропущены и не попадут в резервную копию, либо скопированы с ошибками. Существуют различные методы обхода данной проблемы, например, повторный запуск задания с целью скопировать только ранее открытые файлы, но нет ни одного надежного. Поэтому такая схема подходит для применения только в определенных ситуациях. Например, в небольших организациях, работающих в режиме 5х8, с дисциплинированными сотрудниками, которые сохраняют изменения и закрывают файлы перед уходом домой. Для организации такой усеченной централизованной схемы, работающей исключительно в среде Windows, неплохо подходит ntbackup. При необходимости использовать подобную схему в гетерогенных средах или исключительно среди UNIX-компьютеров я рекомендую посмотреть в сторону Backup PC (см. ).
Рисунок 4. Смешанная схема резервного копирования
Что такое off-site?
В нашем неспокойном изменчивом мире могут произойти события, способные вызвать неприятные последствия для ИТ-инфраструктуры и бизнеса в целом. Например, пожар в здании. Или прорыв батареи центрального отопления в серверной комнате. Или банальная кража техники и комплектующих. Одним из методов избежать потери информации в таких ситуациях является хранение резервных копий в месте, удаленном от основного расположения серверного оборудования. При этом необходимо предусмотреть быстрый способ доступа к данным, необходимым для восстановления. Описываемый метод называется off-site (проще говоря, хранение копий за территорией предприятия). В основном используются два метода организации этого процесса.
Запись данных на съемные носители и их физическое перемещение. В этом случае необходимо позаботиться о средствах быстрой доставки носителей обратно в случае сбоя. Например, хранить их в соседнем здании. Плюсом такого метода является возможность организовать этот процесс без каких-либо затруднений. Минусом являются сложность возврата носителей и сама необходимость передачи информации на хранение, а также риск повредить носители при перевозке.
Копирование данных в другое расположение по сетевому каналу. Например, с использованием VPN-туннеля через Интернет . Плюсом в этом случае является то, что нет нужды везти куда-то носители с информацией, минусом – необходимость использования достаточного широкого канала (как правило, это весьма недешево) и защиты передаваемых данных (например, с помощью того же VPN). Возникающие сложности передачи больших объемов данных можно значительно снизить, используя алгоритмы сжатия или технологию дедупликации .
Отдельно стоит сказать о мерах безопасности при организации хранения данных. В первую очередь необходимо позаботиться о том, чтобы носители с данными находились в охраняемом помещении, и о мерах, препятствующих прочтению данных посторонними лицами. Например, использовать систему шифрования, заключить договора о неразглашении и так далее. Если задействованы съемные носители, данные на них должны быть также зашифрованы. Используемая система маркировки при этом не должна помогать злоумышленнику в анализе данных. Необходимо применять безликую номерную схему маркировки носителей названий передаваемых файлов. При передаче данных по сети необходимо (как уже писалось выше) использовать безопасные методы передачи данных, например, VPN-туннель.
Мы разобрали основные моменты при организации резервного копирования. В следующей части будут рассмотрены методические рекомендации и приведены практические примеры для создания эффективной системы резервного копирования.
- Описание резервного копирования в системе Windows, в том числе System State – http://www.datamills.com/Tutorials/systemstate/tutorial.htm .
- Описание Shadow Copy – http://ru.wikipedia.org/wiki/Shadow_Copy .
- Официальный сайт Acronis – http://www.acronis.ru/enterprise/products .
- Описание ntbackup – http://en.wikipedia.org/wiki/NTBackup .
- Бережной А. Оптимизируем работу MS SQL Server. //Системный администратор, №1, 2008 г. – С. 14-22 ().
- Бережной А. Организуем систему резервного копирования для малого и среднего офиса. //Системный администратор, №6, 2009 г. – С. 14-23 ().
- Маркелов А. Linux на страже Windows. Обзор и установка системы резервного копирования BackupPC. //Системный администратор, №9, 2004 г. – С. 2-6 ().
- Описание VPN – http://ru.wikipedia.org/wiki/VPN .
- Дедупликация данных – http://en.wikipedia.org/wiki/Data_deduplication .
Вконтакте
От природных и техногенных катастроф, действий злоумышленников. Эти технологии активно используются в ИТ-инфраструктурах организаций самых разных отраслей и масштабов.
Классификация резервного копирования
По полноте сохраняемой информации
- Полное резервирование (Full backup) - создание резервного архива всех системных файлов, обычно включающего состояние системы, реестр и другую информацию, необходимую для полного восстановления рабочих станций. То есть резервируются не только файлы, но и вся информация, необходимая для работы системы.
- Добавочное резервирование (Incremental backup) - создание резервного архива из всех файлов, которые были модифицированы после предыдущего полного или добавочного резервирования.
- Разностное резервирование (Differential backup) - создание резервного архива из всех файлов, которые были изменены после предыдущего полного резервирования.
- Выборочное резервирование (Selective backup) - создание резервного архива только из отобранных файлов.
По способу доступа к носителю
- Оперативное резервирование (Online backup) - создание резервного архива на постоянно подключенном (напрямую или через сеть) носителе.
- Автономное резервирование (Offline backup) - хранение резервной копии на съёмном носителе, кассете или картридже, который перед использованием следует установить в привод.
Правила работы с системами резервного копирования
При использовании любой технологии резервного копирования следует придерживаться некоторых фундаментальных правил, соблюдение которых обеспечит максимальную сохранность данных в случае возникновения непредвиденных ситуаций.
- Предварительное планирование. В процессе планирования должны учитываться все компоненты инфраструктуры резервного копирования, а все приложения, сервера и тенденции увеличения ёмкости первичных хранилищ данных не должны оставаться без внимания.
- Установление жизненного цикла и календаря операций.
Все задания, связанные с резервным копированием, должны быть задокументированы и выполняться согласно расписанию. Ниже приведён список задач, выполнять которые необходимо ежедневно:
- мониторинг заданий;
- отчёты о сбоях и успешном выполнении;
- анализ и разрешение проблем;
- манипуляции с лентами и управление библиотекой;
- составление расписания выполнения заданий.
- Ежедневный обзор логов процесса резервного копирования. Поскольку каждый сбой в создании резервных копий может повлечь за собой множество затруднений, проверять ход процесса копирования нужно, по меньшей мере, каждый день.
- Защита базы данных резервного копирования или каталога. Каждое приложение резервного копирования ведёт свою базу данных, потеря которой может означать утрату резервных копий.
- Ежедневное определение временного окна резервного копирования. Если время выполнения заданий начинает выходить за пределы отведённого временного окна, это является признаком приближения к предельной ёмкости системы или наличия слабых звеньев в производительности. Своевременное обнаружение таких признаков может избавить от последующих более крупных сбоев системы.
- Локализация и сохранение «внешних» систем и томов. Необходимо лично проверять соответствие резервных копий своим ожиданиям, в первую очередь полагаясь на сови наблюдения, а не на отчёты программ.
- Максимально возможная централизация и автоматизация резервного копирования. Сведение множества задач по резервированию в одну значительно упрощает процесс создания копий.
- Создание и поддержка открытых отчётов, отчётов об открытых проблемах. Наличие журнала нерешённых проблем может способствовать скорейшему их устранению, и, как следствие, оптимизации процесса резервного копирования.
- Включение резервного копирования в процесс контроля изменений системы.
- Консультации с вендорами. Следует убеждаться, что внедрённая система полностью соответствует ожиданиям организации.
Технологии резервного копирования
Безопасность
Как правило, резервное копирование происходит автоматически. Для доступа к данным обычно требуются повышенные привилегии. Так что процесс, обеспечивающий резервное копирование, запускается из-под учетной записи с повышенными привилегиями - вот тут-то и закрадывается определенный риск. Читать статью
Подготовку нового сервера к работе следует начинать с настройки резервного копирования. Все, казалось бы, об этом знают — но порой даже опытные системные администраторы допускают непростительные ошибки. И дело здесь не только в том, что задачу настройки нового сервера нужно решать очень быстро, но еще и в том, что далеко не всегда бывает ясно, какой способ резервного копирования нужно использовать.
Конечно, идеальный способ, который бы всех устраивал, создать невозможно: везде есть свои плюсы и минусы. Но в то же время вполне реальным представляется подобрать способ, максимально подходящий под специфику конкретно проекта.
При выборе способа резервного копирования нужно прежде всего обратить внимание на следующие критерии:
- Скорость (время) резервного копирования в хранилище;
- Скорость (время) восстановления из резервной копии;
- Сколько копий можно будет держать при ограниченном размере хранилища (сервере хранения бекапов);
- Объем рисков из-за неконсистентности резервных копий, неотлаженности метода выполнения бэкапов, полной или частичной потери бекапов;
- Накладные расходы: уровень нагрузки, создаваемой на сервер при выполнении копирования, уменьшение скорости отклика сервиса и т.п.
- Стоимость аренды всех использующихся сервисов.
В этой статье мы расскажем об основных способах резервного копирования серверов под управлением Linux-систем и о наиболее типичных проблемах, с которыми могут столкнуться новички в этой очень важной области системного администрирования.
Схема организации хранения и восстановления из резервных копий
При выборе схемы организации метода резервирования следует обратить внимание на следующие базовые моменты:- Резервные копии нельзя хранить в одном месте с резервируемыми данными. Если вы храните резервную копию на одном дисковом массиве с вашими данными, то вы потеряете её в случае повреждения основного дискового массива.
- Зеркалирование (RAID1) нельзя сравнивать с резервным копированием. Рейд защищает вас только от аппаратной проблемы с одним из дисков (а рано или поздно такая проблема будет, т.к. дисковая подсистема почти всегда является узким местом на сервере). К тому же при использовании аппаратных рейдов есть риск поломки контроллера, т.е. необходимо хранить его запасную модель.
- Если вы храните резервные копии в рамках одной стойки в ДЦ или просто в рамках одного ДЦ, то в такой ситуации тоже имеются определенные риски (об этом можно прочитать, например, .
- Если вы храните резервные копии в разных ДЦ, то резко возрастают затраты на сеть и скорость восстановления из удаленной копии.
Часто причиной восстановления данных служит повреждение файловой системы или дисков. Т.е. бекапы нужно хранить где-то на отдельном сервере-хранилище. В этом случае проблемой может стать «ширина» канала передачи данных. Если у вас выделенный сервер, то резервное копирование очень желательно выполнять по отдельному сетевому интерфейсу, а не на том же, что выполняет обмен данных с клиентами. Иначе запросы вашего клиента могут не «поместиться» в ограниченный канал связи. Или из-за трафика клиентов бекапы не будут сделаны в срок.
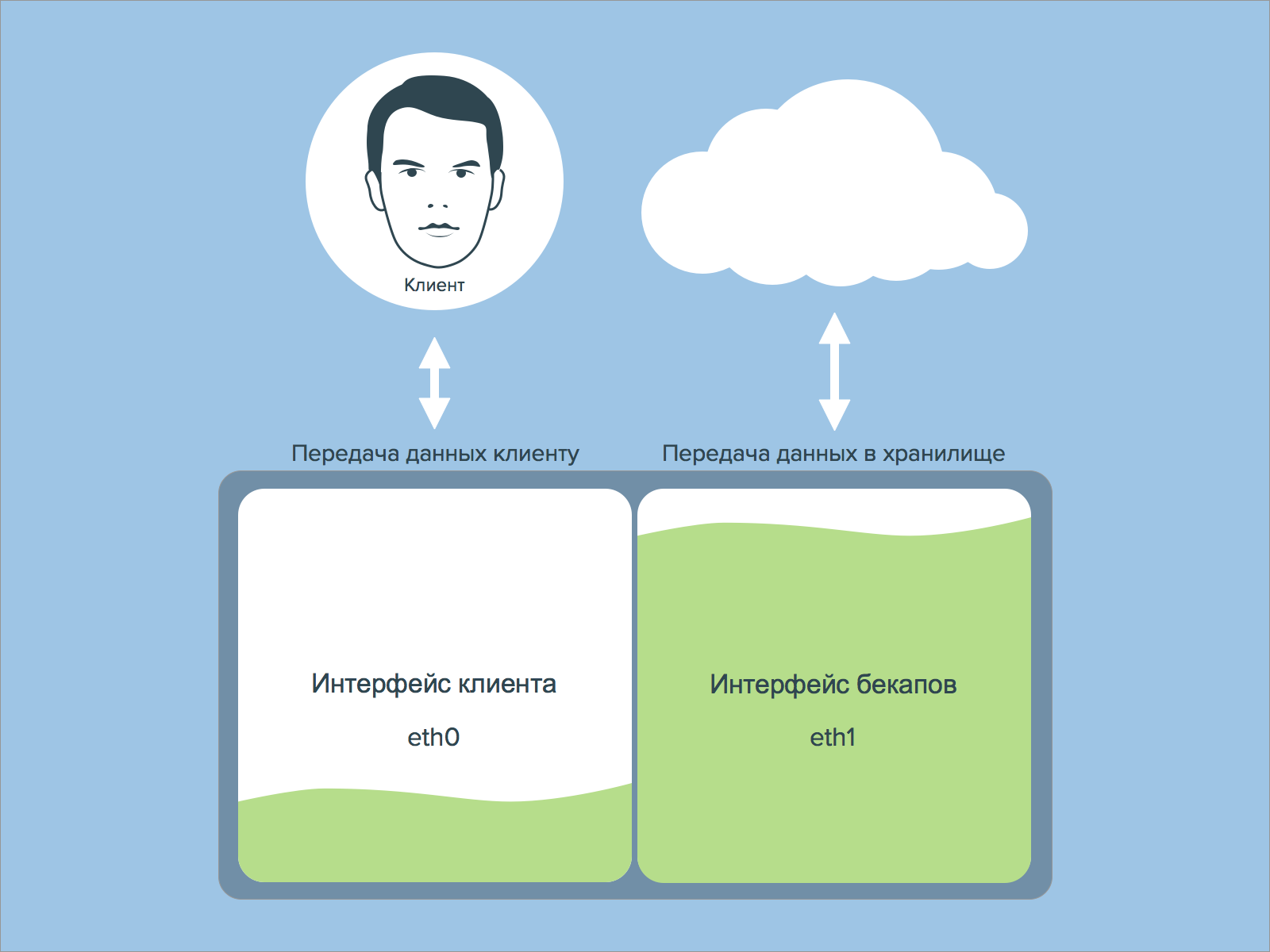
Далее нужно подумать о схеме и времени восстановления данных с точки зрения хранения бекапов. Может быть вас вполне устраивает, что бекап выполняется за 6 часов ночью на хранилище с ограниченной скоростью доступа, однако восстановление длиной в 6 часов вас вряд ли устроит. Значит доступ к резервным копиям должен быть удобным и данные должны копироваться достаточно быстро. Так, например, восстановление 1Тб данных с полосой в 1Гб/с займет почти 3 часа, и это если вы не «упретесь» в производительность дисковой подсистемы в хранилище и сервере. И не забудьте прибавить к этому время обнаружения проблемы, время на решение об откате, время проверки целостности восстановленных данных и объем последующего недовольства клиентов/коллег.
Инкрементальное резервное копирование
При инкрементальном резервном копировании копируются только файлы, которые были изменены со времени предыдущего бэкапа. Последующее инкрементальное резервное копирование добавляет только файлы, которые были изменены с момента предыдущего. В среднем инкрементальное резервное копирование занимает меньше времени, так как копируется меньшее количество файлов. Однако процесс восстановления данных занимает больше времени, так как должны быть восстановлены данные последнего полного резервного копирования, плюс данные всех последующих инкрементальных резервных копирований. При этом в отличие от дифференциального копирования, изменившиеся или новые файлы не замещают старые, а добавляются на носитель независимо.
Инкрементальное копирование чаще всего производится с помощью утилиты rsync. С его помощью можно сэкономить место в хранилище, если количество изменений за день не очень велико. Если измененные файлы имеют большой размер, то они будут скопированы полностью без замены предыдущих версий.
Процесс резервного копирования с помощью rsync можно разделить на следующие шаги:
- Составляется список файлов на резервируемом сервере и в хранилище, по каждому файлу считываются метаданные (права, время изменения и т.д) или контрольная сумма (при использовании ключа —checksum).
- Если метаданные файлов разнятся, то файл бьется на блоки и по каждому блоку считается контрольная сумма. Отличающиеся блоки закачиваются в хранилище.
- Если во время подсчета контрольных сумм или передачи файла в него было внесено изменение, его резервирование повторяется с начала.
- По умолчанию rsync передает данные через SSH, а значит каждый блок данных дополнительно шифруется. Rsync можно также запустить как демон и передавать данные без шифрования по его протоколу.
С более подробной информацией о работе rsync можно ознакомиться на официальном сайте .
Для каждого файла rsync выполняет очень большое количество операций. Если файлов на сервере много или если процессор сильно загружен, то скорость резервного копирования будет существенно снижена.
Из опыта можем сказать, что проблемы на SATA-дисках (RAID1) начинаются примерно после 200G данных на сервере. На самом деле всё, конечное же, зависит от количества inode. И в каждом случае эта величина может смещаться как в одну так и в другую сторону.
После определенной черты время выполнения резервного копирования будет очень долгим или попросту не будет отрабатывать за сутки.
Для того, чтобы не сравнивать все файлы, есть lsyncd. Этот демон собирает информацию об изменившихся файлах, т.е. мы уже заранее будем иметь готовый их список для rsync. Следует, однако, учесть, что он дает дополнительную нагрузку на дисковую подсистему.
Дифференциальное резервное копирование
При дифференциальном резервном копировании каждый файл, который был изменен с момента последнего полного резервного копирования, копируется всякий раз заново. Дифференциальное копирование ускоряет процесс восстановления. Все, что вам необходимо — это последняя полная и последняя дифференциальная резервная копия. Популярность дифференциального резервного копирования растет, так как все копии файлов делаются в определенные моменты времени, что, например, очень важно при заражении вирусами.
Дифференциальное резервное копирование осуществляется, например, при помощи такой утилиты, как rdiff-backup. При работе с этой утилитой возникают те же проблемы, что и при инкрементальном резервном копировании.
В целом, если при поиске разницы в данных осуществляется полный перебор файлов, проблемы такого рода резервирования аналогичны проблемам с rsync.
Хотим отдельно отметить, что если в вашей схеме резервного копирования каждый файл копируется отдельно, то стоит удалять/исключать ненужные вам файлы. Например, это могут быть кеши CMS. В таких кешах обычно очень много маленьких файлов, потеря которых не скажется на корректной работе сервера.
Полное резервное копирование
Полное копирование обычно затрагивает всю вашу систему и все файлы. Еженедельное, ежемесячное и ежеквартальное резервное копирование подразумевает создание полной копии всех данных. Обычно оно выполняется по пятницам или в течение выходных, когда копирование большого объёма данных не влияет на работу организации. Последующие резервные копирования, выполняемые с понедельника по четверг до следующего полного копирования, могут быть дифференциальными или инкрементальными, главным образом для того, чтобы сохранить время и место на носителе. Полное резервное копирование следует проводить по крайней мере еженедельно.
В большинстве публикаций по соответствующей тематике рекомендуется полное резервное копирование выполнять один или два раза в неделю, а в остальное время время — использовать инкрементальное и дифференциальное. В таких советах есть свой резон. В большинстве случаев полного резервного копирования раз в неделю вполне достаточно. Выполнять его повторно имеет смысл в том случае, если у вас нет возможности на стороне хранилища актуализировать полный бекап и для обеспечения гарантии корректности резервной копии (это может понадобиться, например, в случаях, если вы по тем или иным причинам не доверяете имеющимся у вас скриптам или софту для резервного копирования.
На самом деле полное резервное копирование можно поделить на 2 части:
- Полное резервное копирование на уровне файловой системы;
- Полное резервное копирование на уровне устройств.
Рассмотрим их характерные особенности на примере:
root@komarov:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/komarov_system-root 3.4G 808M 2.4G 25% /
/dev/mapper/komarov_system-home 931G 439G 493G 48% /home
udev 383M 4.0K 383M 1% /dev
tmpfs 107M 104K 107M 1% /run
tmpfs 531M 0 531M 0% /tmp
none 5.0M 0 5.0M 0% /run/lock
none 531M 0 531M 0% /run/shm
/dev/xvda1 138M 22M 109M 17% /boot
Резервировать мы будем только /home. Все остальное можно быстро восстановить вручную. Можно также развернуть сервер системой управления конфигурациями и подключить к нему наш /home.
Полное резервное копирование на уровне файловой системы
Типичный представитель: dump.Утилита создает «дамп» файловой системы. Можно создавать не только полную, но и инкрементальную резервную копию. dump работает с таблицей inode и «понимает» структуру файлов (так, разреженные файлы сжимаются).
Создавать дамп работающей файловой системы «глупо и опасно», потому что ФС может изменяться во время создания дампа. Его надо создавать со снапшота (чуть позже мы обсудим особенности работы со снапшотами более подробно), отмонтированной или замороженной ФС.
Такая схема так же зависит от количества файлов, и время её выполнения будет расти с ростом количества данных на диске. В то же время у dump скорость работы выше, чем у rsync.
В случае, если требуется возобновить не резервную копию целиком, а, например, только пару случайно испорченных файлов), извлечение таких файлов утилитой restore может занять слишком много времени
Полное резервное копирование на уровне устройств
- mdraid и DRBD
Фактически настраивается RAID1 с диском/рейдом на сервере и сетевым диском, и время от времени (по частоте выполнения бекапов) дополнительный диск синхронизируется с основным диском/рейдом на сервере.Самый большой плюс — скорость. Длительность выполнения синхронизации зависит только от количества внесенных за последний день изменений.
Такая система резервного копирования используется довольно часто, но мало кто отдает себе отчет в том, что полученные с ее помощью резервные копии могут быть недееспособными, и вот почему. Когда синхронизация дисков завершена, диск с резервной копией отключается. Если у нас, например, запущена СУБД, которая пишет данные на локальный диск порциями, храня промежуточные данные в кэше, нет никакой гарантии того, что они вообще попадут на бэкапный диск. В лучшем случае мы потеряем часть изменяемых данных. Поэтому такие бэкапы вряд ли стоит считать надежными. - LVM + dd
Снапшоты — замечательный инстумент для создания консистентных бекапов. Перед созданием снапшота необходимо сбросить кеш ФС и вашего ПО на дисковую подсистему.
Например, с одним MySQL это будет выглядеть так:
$ sudo mysql -e "FLUSH TABLES WITH READ LOCK;"
$ sudo mysql -e "FLUSH LOGS;"
$ sudo sync
$ sudo lvcreate -s -p r -l100%free -n %s_backup /dev/vg/%s
$ sudo mysql -e "UNLOCK TABLES;"
* Коллеги рассказывают истории как у кого-то «read lock» иногда приводил к дедлокам, но на моей памяти такого не было ни разу.
Бекапы СУБД можно создать отдельно (например, используя бинарные логи), устранив тем самым простой на время сброса кеша. А можно создавать дампы в хранилище, запустив там инстанс СУБД. Резервное копирование разных СУБД — это тема для отдельных публикаций.
Копировать снапшот можно с использованием докачки (например, rsync с патчем для копирования блочных устройств bugzilla.redhat.com/show_bug.cgi?id=494313), можно по блокам и без шифрования (netcat, ftp). Можно передавать блоки в сжатом виде и монтировать их в хранилище при помощи AVFS, и примонтировать на сервере раздел с бекапами по SMB.
Сжатие устраняет проблемы скорости передачи, забития канала и места в хранилище. Но, однако если вы не используете AVFS в хранилище, то на восстановление только части данных у вас уйдет много времени. Если будете использовать AVFS, то столкнетесь с её «сыростью».
Альтернатива сжатию блоками — squashfs: можно подмонтировать, к примеру, по Samba раздел к серверу и выполнить mksquashfs, но эта утилита так же работает с файлами, т.е. зависит от их количества.
К тому же при создании squashfs тратится достаточно много ОЗУ, что может легко привести к вызову oom-killer.
Безопасность
Необходимо обезопасить себя от ситуации когда хранилище или ваш сервер будут взломаны. Если взломан сервер, то лучше чтобы не было прав на удаление/изменение файлов в хранилище у пользователя, который записывает туда данные.Если взломано хранилище, то права бекапного пользователя на сервере так же желательно ограничить по максимуму.
Если канал резервного копирования может быть прослушан, то нужны средства шифрования.
Заключение
У каждой системы резервного копирования свои минусы и свои плюсы. В этой статье мы постарались осветить часть нюансов при выборе системы резервного копирования. Надеемся, что они помогут нашим читателям.В итоге, при выборе системы резервного копирования под ваш проект, нужно провести тесты выбранного типа резервного копирования и обратить внимание на:
- время резервного копирования в текущей стадии проекта;
- время резервного копирования в случае, если данных будет в разы больше;
- нагрузку на канал;
- нагрузку на дисковую подсистему на сервере и в хранилище;
- время восстановление всех данных;
- время восстановления пары файлов;
- необходимость в консистентности данных, особенно БД;
- расход памяти и наличие вызовов oom-killer;
В качестве решений по резервному копированию, можно использовать supload и наше облачное хранилище .
Читателей, которые не могут оставлять комментарии здесь, приглашаем к нам в блог .
Метки: Добавить метки