From natural and man-made disasters, actions of intruders. These technologies are actively used in the IT infrastructures of organizations of various industries and sizes.
Backup classification
According to the completeness of the stored information
- Full reservation(Full backup) - creating a backup archive of all system files, usually including system status, registry and other information necessary to fully restore workstations. That is, not only files are backed up, but also all the information necessary for the operation of the system.
- Additional reservation(Incremental backup) - creating a backup archive from all files that have been modified since the previous full or incremental backup.
- Differential reservation(Differential backup) - creating a backup archive from all files that have been changed since the previous full backup.
- Selective reservation(Selective backup) - creating a backup archive only from selected files.
By method of accessing the media
- Operational backup(Online backup) - creating a backup archive on a permanently connected (directly or via a network) medium.
- Offline reservation(Offline backup) - storing a backup copy on removable media, a cassette or cartridge, which must be installed in the drive before use.
Rules for working with backup systems
When using any backup technology, you should adhere to some fundamental rules, compliance with which will ensure maximum data safety in case of unforeseen situations.
- Pre-planning. All components of the backup infrastructure must be considered in the planning process, and all applications, servers, and trends in primary storage capacity must not be ignored.
- Establishment life cycle and calendar of operations. All backup-related tasks must be documented and performed according to schedule. Below is a list of tasks that need to be completed daily:
- task monitoring;
- failure and success reports;
- problem analysis and resolution;
- tape manipulation and library management;
- scheduling tasks.
- Daily review of backup process logs. Because every failure in creation backup copies can lead to many difficulties, you need to check the progress of the copying process at least every day.
- Protect your backup database or directory. Each backup application maintains its own database, the loss of which could mean the loss of backups.
- Define a backup time window daily. If job execution times begin to exceed the allotted time window, this is a sign that the system is approaching capacity limits or that there are weak links in performance. Timely detection of such signs can prevent subsequent larger system failures.
- Localization and preservation of “external” systems and volumes. It is necessary to personally verify that the backup copies meet your expectations, primarily relying on your observations rather than on program reports.
- The maximum possible centralization and automation of backup. Consolidating multiple backup tasks into one greatly simplifies the backup process.
- Creation and support of open reports, reports on open problems. Having a log of unresolved problems can help resolve them as quickly as possible, and, as a result, optimize the backup process.
- Incorporating backup into the system change control process.
- Consultations with vendors. It should be ensured that the implemented system fully meets the organization's expectations.
Backup technologies
Safety
Typically, backups occur automatically. Access to data typically requires elevated privileges. So the process that provides the backup runs from under account with elevated privileges - this is where a certain risk creeps in. Read the article
Preparing a new server for operation should begin with setting up backup. Everyone seems to know about this - but sometimes even experienced system administrators make unforgivable mistakes. And the point here is not only that the task of setting up a new server needs to be solved very quickly, but also that it is not always clear which backup method should be used.
Of course, it is impossible to create an ideal method that would suit everyone: everything has its pros and cons. But at the same time, it seems quite realistic to choose a method that best suits the specifics of a particular project.
When choosing a backup method, you must first pay attention to the following criteria:
- Speed (time) of backup to storage;
- Speed (time) of restoring from a backup copy;
- How many copies can be kept with a limited storage size (backup storage server);
- The volume of risks due to inconsistency of backup copies, undeveloped method of performing backups, complete or partial loss of backups;
- Overhead costs: the level of load created on the server when performing a copy, a decrease in the service response speed, etc.
- Rental cost of all services used.
In this article, we will talk about the main methods for backing up servers running Linux systems and the most common problems that beginners may encounter in this very important area of system administration.
Scheme for organizing storage and recovery from backup copies
When choosing a backup method organization scheme, you should pay attention to the following basic points:- Backups cannot be stored in the same place as the data being backed up. If you store a backup on the same disk array as your data, you will lose it if the main disk array is damaged.
- Mirroring (RAID1) cannot be compared to backup. The raid only protects you from a hardware problem with one of the disks (and sooner or later such a problem will occur, since the disk subsystem is almost always the bottleneck on the server). In addition, when using hardware raids there is a risk of controller failure, i.e. you need to keep a spare model of it.
- If you store backups within one rack in a DC or simply within one DC, then in this situation there are also certain risks (you can read about this, for example,.
- If you store backup copies in different DCs, then network costs and the speed of recovery from a remote copy increase sharply.
Often the reason for data recovery is damage to the file system or disks. Those. backups need to be stored somewhere on a separate storage server. In this case, the problem may be the “width” of the data transmission channel. If you have a dedicated server, then it is highly advisable to perform backups on a separate network interface, and not on the same one that exchanges data with clients. Otherwise, your client’s requests may not “fit” into the limited communication channel. Or due to customer traffic, backups will not be made on time.
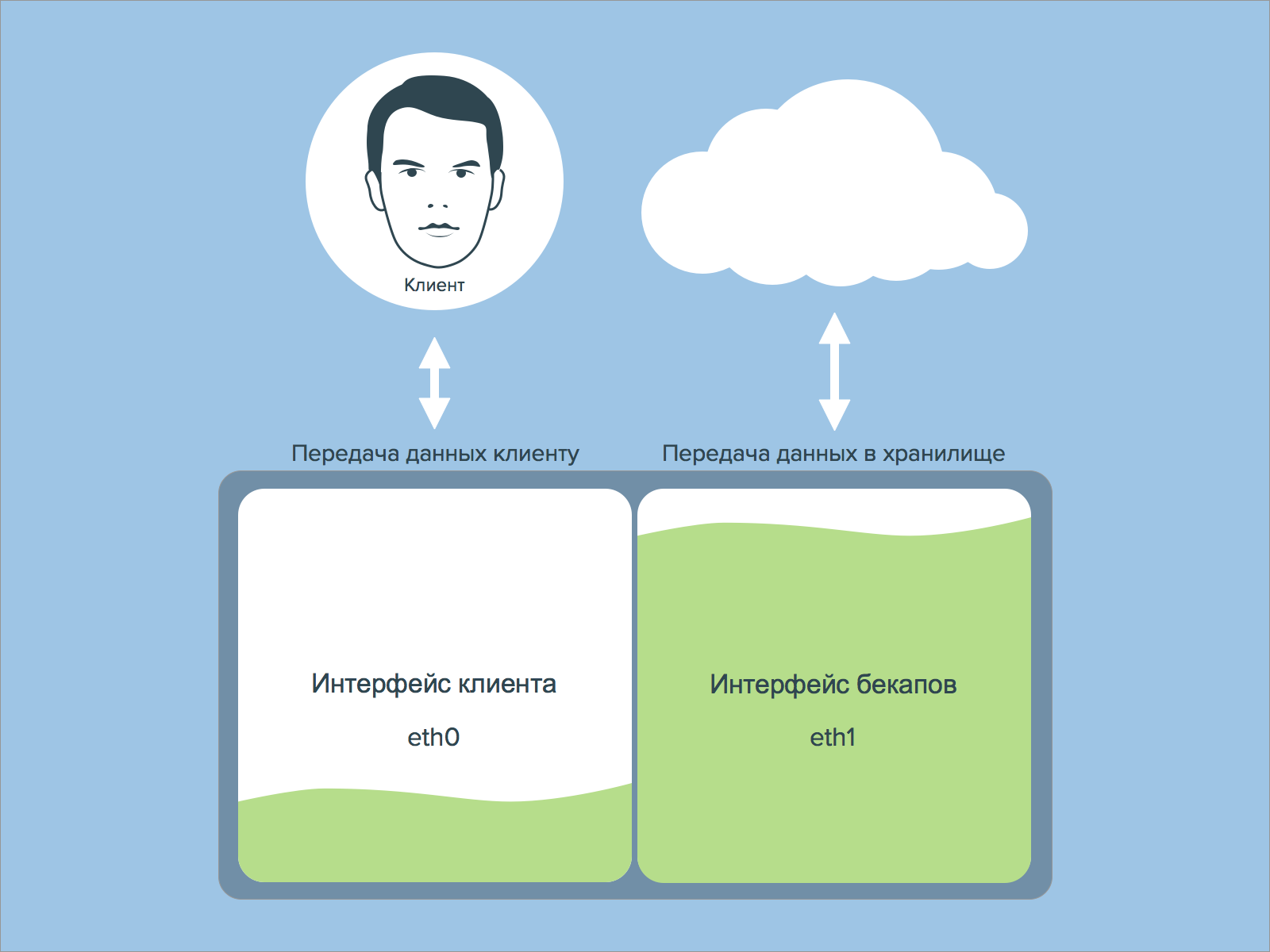
Next, you need to think about the scheme and time of data recovery in terms of storing backups. You may be quite happy with a backup being completed in 6 hours at night on a storage facility with a limited access speed, but a 6-hour recovery is unlikely to suit you. This means that access to backup copies should be convenient and data should be copied quickly enough. So, for example, restoring 1TB of data with a 1Gb/s bandwidth will take almost 3 hours, and that’s if you don’t run into performance issues disk subsystem in storage and server. And don’t forget to add to this the time it takes to detect the problem, the time it takes to decide to rollback, the time it takes to check the integrity of the recovered data, and the amount of subsequent dissatisfaction among clients/colleagues.
Incremental backup
At incremental backup only copies files that have changed since the previous backup. Subsequent incremental backups only add files that have changed since the previous one. On average, incremental backups take less time because fewer files are copied. However, the data recovery process takes longer because the data from the last full backup must be restored, plus the data from all subsequent incremental backups. In this case, unlike differential copying, changed or new files do not replace old ones, but are added to the media independently.
Incremental copying is most often done using the rsync utility. With its help, you can save storage space if the number of changes per day is not very large. If the changed files are large, they will be copied completely without replacing previous versions.
The backup process using rsync can be divided into the following steps:
- A list of files on the redundant server and in the storage is compiled, metadata (permissions, modification time, etc.) or a checksum (when using the —checksum key) is read for each file.
- If the metadata of the files differs, then the file is divided into blocks and a checksum is calculated for each block. Blocks that differ are uploaded to storage.
- If a change is made to the file while the checksum is being calculated or the file is being transferred, its backup is repeated from the beginning.
- By default, rsync transfers data via SSH, which means each block of data is additionally encrypted. Rsync can also be run as a daemon and transfer data without encryption using its protocol.
With more detailed information You can find out more about how rsync works on the official website.
For each file, rsync performs very a large number of operations. If there are a lot of files on the server or if the processor is heavily loaded, then the backup speed will be significantly reduced.
From experience we can say that problems on SATA disks (RAID1) begin after approximately 200G of data on the server. In fact, everything, of course, depends on the number of inodes. And in each case, this value can shift in one or the other direction.
After a certain point, the backup execution time will be very long or simply will not be completed in a day.
In order not to compare all files, there is lsyncd. This daemon collects information about changed files, i.e. we will already have a list of them ready for rsync in advance. However, it should be taken into account that it puts additional load on the disk subsystem.
Differential Backup
At differential In a backup, every file that has changed since the last full backup is backed up each time. Differential copying speeds up the recovery process. All you need is the latest full and latest differential backup. Differential backups are growing in popularity since all copies of files are made at certain points in time, which, for example, is very important when infected with viruses.
Differential backup is carried out, for example, using a utility such as rdiff-backup. When working with this utility, the same problems arise as with incremental backups.
In general, if you perform a full file search when looking for differences in data, the problems of this kind of backup are similar to the problems with rsync.
We would like to separately note that if in your backup scheme each file is copied separately, then it is worth deleting/excluding files that you do not need. For example, these could be CMS caches. Such caches usually contain a lot of small files, the loss of which will not affect the correct operation of the server.
Full backup
A full backup usually affects your entire system and all files. Weekly, monthly and quarterly backups involve creating a complete copy of all data. It is usually performed on Fridays or over the weekend, when copying a large amount of data does not affect the organization's work. Subsequent backups, performed Monday through Thursday until the next full backup, can be differential or incremental, primarily to save time and storage space. Full backups should be performed at least weekly.
Most related publications recommend performing a full backup once or twice a week, and using incremental and differential backups the rest of the time. There is a reason for such advice. In most cases, a full backup once a week is sufficient. It makes sense to run it again if you do not have the ability to update a full backup on the storage side and to ensure the correctness of the backup copy (this may be necessary, for example, in cases where for one reason or another you do not trust the scripts you have or backup software.
In fact, a full backup can be divided into 2 parts:
- Full backup at the file system level;
- Full device-level backup.
Let's look at their characteristic features using an example:
root@komarov:~# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/komarov_system-root 3.4G 808M 2.4G 25% / /dev/mapper/komarov_system-home 931G 439G 493G 48% /home udev 383M 4.0K 383M 1% /dev tmpfs 107M 104K 107M 1% /run tmpfs 531M 0 531M 0% /tmp none 5.0M 0 5.0M 0% /run/lock none 531M 0 531M 0% /run/shm /dev/xvda1 138M 22M 109M 17% /boot
We will only reserve /home. Everything else can be quickly restored manually. You can also deploy a server with a configuration management system and connect our /home to it.
Full backup at the file system level
Typical representative: dump.The utility creates a “dump” of the file system. You can create not only a full, but also an incremental backup. dump works with the inode table and “understands” the file structure (so sparse files are compressed).
Dumping a running file system is "stupid and dangerous" because the file system may change while the dump is being created. It must be created from a snapshot (a little later we will discuss the features of working with snapshots in more detail), a mounted or frozen file system.
This scheme also depends on the number of files, and its execution time will increase with the amount of data on the disk. At the same time, dump has a higher operating speed than rsync.
If you need to restore not the entire backup copy, but, for example, only a couple of accidentally corrupted files), retrieving such files with the restore utility may take too much time
Full device-level backup
- mdraid and DRBD
In fact, RAID1 is configured with a disk/raid on the server and network drive, and from time to time (based on the frequency of backups) additional disk synchronized with the main disk/raid on the server.The biggest plus is speed. The duration of synchronization depends only on the number of changes made in the last day.
This backup system is used quite often, but few people realize that the backup copies obtained with its help may be ineffective, and here's why. When disk synchronization is complete, the disk containing the backup copy is disconnected. If, for example, we have a DBMS running that writes data to local disk portions, storing intermediate data in the cache, there is no guarantee that they will even end up on the backup disk. At best, we will lose some of the data being changed. Therefore, such backups can hardly be considered reliable. - LVM+dd
Snapshots are a wonderful tool for creating consistent backups. Before creating a snapshot, you need to reset the cache of the FS and your software to the disk subsystem.
For example, with MySQL alone it would look like this:
$ sudo mysql -e "FLUSH TABLES WITH READ LOCK;" $ sudo mysql -e "FLUSH LOGS;" $ sudo sync $ sudo lvcreate -s -p r -l100%free -n %s_backup /dev/vg/%s $ sudo mysql -e "UNLOCK TABLES;"
* Colleagues tell stories about how someone’s “read lock” sometimes led to deadlocks, but in my memory this has never happened.
DBMS backups can be created separately (for example, using binary logs), thereby eliminating downtime during the cache reset. You can also create dumps in storage by launching a DBMS instance there. Backup different DBMSs is a topic for separate publications.
You can copy a snapshot using resuming (for example, rsync with a patch for copying block devices bugzilla.redhat.com/show_bug.cgi?id=494313), you can block by block and without encryption (netcat, ftp). You can transfer blocks in compressed form and mount them into storage using AVFS, and mount a partition with backups via SMB on the server.
Compression eliminates problems of transmission speed, channel congestion, and storage space. But, however, if you do not use AVFS in storage, then it will take you a lot of time to restore only part of the data. If you use AVFS, you will encounter its “dampness”.
An alternative to block compression is squashfs: you can mount, for example, a Samba partition to the server and run mksquashfs, but this utility also works with files, i.e. depends on their quantity.
In addition, when creating squashfs, quite a lot of RAM is wasted, which can easily lead to calling oom-killer.
Safety
It is necessary to protect yourself from a situation where the storage or your server is hacked. If the server is hacked, then it is better that the user who writes data there does not have rights to delete/change files in the storage.If the storage is hacked, then it is also advisable to limit the rights of the backup user on the server to the maximum.
If the backup channel can be eavesdropped, then encryption is needed.
Conclusion
Each backup system has its own pros and cons. In this article, we tried to highlight some of the nuances when choosing a backup system. We hope they will help our readers.As a result, when choosing a backup system for your project, you need to conduct tests of the selected type of backup and pay attention to:
- backup time in the current stage of the project;
- backup time in case there is much more data;
- channel load;
- load on the disk subsystem on the server and in the storage;
- time to restore all data;
- recovery time for a pair of files;
- the need for data consistency, especially databases;
- memory consumption and presence of oom-killer calls;
As backup solutions, you can use supload and our cloud storage.
Readers who cannot leave comments here are invited to join us on the blog.
Tags: Add tags
ALEXEY BEREZHNOY, System Administrator. Main areas of activity: virtualization and heterogeneous networks. Another hobby besides writing articles is popularizing free software
Backup
Theory and practice. Summary
To organize a backup system most effectively, you need to build a real strategy for saving and restoring information
Backup (or, as it is also called, backup - from the English word “backup”) is an important process in the life of any IT structure. It is a parachute for rescue in the event of an unforeseen disaster. At the same time, backup is used to create a kind of historical archive of a company's business activities over a certain period of its life. Working without a backup is like living under the open sky - the weather can turn bad at any moment, and there is nowhere to hide. But how to organize it correctly so as not to lose important data and not spend fantastic amounts of money on it?
Typically, articles on the topic of organizing backups discuss mainly technical solutions, and only occasionally pay attention to the theory and methodology of organizing data storage.
This article will focus on just the opposite: the focus will be on general concepts, A technical means will be touched upon as examples only. This will allow us to abstract from hardware and software and answer two main questions: “Why are we doing this?”, “Can we do this faster, cheaper and more reliably?”
Goals and objectives of backup
In the process of organizing a backup, two main tasks are set: restoring the infrastructure in the event of failures (Disaster Recovery) and maintaining a data archive in order to subsequently provide access to information for past periods.
A classic example of a backup copy for Disaster Recovery is the image of the server system partition created by the program Acronis True Image.
An example of an archive would be the monthly download of databases from 1C, recorded on cassette tapes and subsequent storage in a specially designated place.
There are several factors that differentiate a quick recovery backup from an archive:
- Data storage period. For archival copies it takes quite a long time. In some cases, it is regulated not only by business requirements, but also by law. For disaster recovery copies it is relatively small. Usually they create one or two (with increased reliability requirements) backup copies for Disaster Recovery with a maximum interval of a day or two, after which they are overwritten with fresh ones. In particularly critical cases, it is possible to update the backup copy more frequently for disaster recovery, for example, once every few hours.
- Fast access to data. The speed of access to a long-term archive is not critical in most cases. Usually the need to “raise data for the period” arises at the moment of reconciliation of documents, return to previous version etc., that is, not in emergency mode. Another thing is disaster recovery, when the necessary data and service performance must be returned as soon as possible. In this case, the speed of access to the backup is an extremely important indicator.
- Composition of copied information. The backup copy typically contains only user and business data for a specified period. In addition to this data, the copy intended for disaster recovery contains either system images or copies of operating system settings and application software, as well as other information necessary for recovery.
Sometimes it is possible to combine these tasks. For example, a year's worth of monthly complete "snapshots" file server, plus changes made during the week. A suitable tool for creating such a backup copy is True Image.
The most important thing is to clearly understand why the reservation is being made. Let me give you an example: a critical SQL server failed due to a disk array failure. We have a suitable one in stock Hardware, so the solution to the problem was only to restore the software and data. The company's management treats an understandable question: “When will it start working?” – and is unpleasantly surprised to learn that it will take four whole hours to recover. The fact is that throughout the entire service life of the server, only databases were regularly backed up without taking into account the need to restore the server itself with all settings, including software the DBMS itself. Simply put, our heroes only saved the databases and forgot about the system.
Let me give you another example. Throughout the entire period of his work, the young specialist created, using the ntbackup program, a single copy of the file server under Windows control Server 2003, including data and System State in a shared folder on another computer. Due to shortage disk space this copy was constantly overwritten. After some time, he was asked to restore a previous version of a multi-page report that had been damaged when saved. It is clear that, not having archived history with Shadow Copy turned off, he was unable to complete this request.
|
On a note Shadow Copy, literally – “shadow copy”. Ensures that instant copies of the file system are created in such a way that further changes to the original have no effect on them. Using this feature, it is possible to create multiple hidden copies of a file over a certain period of time, as well as on-the-fly backup copies of files opened for writing. The Volume Copy Shadow Service is responsible for the operation of Shadow Copy. System State, literally – “state of the system”. System State Copy creates backup copies of critical components operating systems Windows family. This allows you to restore a previously installed system after destruction. When copying System State, the registry, boot and other files important for the system are saved, including for recovery Active Directory, Certificate Service database, COM+Class Registration database, SYSVOL directories. In UNIX operating systems, an indirect analogue of copying System State is saving the contents of the /etc, /usr/local/etc directories and other files necessary to restore the system state. |
What follows from this: you need to use both types of backup: both for disaster recovery and for archival storage. In this case, it is necessary to determine the list of copied resources, the execution time of the tasks, as well as where, how and for how long the backup copies will be stored.
With small amounts of data and a not very complex IT infrastructure, you can try to combine both of these tasks in one, for example, making a daily full copy of all disk partitions and databases. But it is still better to distinguish between two goals and select the right means for each of them. Accordingly, a different tool is used for each task, although there are also universal solutions, such as the Acronis True Image package or the ntbackup program
It is clear that when defining the goals and objectives of backup, as well as solutions for implementation, it is necessary to proceed from business requirements.
When implementing a disaster recovery task, you can use different strategies.
In some cases, it is necessary to directly restore the system to bare metal. This can be done, for example, using Acronis programs True Image bundled with the Universal Restore module. In this case, the server configuration can be returned to operation in a very short time. For example, it is quite possible to recover a partition with a 20 GB operating system from a backup in eight minutes (provided that the backup copy is accessible over a 1 Gb/s network).
In another option, it is more expedient to simply “return” the settings to the newly installed system, such as, for example, copying configuration files from the /etc folder and others in UNIX-like systems (in Windows this roughly corresponds to copying and restoring System State). Of course, with this approach, the server will be put into operation no earlier than the operating system has been installed and the necessary settings have been restored, which will take much more long term. But in any case, the decision on what kind of Disaster Recovery should be stems from business needs and resource constraints.
The fundamental difference between backup and redundant redundancy systems
This is another one interest Ask which I would like to touch upon. Redundant equipment redundancy systems mean introducing some redundancy into the hardware in order to maintain functionality in the event of a sudden failure of one of the components. Excellent example in in this case– RAID array (Redundant Array of Independent Disks). In the event of a failure of one disk, you can avoid loss of information and safely replace it, saving data due to the specific organization of the disk array itself (read more about RAID in).
I have heard the phrase: “We have very reliable equipment, we have RAID arrays everywhere, so we don’t need backups.” Yes, of course, the same RAID array will protect data from destruction if one fails hard drive. But from data corruption computer virus or this will not save you from inept user actions. RAID will not save you if the file system collapses as a result of an unauthorized reboot.
|
By the way The importance of distinguishing backup from redundant systems should be assessed when drawing up a plan for copying data, whether it concerns an organization or home computers. Ask yourself why you are making copies. If we are talking about backup, then it means saving data during an accidental (intentional) action. Redundant redundancy makes it possible to save data, including backup copies, in the event of equipment failure. There are now many inexpensive devices on the market that provide reliable backup using RAID arrays or cloud technologies(e.g. Amazon S3). It is recommended to use both types of information backup simultaneously. Andrey Vasiliev, CEO Qnap Russia |
Let me give you one example. There are cases when events develop according to the following scenario: when a disk fails, data is restored through a redundancy mechanism, in particular, using saved checksums. In this case, there is a significant decrease in performance, the server freezes, and control is almost lost. System Administrator, seeing no other way out, reboots the server with a cold restart (in other words, clicks “RESET”). As a result of such live overload, file system errors occur. The best that can be expected in this case is that the disk check program will run for a long time to restore the integrity of the file system. In the worst case scenario, you have to say goodbye to file system and be puzzled by the question of where, how and in what time frame you can restore data and server performance.
You won't be able to avoid backups even if you have a cluster architecture. A failover cluster, in essence, maintains the functionality of the services entrusted to it if one of the servers fails. In the event of the above problems, such as a virus attack or data corruption due to the notorious “human factor,” no cluster will save you.
The only thing that can act as an inferior backup replacement for Disaster Recovery is the presence of a mirror backup server with constant data replication from the main server to the backup one (according to the Primary Standby principle). In this case, if the main server fails, its tasks will be taken over by the backup one, and you won’t even have to transfer data. But such a system is quite expensive and labor-intensive to organize. Let’s not forget about the need for constant replication.
It becomes clear that such a solution is cost-effective only in the case of critical services with high requirements for fault tolerance and minimal recovery time. As a rule, such schemes are used in very large organizations with high commodity and cash turnover. And this scheme is an inferior replacement for backup because, anyway, if the data is damaged by a computer virus, inept user actions, or incorrect work application, data and software on both servers may be affected.
And, of course, no redundant backup system will solve the problem of maintaining a data archive for a certain period.
The concept of “backup window”
Performing a backup places a significant load on the backed-up server. This is especially true for the disk subsystem and network connections. In some cases, when the copying process has a fairly high priority, this may lead to the unavailability of certain services. In addition, copying data at the time of making changes is associated with significant difficulties. Of course, there are technical means to avoid problems while maintaining data integrity in this case, but if possible, it is better to avoid such on-the-fly copying.
The solution to solving these problems described above suggests itself: to postpone the start of the copy creation process to an inactive period of time, when the mutual influence of the backup and other running systems will be minimal. This time period is called the “backup window”. For example, for an organization operating under the 8x5 formula (five eight-hour working days a week), such a “window” is usually weekends and night hours.
For systems operating according to the 24x7 formula (all week round the clock), the period of minimum activity is used as such a period, when there is no high load on the servers.
Types of backup
To avoid unnecessary material costs when organizing backups, and also, if possible, not to go beyond the backup window, several backup technologies have been developed, which are used depending on the specific situation.
Full backup (or Full backup)
It is the main and fundamental method of creating backup copies, in which the selected data array is copied entirely. This is the most complete and reliable type of backup, although it is the most expensive. If it is necessary to save several copies of data, the total stored volume will increase in proportion to their number. To prevent such waste, compression algorithms are used, as well as a combination of this method with other types of backup: incremental or differential. And, of course, a full backup is indispensable when you need to prepare a backup copy for quickly restoring the system from scratch.
Incremental copy
Unlike a full backup, in this case not all data (files, sectors, etc.) are copied, but only those that have changed since the last copy. To determine the copying time, you can use various methods For example, systems running the Windows family of operating systems use a corresponding file attribute (the archive bit) that is set when the file has been modified and cleared by the backup program. Other systems may use the date the file was modified. It is clear that a scheme using this type of backup will be incomplete if a full backup is not carried out from time to time. When performing a full system restore, you need to restore from the last copy created by Full backup, and then alternately “roll up” data from incremental copies in the order in which they were created.
What is this type of copying used for? In the case of creating archival copies, it is necessary to reduce the consumed volumes on storage devices (for example, reduce the number of tape media used). This will also minimize the time it takes to complete backup tasks, which can be extremely important in conditions where you have to work in a busy schedule 24x7 or pump large volumes of information.
There is one caveat to incremental copying that you need to know. Step-by-step recovery returns the necessary deleted files during the recovery period. Let me give you an example. Let's say that a full backup is performed on weekends, and an incremental one on weekdays. The user created a file on Monday, changed it on Tuesday, renamed it on Wednesday, and deleted it on Thursday. So, with a sequential, step-by-step data recovery for a weekly period, we will receive two files: with the old name on Tuesday before the renaming, and with a new name created on Wednesday. This happened because different incremental copies stored different versions the same file, and eventually all variants will be restored. Therefore, when sequentially restoring data from an “as is” archive, it makes sense to reserve more disk space so that deleted files can also fit.
Differential Backup
It differs from incremental in that data is copied from the last moment of Full backup. The data is stored in the archive on a “cumulative basis”. On Windows family systems, this effect is achieved by the fact that the archive bit is not reset during differential copying, so the changed data ends up in the archive copy until a full copy resets the archive bits.
Due to the fact that each new copy created in this way contains data from the previous one, this is more convenient for completely restoring data at the time of the disaster. To do this, you only need two copies: the full one and the last of the differential ones, so you can bring data back to life much faster than gradually rolling out all the increments. In addition, this type of copying is free from the above-mentioned features of incremental copying, when, with a full recovery, old files, like a Phoenix bird, are reborn from the ashes. There is less confusion.
But differential copying is significantly inferior to incremental copying in saving the required space. Since each new copy stores data from previous ones, the total volume of reserved data can be comparable to a full copy. And, of course, when planning the schedule (and calculating whether the backup process will fit into the time window), you need to take into account the time it takes to create the last, thickest, differential copy.
Backup topology
Let's look at what backup schemes there are.
Decentralized scheme
The core of this scheme is a certain general network resource(see Fig. 1). For example, a shared folder or an FTP server. A set of backup programs is also required, which from time to time downloads information from servers and workstations, as well as other network objects (for example, configuration files from routers) to this resource. These programs are installed on each server and work independently of each other. An undoubted advantage is the ease of implementation of this scheme and its low cost. Standard tools built into the operating system or software such as a DBMS are suitable as copying programs. For example, this could be the ntbackup program for the Windows family, the tar program for UNIX-like operating systems, or a set of scripts containing built-in SQL server commands for unloading databases into backup files. Another advantage is the ability to use various programs and systems, as long as they can all access the target resource for storing backup copies.
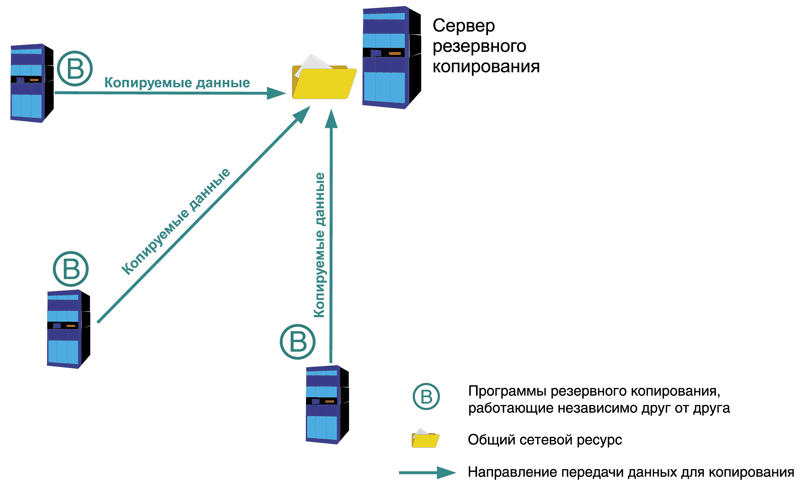
The downside is the clumsiness of this scheme. Since the programs are installed independently of each other, each one has to be configured separately. It is quite difficult to take into account the peculiarities of the schedule and distribute time intervals in order to avoid competition for the target resource. Monitoring is also difficult; the copying process from each server has to be monitored separately from others, which in turn can lead to high labor costs.
Therefore, this scheme is used in small networks, as well as in situations where it is impossible to organize a centralized backup scheme using available means. More detailed description This diagram and practical organization can be found in.
Centralized backup
Unlike the previous scheme, in this case a clear hierarchical model is used, working on the client-server principle. In the classic version, special agent programs are installed on each computer, and the server module of the software package is installed on the central server. These systems also have a specialized backend management console. The control scheme is as follows: from the console we create tasks for copying, restoring, collecting system information, diagnostics, and so on, and the server gives the agents the necessary instructions to perform these operations.
It is on this principle that most popular backup systems work, such as Symantec Backup Exec, CA Bright Store ARCServe Backup, Bacula and others (see Fig. 2).
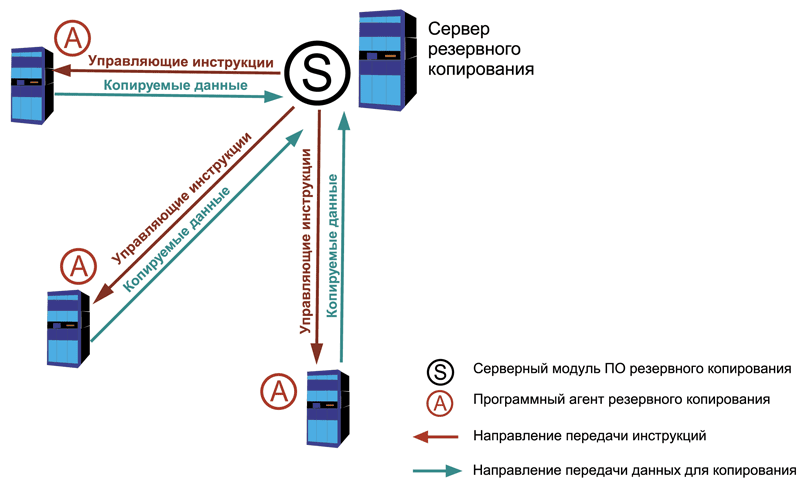
In addition to various agents for most operating systems, there are developments for backing up popular databases and corporate systems, for example, for MS SQL Server, MS Exchange, Oracle Database and so on.
For very small companies, in some cases you can try a simplified version of a centralized backup scheme without the use of agent programs (see Fig. 3). This scheme can also be used if a special agent is not implemented for the backup software used. Instead, the server module will use already existing services. For example, “raking out” data from hidden shared folders on Windows servers or copy files via SSH from servers running UNIX systems. This scheme has very significant limitations associated with the problems of saving files open for writing. As a result of such actions open files will either be missed and not included in the backup copy, or copied with errors. There are various workarounds for this problem, such as running the job again to copy only previously opened files, but none are reliable. Therefore, this scheme is suitable for use only in certain situations. For example, in small organizations working in a 5x8 mode, with disciplined employees who save changes and close files before going home. To organize such a truncated centralized scheme, operating exclusively in Windows environment, ntbackup works well. If you need to use a similar scheme in heterogeneous environments or exclusively among UNIX computers, I recommend looking towards Backup PC (see).
Figure 4. Mixed backup scheme
What is off-site?
In our turbulent, changing world, events can occur that can cause unpleasant consequences for the IT infrastructure and business as a whole. For example, a fire in a building. Or a breakdown of the central heating battery in the server room. Or the banal theft of equipment and components. One method to avoid information loss in such situations is to store backups in a location away from the main location. server equipment. At the same time, it is necessary to provide a quick way to access the data necessary for recovery. The described method is called off-site (in other words, storing copies outside the territory of the enterprise). Basically, two methods of organizing this process are used.
Write data to removable media and their physical movement. In this case, you need to consider a means of quickly getting the media back in the event of a failure. For example, store them in a neighboring building. The advantage of this method is the ability to organize this process without any difficulties. The downside is the difficulty of returning the media and the very need to transfer information for storage, as well as the risk of damaging the media during transportation.
Copying data to another location over a network link. For example, using a VPN tunnel over the Internet. The advantage in this case is that there is no need to transport media with information somewhere, the disadvantage is the need to use a sufficiently wide channel (as a rule, this is very expensive) and protect the transmitted data (for example, using the same VPN). The difficulties encountered in transferring large volumes of data can be significantly reduced by using compression algorithms or deduplication technology.
It is worth mentioning separately about security measures when organizing data storage. First of all, care must be taken to ensure that the data carriers are located in a secure area and that measures are taken to prevent unauthorized persons from reading the data. For example, use an encryption system, enter into non-disclosure agreements, and so on. If removable media is used, the data on it must also be encrypted. The labeling system used should not help the attacker in analyzing the data. It is necessary to use a faceless numbering scheme for marking name carriers transferred files. When transmitting data over a network, it is necessary (as already written above) to use safe methods data transmission, for example, VPN tunnel.
We have discussed the main points when organizing a backup. The next part will look at guidelines and provides practical examples for creating an effective backup system.
- Description of backup Windows system, including System State - http://www.datamills.com/Tutorials/systemstate/tutorial.htm.
- Description of Shadow Copy - http://ru.wikipedia.org/wiki/Shadow_Copy.
- Acronis official website – http://www.acronis.ru/enterprise/products.
- Description of ntbackup - http://en.wikipedia.org/wiki/NTBackup.
- Berezhnoy A. Optimizing the operation of MS SQL Server. //System administrator, No. 1, 2008 – pp. 14-22 ().
- Berezhnoy A. We organize a backup system for small and medium-sized offices. //System administrator, No. 6, 2009 – pp. 14-23 ().
- Markelov A. Linux guarding Windows. Review and installation of the BackupPC backup system. //System administrator, No. 9, 2004 – P. 2-6 ().
- Description of VPN – http://ru.wikipedia.org/wiki/VPN.
- Data deduplication - http://en.wikipedia.org/wiki/Data_deduplication.
In contact with