Process management
In the UNIX operating system, processes are created by calling a kernel system function called fork(). When this function is called by a process, the operating system performs the following actions [BASN86].
1. Allocates space in the process table for a new process.
2. Assigns a unique ID to this process.
3. Creates a copy of the parent process image, excluding shared memory areas.
4. Increments the counters of all files owned by the parent process, reflecting the fact that the new process also owns those files.
5. Assigns the process to a ready-to-execute state.
Returns the child process ID to the parent process and the value 0 to the child process.
This method of creating processes may be difficult to visualize because both the parent and child processes perform the same pass through the code at the time of creation. They differ in the value returned by the fork() function: if it is zero, then this is a child process. In this way, it is possible to issue a branch command that will cause the child program to execute or continue the execution of the main branch.
SUMMARY, KEY AND CHECK QUESTIONS
The fundamental building block of modern operating systems is the process. The main function of the operating system is to create, manage and terminate processes. operating system must ensure that each active process is allocated time to execute on the processor, coordinate the activities of processes, resolve conflict situations and allocate processes system resources.
In order for the operating system to be able to manage processes, it maintains a description of each process or a process image. A process image includes the address space in which the process is running and the process's control block. The control block contains all the information that the operating system requires to control the process, including its current state, allocated resources, priority, and other necessary data.
During its existence, a process can transition from one state to another. The most important of all states are the ready state, the running state, and the blocked state. A ready-to-execute process is a process that is not running in this moment, but its execution can begin as soon as the operating system transfers control to it. A running process is a process that is currently running on the processor. In a multiprocessor system, several processes can be in this state at once. A blocked process is one that is waiting for some event to occur, such as an I/O operation to complete.
Processes are interrupted from time to time. An interrupt occurs either as a result of some event external to the process, which is recognized by the processor, or as a result of a call to the operating system control program. In any of these cases, the processor switches to another operating mode and transfers control to the operating system subroutine. After performing its functions, the operating system can continue executing the interrupted process or switch to executing another process.
Key terms
Preemption Interrupt Program status word
Child Process Privileged Blocking State
Process termination mode Execution state
Task Process Ready state
Trap Kernel Mode New Process State
Process Image Parent Process State
Process switching Suspension swapping
Switching modes System mode Control unit
User Mode Process Trace
Control questions
3.1. What is a process trace?
3.2. What events result in processes being created?
3.3. Give short description each state appearing in the process processing model presented in Fig. 3.3.
3.4. What is process preemption?
3.5. What is swap and when is it used?
3.6. Why in Fig. 3.6.6 are there two blocked states?
3.7. List four characteristic features suspended processes.
3.8. For which objects does the operating system maintain tables with control information?
3.9. List three general categories of information in a process control block.
3.10. Why do we need two processor operating modes (user mode and kernel mode)?
3.11. What actions does the operating system take when creating a new process?
3.12. What is the difference between a regular interrupt and a trap?
3.13. Give three examples of interruptions.
What is the difference between processor mode switching and process switching?
The material in this chapter is presented in the textbooks given in section 2.9. A description of process management in the UNIX operating system can be found in and. The states of processes and operating system primitives used in process dispatch are discussed.
GOOD94 Goodheart V., Soh J. The Magic Garden Explained: The Internals of UNIX System V Release 4.- Englewood Cliffs, NJ: Prentice Hall, 1994.
GRAY97 Gray J. Interprocess Communication in UNIX: The Nooks and Crannies.- Upper Saddle River, NJ: Prentice Hall, 1997.
NEHM75 Nehmer J. Dispatcher Primitives for the Construction of Operating System Kernels. - Acta Informatica, vol. 5, 1975.
TASKS
Name the five main functions of the operating system in managing processes; Justify in general terms their necessity.
3.1. The following process states are defined: running, ready to run, blocked, and suspended. A process is in a blocked state if it is waiting for permission to use a resource; A process is suspended if it is waiting for a resource that it has already requested to be used to become available. On many operating systems, these two states are combined into one, called the blocked state. In this case, the definition of a suspended state is the same as that used in this chapter. Compare the benefits of using these two sets of states.
3.2. Draw a diagram using queues for the seven-state model shown in Fig. 3.6.6. As a basis, take the diagram presented in Fig. 3.5,6.
3.3. Consider the state transition diagram shown in Fig. 3.6.6. Let's say it's time for the operating system to switch the process. Suppose we have processes both in a ready state and paused ones ready for execution. In addition, at least one of the suspended processes that are ready to run has a higher priority than the priority of any process in the ready state. You can proceed according to one of the following two strategies.
1. Always select a process in a ready state to keep swapping to a minimum.
2. Always give preference to the process with higher priority, even if this means performing swaps that are not necessary.
Suggest an intermediate strategy that attempts to balance the concepts of priority and performance.
3.5. In table Figure 3.13 shows the process states used in the VAX/VMS operating system.
A. Can you find a justification for having such large quantity different states of expectation?
b. Why are there no resident and suspended versions of states such as waiting for a page to load into main memory, waiting for a page access conflict to be resolved, waiting for a general event, waiting for a free page, and waiting for a resource.
V. Draw a state transition diagram and indicate on it the action or event that leads to each of the depicted transitions.
Table 3.13. Process states in the VAX/VMS operating system
Running Process running
Executable (resident) A process that is ready to run and resides in main memory.
Executable (swapped) A process ready to run that has been swapped out from main memory.
Waiting state
page load The process accessed a page that is not in main memory and must wait for it to be read
Waiting state
conflict resolution
page access The process accessed a shared page that another process is already waiting to load, or a personal page that is being read or written.
Waiting state
shared event Wait for a shared event flag to be toggled (event flags are one-bit mechanisms for passing signals from one process to another)
Waiting state
free page The process waits until a free page of main memory is added to the set of pages allocated to it and located in main memory (the working set of the process).
Sleep state The process puts itself into a sleep state
(resident)
Sleep state
(unloaded) A process in sleep state is unloaded from main memory
Waiting for local
events (resident) The process resides in main memory and waits for a local event to occur (usually the event is I/O completion)
Waiting for local
events (unloaded) A process waiting for a local event has been unloaded from main memory
Suspended
(resident) A process put into a waiting state by another process
Suspended
(unloaded) The suspended process is unloaded from main memory
Resource Waiting A process waiting for some system resource to be made available to it.
It is necessary to distinguish system control processes, which represent the work of the operating system supervisor and are involved in the distribution and management of resources, from all other processes: system processing processes that are not part of the operating system kernel, and user processes. For system control processes in most operating systems, resources are allocated initially and unambiguously. These processes manage system resources for which there is competition among all other processes. Therefore, the execution of system control programs is not usually called processes. The term task can only be used in relation to user processes and system processing processes. However, this is not true for all operating systems. For example, in the so-called “microkernel” OS (an example is the QNX real-time OS from Quantum Software systems), most of the control software modules of the OS itself and even drivers have the status of high-priority processes, for which it is necessary to allocate appropriate resources. Similarly, in UNIX systems, execution of system program modules also has the status system processes, which receive resources for their execution.
If we generalize and consider not only ordinary OS general purpose, but also, for example, a real-time OS, then we can say that the process can be in an active and passive (not active) state. IN active state a process can participate in competition for the use of computing system resources, and in a passive process it is only known to the system, but does not participate in competition (although its existence in the system is associated with the provision of RAM and/or external memory). In turn, an active process can be in one of the following states:
- execution- all resources requested by the process have been allocated. Only one process can be in this state at any given time if we are talking about a single-processor computing system;
- readiness to perform- resources can be provided, then the process will go into the running state;
- blocking or waiting- the requested resources could not be provided, or the I/O operation did not complete.
In most operating systems, the latter state, in turn, is divided into many waiting states corresponding to a certain type of resource, due to the absence of which the process goes into a blocked state.
In regular operating systems, as a rule, a process appears when you launch a program. The OS organizes (spawns or allocates) a corresponding process descriptor (see more about this below) for the new process, and the process (task) begins to develop (execute). Therefore, there is no passive state. In a real-time OS (RTOS) the situation is different. Usually, when designing a real-time system, the composition of the programs (tasks) that will have to be executed is already known in advance. Many of their parameters are also known, which must be taken into account when allocating resources (for example, the amount of memory, priority, average execution time, opened files, used devices, etc.). Therefore, task descriptors are created for them in advance so as not to subsequently waste precious time organizing the descriptor and searching for the necessary resources for it. Thus, in an RTOS, many processes (tasks) can be in a state of inactivity, which we have shown in Fig. 1.3, separating this state from the other states with a dotted line.
During its existence, a process can repeatedly make transitions from one state to another. This is due to calls to the operating system with requests for resources and execution of system functions that the operating system provides, interaction with other processes, the appearance of interrupt signals from the timer, channels and input/output devices, as well as other devices. Possible transitions of the process from one state to another are displayed in the form of states in Fig. 1.3. Let us consider these transitions from one state to another in more detail.
A process can move from the idle state to the ready state in the following cases:
- at the command of the operator (user). Occurs in those interactive operating systems where a program can have task status (and at the same time be passive), and not just be an executable file and only receive task status during execution (as happens in most modern PC operating systems);
- when selected from a queue by the scheduler (typical for operating systems operating in batch mode);
- by call from another task (by calling the supervisor, one process can create, initiate, suspend, stop, destroy another process);
- by interruption from an external initiative 1 device (a signal about the completion of some event can trigger the corresponding task);
1 The device is called "initiative" if, upon an interrupt request signal, some task should be launched from it.
- when the scheduled time to start the program arrives.
Rice. 1.3. Process state graph
The last two methods of starting a task, in which the process goes from an idle state to a ready state, are typical for real-time operating systems.
A process that can execute as soon as it is given a processor, and for disk-resident tasks on some systems, RAM, is in a ready state. It is believed that such a process has already been allocated all the necessary resources except the processor.
A process can exit the running state for one of the following reasons:
- the process ends, and by contacting the supervisor, it transfers control to the operating system and reports its completion. As a result of these actions, the supervisor either transfers it to the list of inactive processes (the process goes into a passive state) or destroys it (naturally, it is not the program itself that is destroyed, but precisely the task that corresponded to the execution of a certain program). A process can be forced into an inactive state: by an operator command (the action of this and other operator commands is implemented by a system process that “translates” the command into a request to the supervisor with the requirement to transfer the specified process to an inactive state), or by contacting the operating system supervisor from another task with a requirement to stop this process;
- the process is transferred by the operating system supervisor to a state of readiness for execution due to the appearance of a higher priority task or due to the end of the time slice allocated to it;
- The process is blocked (put into the wait state) either because it has requested an I/O operation (which must be completed before it can continue execution) or because it cannot be given the resource currently requested (the reason for being put into the wait state can be either absence of a segment or page in the case of organizing virtual memory mechanisms, see section “Segment, page and segment-page memory organization” in Chapter 2), as well as by an operator command to suspend a task or on demand through a supervisor from another task.
- When a corresponding event occurs (an I/O operation has completed, a requested resource has been released, a required virtual memory page has been loaded into RAM, etc.), the process is released and placed in a ready-to-execute state.
Thus, the driving force that changes the state of processes is events. One of the main types of events is interrupts.
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Posted on http://www.allbest.ru/
1 . Processes
The concept of process has been introduced by OS developers since the 60s, as a program at runtime. Note that a program is just a file in download format stored on disk, and a process is located in memory at runtime.
Process states
The process is characterized by a number of discrete states, and the change of these states can be caused by various events. Initially, we will limit ourselves to considering the three main states of the process.
A process is in a running state if it is currently allocated a central processing unit (CPU).
A process is in a ready state if it could immediately use the central processor placed at its disposal.
A process is in a blocked state if it is waiting for some event to occur before it can continue executing.
Note that on a single-processor machine, only one process can be in the running state at any given time. Several processes can be in the ready and blocked states, i.e. It is possible to create a list of ready and a list of blocked processes.
The list of ready processes is ordered by priority, with the first process from the list receiving the CPU first. When creating a list of ready processes, each new process is placed at the end of the list, and as previous processes complete execution, it is promoted to the head of the list. The list of blocked processes is not ordered, because Processes are unlocked in the order in which the events they expect occur.
Let's consider a diagram of process X transitions from state to state - a change in process states.
Starting, or selecting a process to run, is the process of giving the CPU to the first process from a list of ready processes. The launch is carried out using the dispatcher program. Let us denote such a change of state as follows: operating system linux
To prevent the exclusive seizure of CPU resources by one process, the OS sets a certain time interval in a special interrupt timer, which is allotted for this process; after the time slice has expired, the timer generates an interrupt signal, through which control is transferred to the OS and the process is transferred from the running state to the ready state. and the first process from the ready list is put into the running state.
Blocking a process is when a process releases the CPU before its allotted time slice has expired, i.e. when a running process initiates, for example, an I/O operation, and thus voluntarily releases the CPU while waiting for said operation to complete.
A process is woken up when an event that the process is waiting for occurs and it transitions from the blocked state to the ready state. So in the case described above, after the completion of the I/O operation.
So, we have identified four possible changes in the state of the process.
Note that the only state change initiated by the process itself is blocking; the rest are initiated by objects external to the process.
Operations on processes
Systems that manage processes must be able to perform a number of operations on them.
Creating a process. operating system linux
Creating a process involves giving the process a name; including its name in the list of process names; determining the initial priority of the process; formation of a control unit for the RSV process; allocation of initial resources to the process.
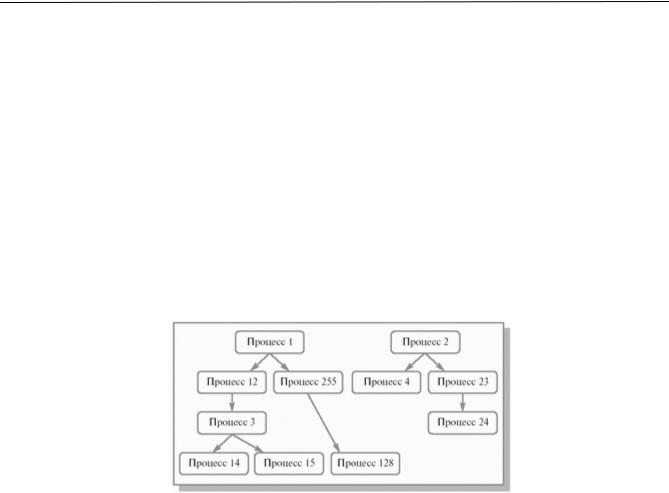
A process can spawn a new process, and in this case, the first will be called the parent process, and the second the child process, and one parent process can have several children, and a child process can have only one parent. This creates a hierarchical process structure.
The UNIX OS, being fundamentally a process management tool, can itself be considered as a system of parallel interactions of processes with a tree structure. The common ancestor of all processes in the UNIX OS is the init process, located at the top of the family tree, this process is constantly present in the system, all other processes are generated according to a unified scheme using the fork() system call.
UNIX assigns each created process a unique process identifier - PID, which identifies the process to the OS. In addition, each process also has a PPID (parent process), which is nothing more than the PID of its parent.
Using the ps command in UNIX, you can see the IDs of the current processes in the system.
Killing a process.
When a process is destroyed, the resources allocated to it are transferred to the system, the name is removed from any lists and tables, and the process control block is released.
Pausing the process.
A suspended process can continue executing when another process activates it.
Resuming the process.
The operation of preparing a process to restart from the point at which it was suspended is called resuming.
Changing the priority of a process.
This operation means modifying the process priority value in the RSV.
In addition, the operations of blocking, waking, and starting a process are used.
Taking into account the introduced concepts of suspending and resuming a process, the picture of changes in process states shown in Fig. 1 can be somewhat supplemented.
For example, the UNIX dispatcher is a program that allows processes to compete with each other for CPU time. Processes are paused and resumed many times per second, creating the effect of a continuous process. The CPU time sharing scheme can be represented as follows:
Process control block
A process control block (PCB) is an object that defines a process for the operating system and is a data structure that concentrates all the key information about the process:
current state of the process;
unique process identifier;
process priority;
process memory pointers;
indicators of resources allocated to the process;
register save area (when the OS switches the CPU from process to process, it uses the register save areas provided in the RSV to remember the information necessary to restart each process when it next receives the CPU).
The concept of processes is basic to the UNIX operating system. In essence, the creation of any process is the creation of some virtual machine. It has its own address space where the procedural segment and the data segment are placed.
Process handle and context. System data used to identify a process that exists throughout its lifetime constitutes a process descriptor. Many descriptors form a process table - in modern versions of UNIX this is several hundred processes.
The process descriptor contains the following process parameters:
location (memory address);
size of the uploaded part of the process image;
process and user ID.
Other important information about the process is stored in the user table (also called the process context), which contains:
user identification numbers to determine file access privileges;
links to the system file table for all files opened by the process;
a pointer to the inode of the current directory in the inode table;
list of reactions to various signals.
Interrupt handling
Interrupt( An interrupt is an event that changes the normal sequence of instructions executed by the processor. If an interruption occurs, then
control is transferred to the OS;
The OS remembers the state of the interrupted process;
The OS analyzes the interrupt type and transfers control to the appropriate interrupt routine.
Let's look at the main types of interrupts.
SVC (supervisor call instruction) interrupts.
The initiator of these interrupts is a running process that executes the SVC command, i.e. a request generated by a user program to provide a specific system service (for example, to perform an I/O operation, to increase the size of allocated memory, etc.). The SVC mechanism allows you to protect the OS from users.
I/O interrupts.
Initiated by I/O hardware, they signal to the CPU that a state change has occurred on a channel or I/O device, such as an I/O operation completing, an error occurring, or the device entering a ready state.
External interrupts.
The causes of such interruptions can be various external events, for example, the expiration of a time slice set on the interrupt timer.
Restart interrupts.
These interrupts occur upon the OS restart command.
Program control interrupts.
These interrupts are caused by various types of errors that occur in a running process, such as an attempt to divide by zero.
Machine control interrupts.
These interrupts are caused by hardware errors.
Context switching
The procedure for handling interruptions, depending on their type, is performed by the corresponding programs included in the OS - interrupt handlers ( IH - interrupt handler).
When an interrupt occurs, the OS must ensure that the state of the interrupted process is remembered and control is transferred to the appropriate interrupt handler. This can be implemented using context switching.
When implementing this method, program status words PSW (program status words) are used, which control the order of command execution and contain a number of information about the state of the process.
On a single-processor machine, there is one current PSW, which contains the address of the next instruction to be executed, as well as the types of interrupts currently enabled and disabled. Six new PSWs, which contain the addresses of the corresponding interrupt handlers, and six old PSWs - one for each type of interrupt.
When an interrupt occurs, the first thing to check is whether it is disabled (in which case it is either delayed or ignored). If the interrupt is enabled, the following PSW switching is performed in hardware:
the current PSW becomes the old PSW for this type of interrupt;
the new PSW for this type of interrupt becomes the current PSW.
After such replacement of status words, the current PSW contains the address of the corresponding interrupt handler, which begins to process this interrupt. When interrupt processing is completed, the CPU begins servicing either the process that was running at the time of the interrupt or the ready process with the highest priority.
The described interrupt handling scheme is not the only possible one.
Operating system kernel
All process-related operations are performed under the control of a part of the OS called the kernel.
The kernel typically resides in RAM, while other parts of the OS move to and from external memory as needed.
Kernel functions
The OS kernel, as a rule, should contain programs to implement the following functions:
interrupt handling;
operations on processes;
process synchronization;
organization of interaction between processes;
manipulation of process control blocks;
I/O support;
file system support;
support for the call-return mechanism when accessing procedures;
a number of accounting functions.
The hierarchical approach to the OS design process is as follows.
At the heart of the hierarchy is the computer hardware, the so-called “pure machine”.
At the next level of the hierarchy are the various kernel functions, together with which the computer becomes an “extended machine”.
These additional functions implemented by the kernel are often called primitives.
Above the kernel in the hierarchy are various OS processes that provide support for user processes - for example, processes for managing external devices.
At the top of the hierarchy are the user processes themselves.
OS experience shows that such hierarchical systems are easier to debug, modify, and test than those where kernel functions
distributed at several levels of the hierarchy.
OS architecture Linux
The Linux system is currently quite widespread (the author of the basic version is Linus Torvalds). The growing influence of Linux was confirmed once again at the LinuxWorldExpo exhibition in early February 2000 in New York. IBM is actively developing applications for Linux, which confirms the high assessment of this OS. “Linux today is growing at the same pace as the Internet in the early 90s, and its popularity is even greater than the popularity of e-business,” said Irving Wladawsky-Berger, vice president of IBM Enterprise System Group. Linux hardware requirements are minimal, perhaps only MS DOS is less demanding on computer hardware than Linux. You can even run Linux on a 386SX/16, 1MB RAM, but this is the minimum that will only make it possible to verify the system’s functionality. A basic set of commands, administration utilities and a command interpreter will take 10 MB.
Linux can “coexist” on a computer with other systems, for example, with MS DOS, MS Windows or OS/2, in this case each of the systems should be located in a separate disk partition, and when the computer starts, an alternative to starting one or another OS will be offered.
Linux is a UNIX-like system, and therefore the principles of its architecture are not much different from the UNIX standard. The most general view allows us to see a two-level model of the system, as it is presented in Fig. A.
At the center is the core of the system. The kernel interacts directly with the computer hardware, isolating application programs from the features of its architecture. The kernel has a set of services provided to application programs. Core services include:
I/O operations (opening, reading, writing and managing files),
creation and management of processes, their synchronization and interprocess interactions.
All applications request kernel services through system calls.
The second level consists of applications or tasks, both system ones, which determine the functionality of the system, and application ones, which provide the Linux user interface. The set of applications that make up the second level of the model defines a particular Linux distribution.
System core
The kernel provides the basic functionality of the OS: it creates and manages processes, allocates memory, and provides access to files and peripheral devices.
Interaction of application tasks with the kernel occurs through a standard system call interface. The system call interface represents a set of kernel services and defines the format of service requests. A process requests a service through a system call to a specific kernel procedure, similar in appearance to calling a regular library function.
The kernel consists of three main subsystems:
file subsystem;
process and memory management subsystem;
input/output subsystem.
File subsystem
The file subsystem provides a unified interface for accessing data located on disk drives and peripheral devices. The same functions open(2), read(2), write(2) can be used both when reading or writing data to disk, and when outputting text to a printer or terminal.
The file subsystem controls file access rights, performs file placement and deletion operations, and writes/reads file data. Since most application functions are performed through the file system interface, file access rights determine the user's privileges on the system.
The file subsystem provides redirection of requests addressed to peripheral devices corresponding to the modules of the input/output subsystem.
Process control subsystem
A program launched for execution generates one or more processes in the system; the tasks of the process management subsystem include:
creating and deleting processes;
distribution of system resources (memory, computing resources) between processes;
process synchronization;
interprocess communication.
The process scheduler is a special kernel module that resolves conflicts between processes and competition for system resources. The scheduler starts the process for execution, making sure that the process does not exclusively take over shared resources. A process releases the processor while waiting for a long I/O operation, or after a time slice has passed. In this case, the scheduler selects the next highest priority process.
The memory management module provides placement random access memory for applied tasks. If there is not enough RAM for all processes, the kernel moves parts of the process or several processes to secondary memory, usually to a special area hard drive, freeing up resources for the running process. All modern operating systems implement virtual memory: the process runs in its own logical address space, which can significantly exceed the available one physical memory. Managing the virtual memory of a process is also the responsibility of the memory management module.
The interprocess communication module is responsible for notifying processes about events using signals and providing the ability to exchange data between different processes.
I/O subsystem
The I/O subsystem fulfills requests from the file subsystem and the process control subsystem to access peripheral devices (disks, terminals, etc.). It provides the necessary data buffering and interacts with device drivers - special kernel modules that directly service external devices.
2. Questions
Define the following terms: program, procedure, process, processor.
Why is it usually not practical to set a priority order for the list of blocked processes?
Describe the four main process state transitions.
Describe the state changes of a process, taking into account suspend and resume operations.
What process information does the PCB contain?
List the main types of interrupts and give an example of each type of interrupt.
Describe the essence of the context switching method.
Define the OS kernel and name its main functions.
Determine the structure of the Linux kernel.
What is the purpose of the file subsystem?
What is the purpose of the process control subsystem?
What are the main functions of the input/output subsystem?
Define the concept - primitives.
What is special about the hierarchical approach to OS design?
Posted on Allbest.ru
Similar documents
History of creation, operating system architecture and list of features implemented in Linux. Tools and development cycle new version kernels. Patch life cycle. Decision-making structure when adding new features (patches) to the kernel.
lecture, added 07/29/2012
Analysis of server operating systems based on the Linux kernel. Approaches to constructing routing and evaluating the results obtained. Installation of the CentOS 6.6 operating system and patterns of its configuration. Principles and main stages of testing the created gateway.
course work, added 11/19/2015
General organization file system. Virtual pages. Commands for working with FS. Ways to organize files. Process control system calls. Algorithm for the process scheduler. Multi-program operating mode of the OS. System core structure.
course work, added 03/23/2015
Learning how software tools work is a difficult part of the debugging process. User mode debuggers, their main types. Automatic start applications in the debugger. Shortcut keys for interruptions. Debugging the operating system kernel.
abstract, added 11/25/2016
Structural organization of the operating system based on various software modules. Functions performed by kernel modules. Operating system modules, designed as utilities. The kernel is in privileged mode. Multilayer structure of the system core.
presentation, added 01/16/2012
Creation software product, designed for a small network with optimization of its operation on the operating platform Linux systems; administration. Development of a control protocol module; subsystem testing methodology; systems engineering analysis.
thesis, added 06/27/2012
Study of the Linux operating system: file elements, directory structure and access rights. Gaining practical skills in working with some commands of this OS. Theoretical information and practical skills in working with Linux processes.
laboratory work, added 06/16/2011
Highlights in the history of operating systems connecting Hardware and application programs. Operating system characteristics Microsoft Windows Seven, analysis of the Linux operating system. Advantages and disadvantages of each operating system.
course work, added 05/07/2011
History of development and Linux versions. Key features, benefits and comparative characteristics operating system. Software characteristics, the main reasons for the success and rapid development of Linux. The main problems of operating system distribution.
course work, added 12/13/2011
Features of the MIPS architecture from MIPS Technology. Hierarchy of memory. Processing jump commands. Address queue. Renaming registers. Justification for choosing an operating system. Perl emulator and kernel build. Electrical and fire safety.
Every new process that appears in the system enters the ready state. The operating system, using some scheduling algorithm, selects one of the ready processes and transfers it to the running state. In the execution state, the process code is directly executed. A process can exit this state for three reasons:
the operating system stops its activity;
it cannot continue its work until some event occurs, and the operating system puts it in a waiting state;
As a result of an interrupt in the computing system (for example, an interrupt from a timer after the specified execution time has expired), it is returned to the ready state.
From the Waiting state, the process enters the Ready state after the expected event has occurred and can be selected for execution again.
Our new model describes well the behavior of processes during their existence, but it does not focus on the appearance of a process in the system and its disappearance. To complete the picture, we need to introduce two more process states: birth and completed execution (see Fig. 2.3).
Rice. 2.3. Process state diagram adopted in the course
Now, in order to appear in the computer system, the process must go through the birth state. At birth, the process receives an address space into which it loads program code process; it is allocated stack and system resources; the initial value of the program counter of this process is set, etc. The newly born process is transferred to the ready state. When completing its activity, the process moves from the executing state to the finished executing state.
In specific operating systems, process states may be even more detailed, and some new options for transitions from one state to another may appear. For example, a process state model for an operating room Windows systems NT contains 7 different states, and for the Unix operating system - 9. Nevertheless, one way or another, all operating systems obey the model outlined above.
Process operations and related concepts
Set of operations
A process cannot move from one state to another on its own. The operating system changes the state of processes by performing operations on them. The number of such operations in our model so far coincides with the number of arrows on the state diagram. It is convenient to combine them into three pairs:
process creation – process termination;
Operating Systems Basics |
suspending the process (transfer from the execution state to the ready state) – starting the process (transfer from the ready state to the execution state);
blocking the process (transfer from the executing state to the waiting state) – unblocking the process (transfer from the waiting state to the ready state).
IN Later, when we talk about scheduling algorithms, our model will contain another operation that does not have a pair: changing the priority of a process.
The operations of creating and terminating a process are one-time operations, since they are applied to a process no more than once (some system processes are never terminated when a computer system is running). All other operations associated with changing the state of processes, whether starting or blocking, are usually reusable. Let's take a closer look at how the operating system performs operations on processes.
Process Control Block and Process Context
In order for the operating system to perform operations on processes, each process is represented in it by some data structure. This structure contains information specific to a given process:
the state the process is in;
the program counter of a process, or, in other words, the address of the instruction that is to be executed next for it;
contents of processor registers;
data needed for CPU scheduling and memory management (process priority, address space size and location, etc.);
credentials ( an identification number process, which user initiated its work, the total processor time used by this process, etc.);
device information I/O associated with the process (for example, which devices are assigned to the process, table of open files).
Its composition and structure depend, of course, on the specific operating system. In many operating systems, information characterizing a process is stored not in one, but in several related data structures. These structures may have different names and contain Additional information or, conversely, only part of the information described. It doesn't matter to us. The only important thing for us is that for any process located in a computer system, all the information necessary to perform operations on it is available to the operating system. For simplicity of presentation, we will assume that it is stored in one data structure. We will call it PCB (Process Control Block) or process control block. The process control block is a process model for the operating system. Any operation performed by the operating system on a process causes certain changes in the PCB. Within the accepted process state model, the contents of the PCB between operations remain constant.
The information for which the process control unit is intended to be stored can be conveniently divided into two parts for further presentation. The contents of all processor registers (including the value of the program counter) will be called the register context of the process, and everything else will be called the system context of the process. Knowledge of the register and system contexts of a process is enough to control its operation in the operating system by performing operations on it. However, this is not enough to fully characterize the process. The operating system is not interested in what kind of calculations the process is engaged in, i.e., what code and what data are in its address space. From the user's point of view, on the contrary, the greatest interest is the contents of the process's address space, perhaps, along with the register context, determining the sequence of data conversion and the results obtained. The code and data located in the address space of the process will be called its user context. For brevity, the set of register, system and user contexts of a process is simply called the process context. At any given time, a process is completely characterized by its context.
Operating Systems Basics |
One-time operations
The complex life path of a process in a computer begins with its birth. Any operating system that supports the concept of processes must have the means to create them. Very simple systems(for example, in systems designed to run only one specific application) all processes can be spawned at the system startup stage. More complex operating systems create processes dynamically as needed. The initiator of the birth of a new process after the operating system starts can be either a user process that made a special system call, or the operating system itself, that is, ultimately, also a certain process. The process that initiated the creation of a new process is usually called the parent process, and the newly created process is called the child process. Processes children can in turn give birth to new children, etc., forming, in general case, within the system is a set of genealogical trees of processes - a genealogical forest. An example of a genealogical forest is shown in Figure 2.4. It should be noted that all user processes, along with some operating system processes, belong to the same forest tree. In a number of computing systems, the forest generally degenerates into one such tree.
Rice. 2.4. Simplified genealogical process forest. The arrow indicates the parent-child relationship
When a process is born, the system starts a new PCB with the birth process state and begins to fill it. The new process gets its own unique identification number. Since a limited number of bits are allocated to store the process identification number in the operating system, to maintain the uniqueness of the numbers, the number of processes simultaneously present in it must be limited. After a process terminates, its released ID number can be reused for another process.
Typically, to perform its functions, a child process requires certain resources: memory, files, I/O devices, etc. There are two approaches to allocating them. The new process may receive some of its parent resources, perhaps sharing rights to them with the parent process and other child processes, or it may obtain its resources directly from the operating system. Information about allocated resources is recorded in the PCB.
After allocating resources to the child process, it is necessary to enter program code, data values, and set a program counter into its address space. There are also two possible solutions here. In the first case, the child process becomes a duplicate of the parent process in register and user contexts, and there must be a way to determine which of the duplicate processes is the parent. In the second case, the child process is loaded with a new program from some file. The Unix operating system allows process spawning only in the first way; for start new program the parent process must first be created, and then the child process must replace its user context using a special system call. The VAX/VMS operating system allows only the second solution. In Windows NT both options are possible (in different APIs).
Spawning a new process as a duplicate of the parent process results in the possibility of programs existing (i.e. executable files), for which more than one process is organized. The ability to replace the user context of a process as it runs (i.e., loaded for execution
Operating Systems Basics |
new program) leads to the fact that several different programs can be executed sequentially within the same process.
After the process is endowed with content, the remaining information is added to the PCB, and the state of the new process changes to ready. It remains to say a few words about how parent processes behave after the birth of child processes. The parent process can continue executing while the child process is executing, or it can wait for some or all of its children to complete.
We will not dwell in detail on the reasons that may lead to completion life cycle process. After the process has completed its work, the operating system transfers it to the completed execution state and releases all resources associated with it, making appropriate entries in the process control block. In this case, the PCB itself is not destroyed, but remains in the system for some time. This is due to the fact that the parent process, after the termination of the child process, can query the operating system about the reason for the “death” of the process it spawned and/or statistical information about its operation. Such information is stored in the PCB of the completed process until the request of the parent process or until the end of its activity, after which all traces of the completed process finally disappear from the system. In the operating room Unix system Processes that are in the finished execution state are usually called zombie processes.
It should be noted that in a number of operating systems (for example, in VAX/VMS), the death of the parent process leads to the termination of the work of all its “children”. In other operating systems (for example, Unix), child processes continue to exist after the parent process ends. In this case, there is a need to change information in the PCB of child processes about the process that generated them in order for the genealogical forest of processes to remain integral. Consider the following example. Let process number 2515 be spawned by process number 2001 and, after its completion, remain in the computer system for an indefinitely long time. Then it is possible that number 2001 will be reused by the operating system for a completely different process. If you do not change the information about the parent process for process 2515, then the genealogical forest of processes will be incorrect - process 2515 will consider the new process 2001 as its parent, and process 2001 will disown the unexpected child. As a rule, "orphaned" processes are "adopted" by one of the system processes, which is spawned when the operating system starts and functions as long as it is running.
Reusable operations
One-time operations result in a change in the number of processes under control of the operating system and are always associated with the allocation or release of certain resources. Reusable operations, on the contrary, do not lead to a change in the number of processes in the operating system and do not have to be associated with the allocation or release of resources.
In this section, we will briefly describe the actions that the operating system performs when performing reusable operations on processes. These actions will be discussed in more detail later in the corresponding lectures.
Start the process. From among the processes in the ready state, the operating system selects one process for subsequent execution. The criteria and algorithms for such a choice will be discussed in detail in Lecture 3 - “Process Planning”. For the selected process, the operating system ensures that the information necessary for its further execution is available in RAM. How she does this will be described in detail in lectures 8-10. Next, the process state changes to execution, the register values for this process are restored, and control is transferred to the command pointed to by the process's program counter. All data needed to restore the context is retrieved from the PCB of the process being operated on.
Pausing the process. A process in the running state is suspended as a result of some interruption. The processor automatically stores the program counter and possibly one or more registers on the stack of the executing process, and then transfers control via a special
Operating Systems Basics |
to the specific processing address for this interrupt. This completes the hardware's interrupt processing activities. One of the parts of the operating system is usually located at the specified address. It stores the dynamic part of the system and register contexts of the process in its PCB, puts the process in the ready state and begins processing the interrupt, that is, performing certain actions related to the interrupt that occurred.
Blocking the process. A process is blocked when it cannot continue to run without waiting for some event to occur on the computing system. To do this, it calls the operating system using a specific system call. The operating system processes the system call (initiates an I/O operation, adds the process to the queue of processes waiting for a device to become free or an event to occur, etc.) and, if necessary, storing the necessary part of the process context in its PCB, transfers the process from the running state to waiting state. This operation will be discussed in more detail in Lecture 13.
Unblocking the process. After an event occurs in the system, the operating system needs to determine exactly what event occurred. Then the operating system checks whether a certain process was in the waiting state for this event, and if so, puts it in the ready state, performing the necessary actions associated with the occurrence of the event (initiating an I/O operation for the next waiting process, etc.) . This operation, like the blocking operation, will be described in detail in Chapter 13.
Context switching
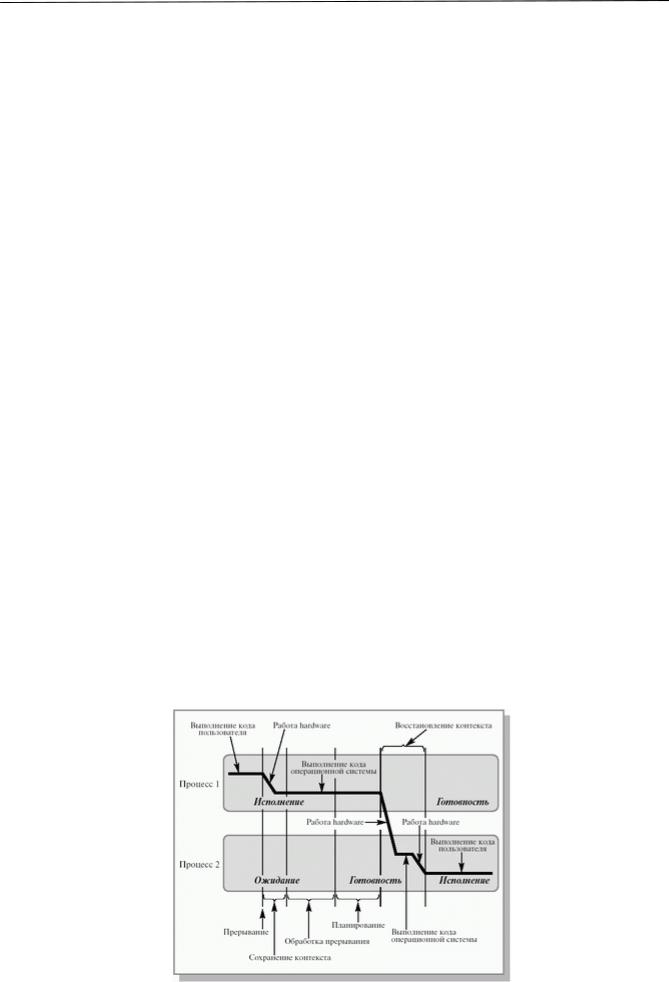
Until now, we have considered operations on processes in isolation, independently of each other. In reality, the activity of a multiprogram operating system consists of chains of operations performed on various processes, and is accompanied by switching the processor from one process to another.
As an example, let's take a simplified look at how the operation of unblocking a process waiting for I/O can proceed in reality (see Fig. 2.5). When the processor executes a certain process (process 1 in the figure), an interrupt occurs from the I/O device, signaling the end of operations on the device. A suspend operation is performed on a running process. Next, the operating system unblocks the process that initiated the I/O request (process 2 in the figure) and launches the suspended or new process selected during scheduling (the unblocked process was selected in the figure). As we can see, as a result of processing information about the end of an I/O operation, it is possible to change the process that is in the executing state.
Rice. 2.5. Performing a process unblocking operation. The use of the term "user code" does not limit the generality of the figure to user processes only

Operating Systems Basics |
To correctly switch the processor from one process to another, it is necessary to save the context of the executing process and restore the context of the process to which the processor will be switched. This procedure for saving/restoring processes is called context switching. The time spent on context switching is not used by the computing system to perform useful work and represents overhead that reduces system performance. It varies from machine to machine and usually ranges from 1 to 1000 microseconds. The extended process model, which includes the concept of threads of execution (execution threads or simply threads), allows you to significantly reduce overhead costs in modern operating systems. We will talk more about execution threads in lecture 4 - “Cooperation of processes and the main aspects of its logical organization.”
Conclusion
The concept of a process characterizes a certain set of executing commands, associated resources and the current moment of its execution, which is under the control of the operating system. At any moment, the process is completely described by its context, consisting of register, system and user parts. In the operating system, processes are represented by a specific data structure - the PCB, which reflects the contents of the register and system contexts.
Processes can be in five main states: birth, ready, executing, waiting, finished executing. A process is transferred from state to state by the operating system as a result of operations performed on it. The operating system can perform the following operations on processes: creating a process, ending a process, suspending a process, starting a process, blocking a process, unblocking a process, changing the priority of a process. The contents of the PCB do not change between operations. The activity of a multiprogram operating system consists of chains of the listed operations performed on various processes, and is accompanied by procedures for saving/restoring the functionality of processes, i.e., context switching. Context switching has nothing to do with useful work, performed by processes, and the time spent on it reduces the useful time of the processor.
3. Lecture: Process planning
This lecture discusses issues related to various levels of process scheduling in operating systems. The main goals and criteria of planning, as well as the parameters on which it is based, are described. Various planning algorithms are presented.
I love the vastness of our plans...
V.V. Mayakovsky The more carefully we plan our activities, the less time remains for its implementation.
From the annals of Gosplan
Whenever we have to deal with a limited amount of resources and several of their consumers, be it a payroll in a work team or a student party with several cases of beer, we are forced to deal with the distribution of available resources between consumers, or, in other words, planning the use of resources. Such planning must have clearly defined goals (what we want to achieve through the allocation of resources) and algorithms that correspond to the goals and are based on consumer parameters. Only with the right choice of criteria and algorithms can you avoid questions such as: “Why do I get ten times less than my boss?” or "Where's my beer?" This lecture is devoted to planning the execution of processes in multiprogram computing systems or, in other words, process planning.
Planning levels
In the first lecture, considering the evolution of computer systems, we talked about two types of scheduling in computing systems: task scheduling and processor scheduling. Job scheduling appeared in batch systems after magnetic disks began to be used to store generated job batches. Magnetic disks, being direct devices
Operating Systems Basics |
Possible access allows you to load tasks into your computer in any order, and not just in the order in which they were written to disk. By changing the order in which jobs are loaded into the computer system, you can increase the efficiency of its use. We called the procedure for selecting the next task to load into the machine, i.e., to spawn the corresponding process, task scheduling. CPU scheduling first appears in multiprogram computing systems, where several processes can be in a ready state at the same time. It is for the procedure of selecting one process from among them that will receive the processor at its disposal, i.e., will be transferred to the execution state, that we used this phrase. Now, having become familiar with the concept of processes in computing systems, we will consider both types of planning as different levels of process planning.
Job scheduling is used as long-term process planning. It is responsible for the generation of new processes in the system, determining its degree of multiprogramming, i.e. the number of processes simultaneously located in it. If the degree of multiprogramming of the system is maintained constant, that is, the average number of processes in the computer does not change, then new processes can appear only after the completion of previously loaded ones. Therefore, long-term planning is carried out quite rarely; minutes or even tens of minutes can pass between the appearance of new processes. The decision to select a particular process to run affects the functioning of the computing system over a fairly long period of time. Hence the name of this level of planning – long-term. Some operating systems have little or no long-term planning. For example, in many interactive time-sharing systems, a process is spawned immediately after the corresponding request appears. Maintaining a reasonable degree of multiprogramming is achieved by limiting the number of users who can work in the system and the peculiarities of human psychology. If 20-30 seconds pass between pressing a key and the character appearing on the screen, then many users will prefer to stop working and continue it when the system is less busy.
CPU scheduling is used as short-term process scheduling. It is carried out, for example, when a running process accesses I/O devices or simply upon completion of a certain time interval. Therefore, short-term planning is carried out, as a rule, at least once every 100 milliseconds. The choice of a new process for execution influences the functioning of the system before the next similar event occurs, i.e., within a short period of time, which explains the name of this level of planning - short-term.
On some computing systems, it may be beneficial to improve performance by temporarily removing a partially executed process from RAM to disk, and later returning it back for further execution. This procedure in English-language literature is called swapping, which can be translated into Russian as “pumping,” although in specialized literature it is used without translation - swapping. When and which of the processes needs to be transferred to disk and returned back is decided by an additional intermediate level of process planning - medium-term.
Planning criteria and requirements for algorithms
For each level of process planning, many different algorithms can be proposed. The choice of a specific algorithm is determined by the class of problems solved by the computing system and the goals that we want to achieve using planning. Such goals include the following:
Fairness - Guaranteeing each job or process a certain percentage of the CPU time on a computer system, trying to prevent a situation where one user's process constantly occupies the CPU while another user's process has not actually started executing.
Efficiency - try to occupy the processor 100% of the working time, not allowing it to idle waiting for processes ready to execute. In real computing systems, processor load ranges from 40 to 90%.
Reducing turnaround time – ensure the minimum time between the start of a process or placing a job in a queue for loading and its completion.
Operating Systems Basics |
Reducing waiting time – reduce the time that processes spend in the ready state and jobs in the queue for loading.
Reducing response time - minimizing the time it takes for a process in interactive systems to respond to a user request.
Regardless of the planning goals, it is also desirable that the algorithms have the following properties.
They were predictable. The same task should be completed in approximately the same time. The use of a planning algorithm should not lead, for example, to extracting the square root of 4 in hundredths of a second on one run and in several days on the second run.
Were associated with minimal overhead costs. If for every 100 milliseconds allocated to a process to use the processor, there will be 200 milliseconds to determine which process will get the processor at its disposal and to switch the context, then such an algorithm is obviously not worth using.
Loaded the computing system resources evenly, giving preference to those processes that would occupy little-used resources.
They were scalable, i.e. they did not immediately lose functionality when the load increased. For example, doubling the number of processes in the system should not lead to an increase in the total execution time of processes by an order of magnitude.
Many of the above goals and properties are contradictory. By improving the performance of the algorithm from the point of view of one criterion, we worsen it from the point of view of another. By adapting the algorithm to one class of problems, we thereby discriminate against problems of another class. “You cannot harness a horse and a tremulous doe to one cart.” It's nothing you can do. That is life.
Planning options
To achieve these goals, reasonable scheduling algorithms must be based on some characteristics of processes in the system, jobs in the download queue, the state of the computer system itself, in other words, on scheduling parameters. In this section we will describe a number of such parameters, without pretending to be complete.
All planning parameters can be divided into two large groups: static parameters and dynamic parameters. Static parameters do not change during the operation of the computing system, while dynamic parameters, on the contrary, are subject to constant changes.
TO static parameters of a computing system include the limiting values of its resources (size of RAM, maximum amount disk memory for swapping, number of connected devices input/output, etc.). Dynamic system parameters describe the amount of free resources at the moment.
TO Static process parameters include characteristics that are usually inherent in tasks already at the loading stage.
Which user started the process or created the task.
How important is the task at hand, i.e. what is the priority of its implementation.
How much CPU time the user requested to solve the problem.
What is the ratio of CPU time to the time required to perform operations I/O
What computer system resources (RAM, devices) I/O, special libraries and system programs etc.) and in what quantities are needed for the task.
Long-term planning algorithms use in their work static and dynamic parameters of the computing system and static parameters of processes (dynamic parameters of processes at the stage of loading jobs are not yet known). Algorithms for short- and medium-term planning

Operating Systems Basics |
The calculations additionally take into account the dynamic characteristics of processes. For medium-term planning, the following information can be used as such characteristics:
how much time has passed since the process was unloaded to disk or loaded into RAM;
how much RAM the process takes up;
how much CPU time has already been allocated to the process.
Rice. 3.1. Fragment of process activity highlighting periods of continuous processor use and I/O waits
For short-term planning, we need to introduce two more dynamic parameters. The activity of any process can be represented as a sequence of cycles of using the processor and waiting for the completion of I/O operations. The period of time of continuous use of the processor is called CPU burst, and the period of time of continuous waiting for I/O is called I/O burst. Figure 3.1. a fragment of the activity of a certain process in a pseudo-programming language is shown, highlighting the indicated intervals. For brevity we will use CPU terms burst and I/O burst without translation. The duration values of the last and next CPU burst and I/O burst are important dynamic parameters of the process.
Preemptive and non-preemptive planning
The scheduling process is carried out by a part of the operating system called the scheduler. The scheduler can decide to select a new process from among those in the ready state to execute in the following four cases.
1. When a process is transferred from the executing state to the finished executing state.
2. When a process is transferred from the running state to the waiting state.
3. When a process is transferred from the running state to the ready state (for example, after a timer interrupt).
4. When a process is transferred from the waiting state to the ready state (the operation has completed I/O or another event occurred). The procedure for such a transfer was discussed in detail in Lecture 2 (section “Context switching”), where we showed why it becomes possible to change the process that is in the executing state.
IN In cases 1 and 2, the process that was in the running state cannot continue to execute, and the operating system is forced to schedule by choosing a new process to execute. In cases 3 and 4, planning may or may not be carried out, the scheduler is not necessarily forced to make a decision on choosing a process for execution, a process that was in the executing state can simply continue its work. If an operating system schedules only in forced situations, it is said to have nonpreemptive scheduling. If the planner makes both forced and unforced decisions, we speak of preemptive planning. The term "preemptive scheduling" arose because a running process, against its will, can be forced out of the running state by another process.

Operating Systems Basics |
Non-preemptive scheduling is used, for example, in MS Windows 3.1 and Apple Macintosh OS. With this scheduling mode, a process takes as much CPU time as it needs. In this case, process switching occurs only if the executing process itself desires to transfer control (to wait for the completion of an I/O operation or at the end of work). This scheduling method is relatively easy to implement and quite effective, since it allows you to allocate most of the processor time to the processes themselves and reduce the cost of context switching to a minimum. However, with non-preemptive scheduling, the problem arises of the possibility of complete capture of the processor by one process, which, due to some reason (for example, due to a program error), goes into a loop and cannot transfer control to another process. In such a situation, the only solution is to reboot the entire computer system.
Preemptive scheduling is commonly used in time sharing systems. In this scheduling mode, the process can be suspended at any time during execution. The operating system sets a special timer to generate an interrupt signal after a certain time interval - a quantum. After an interrupt, the processor is transferred to the next process. Timing interrupts help ensure acceptable process response times for online users and prevent hangs. computer system due to looping of any program.
Planning algorithms
There is a fairly large set of different planning algorithms that are designed to achieve different goals and are effective for different classes of problems. Many of them can be used at several levels of planning. In this section, we will look at some of the most commonly used algorithms as they apply to the short-term planning process.
First-Come, First-Served (FCFS)
The simplest scheduling algorithm is an algorithm that is usually denoted by the abbreviation FCFS after the first letters of its English name - First-Come, First-Served (first come, first served). Let's imagine that processes in the ready state are lined up. When a process enters the ready state, it, or more precisely, a reference to its PCB, is placed at the end of this queue. The selection of a new process for execution is carried out from the beginning of the queue and the reference to its PCB is removed from there. A queue of this type has a special name in programming
– FIFO1), abbreviation for First In, First Out (first in, first out).
This process selection algorithm performs non-preemptive scheduling. A process that has acquired a processor occupies it until the current CPU burst expires. After this, a new process from the front of the queue is selected for execution.
Table 3.1.
The advantage of the FCFS algorithm is the ease of its implementation, but at the same time it has many disadvantages. Consider the following example. Let there be three processes p0, p1 and p2 in the ready state, for which the times of their next CPU burst are known. These times are given in Table 3.1. in some conventional units. For simplicity, we will assume that all processes' activity is limited to using only one CPU burst, that processes do not perform I/O operations, and that context switching time is so short that it can be neglected.
If processes are located in the queue of processes ready for execution in the order p0, p1, p2, then the picture of their execution looks as shown in Figure 3.2. The first process to be executed is p0, which receives the processor for the entire duration of its CPU burst, i.e., 13 time units. After its completion, process p1 is transferred to the execution state; it occupies the processor for 4 units of time. And finally, process p2 gets the opportunity to work. The timeout for process p0 is 0