Что такое кэш память процессора
Выполняет примерно ту же функцию, что и оперативная память . Только кэш - это память встроенная в процессор . Кэш-память используется процессором для хранения информации. В ней буферизируются самые часто используемые данные, за счет чего, время очередного обращения к ним значительно сокращается. Если емкость оперативной памяти на новых компьютерах от 1 Гб, то кэш у них около 2-8 Мб. Как видите, разница в объеме памяти ощутимая. Но даже этого объема вполне хватает, чтобы обеспечить нормальное быстродействие всей системы. Сейчас распространены процессоры с двумя уровнями кэш-памяти: L1 (первый уровень) и L2 (второй). Кэш первого уровня намного меньше кэша второго уровня, он обычно около 128 Кб. Используется он для хранения инструкций. А вот второй уровень используется для хранения данных, поэтому он больше. Кэш второго уровня сейчас у большинства процессоров общий. Но не у всех, вот например у AMD Athlon 64 X 2 у каждого ядра по своему кэшу L2. Кампания AMD обещает в скором времени предоставить процессор AMD Phenom с четырьмя ядрами и тремя уровнями кэш-памяти.
Программный кэш
 Кэш процессора часто путают с программным кэшем. Это совершенно разные вещи, хотя и выполняют схожую функцию. Кэш процессора это микросхема, встроенная в процессор , которая помогает ему быстро обрабатывать информацию. Программный кэш - это папка или какой-нибудь файл на жестком диске, где какая -то программа хранит нужную ей информацию. Рассмотрим на примере: Вы загрузили мой сайт, шапка сайта (картинка, находящаяся в самом верху) и остальные рисунки сохранились кэше вашего браузера. Если вы вернетесь сюда, например, завтра, то картинки уже будут грузиться не из интернета, а из кэша вашего компьютера, что экономит ваши деньги. Если у вас браузер Opera, то папка с изображениями которые вы загружали находится по адресу.
Кэш процессора часто путают с программным кэшем. Это совершенно разные вещи, хотя и выполняют схожую функцию. Кэш процессора это микросхема, встроенная в процессор , которая помогает ему быстро обрабатывать информацию. Программный кэш - это папка или какой-нибудь файл на жестком диске, где какая -то программа хранит нужную ей информацию. Рассмотрим на примере: Вы загрузили мой сайт, шапка сайта (картинка, находящаяся в самом верху) и остальные рисунки сохранились кэше вашего браузера. Если вы вернетесь сюда, например, завтра, то картинки уже будут грузиться не из интернета, а из кэша вашего компьютера, что экономит ваши деньги. Если у вас браузер Opera, то папка с изображениями которые вы загружали находится по адресу.
Чипы на большинстве современных настольных компьютеров имеют четыре ядра, но производители микросхем уже объявили о планах перехода на шесть ядер, а для высокопроизводительных серверов и сегодня 16-ядерные процессоры далеко не редкость.
Чем больше ядер, тем больше проблема распределения памяти между всеми ядрами при одновременной совместной работе. С увеличением числа ядер всё больше выгодно минимизировать потери времени на управлении ядрами при обработке данных - ибо скорость обмена данными отстает от скорости работы процессора и обработки данных в памяти. Можно физически обратиться к чужому быстрому кэшу, а можно к своему медленному, но сэкономить на времени передаче данных. Задача усложняется тем, что запрашиваемые программами объемы памяти не четко соответствуют объемам кэш-памяти каждого типа.
Физически разместить максимально близко к процессору можно только очень ограниченный объем памяти - кэш процесcора уровня L1, объем которого крайне незначителен. Даниэль Санчес (Daniel Sanchez), По-Ан Цай (Po-An Tsai) и Натан Бэкмен (Nathan Beckmann) - исследователи из лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института - научили компьютер конфигурировать разные виды своей памяти под гибко формируемую иерархию программ в реальном режиме времени. Новая система, названная Jenga, анализирует объемные потребности и частоту обращения программ к памяти и перераспределяет мощности каждого из 3 видов процессорного кэша в комбинациях обеспечивающих рост эффективности и экономии энергии.
Для начала исследователи протестировали рост производительности при комбинации статичной и динамической памяти в работе над программами для одноядерного процессора и получили первичную иерархию - когда какую комбинацию лучше применять. Из 2 видов памяти или из одного. Оценивались два параметра -задержка сигнала (латентность) и потребляемая энергия при работе каждой из программ. Примерно 40% программ стали работать хуже при комбинации видов памяти, остальные - лучше. Зафиксировав какие программы «любят» смешанное быстродействие, а какие - размер памяти, исследователи построили свою систему Jenga.
Они виртуально протестировали 4 виды программ на виртуальном компьютере с 36 ядрами. Тестировали программы:
- omnet - Objective Modular Network Testbed, библиотека моделирования C и платформа сетевых средств моделирования (синий цвет на рисунке)
- mcf - Meta Content Framework (красный цвет)
- astar - ПО для отображения виртуальной реальности (зеленый цвет)
- bzip2 - архиватор (фиолетовый цвет)

На картинке показано где и как обрабатывали данные каждой из программ. Буквы показывают, где выполняется каждое приложение (по одному на квадрант), цвета показывают, где находятся его данные, а штриховка указывает на второй уровень виртуальной иерархии, когда он присутствует.
Уровни кэша
Кэш центрального процессора разделён на несколько уровней. Для универсальных процессоров - до 3. Самой быстрой памятью является кэш первого уровня - L1-cache, поскольку расположена на одном с процессором кристалле. Состоит из кэша команд и кэша данных. Некоторые процессоры без L1 кэша не могут функционировать. L1 кэш работает на частоте процессора, и обращение к нему может производиться каждый такт. Зачастую является возможным выполнять несколько операций чтения/записи одновременно. Объём обычно невелик - не более 128 Кбайт.
С кэшем L1 взаимодействует кэш второго уровня - L2. Он является вторым по быстродействию. Обычно он расположен либо на кристалле, как и L1, либо в непосредственной близости от ядра, например, в процессорном картридже. В старых процессорах - набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования - при общем объёме кэша в 8 Мбайт на каждое ядро приходится по 2 Мбайта. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра. В задачах, связанных с многочисленными обращениями к ограниченной области памяти, например, СУБД, его полноценное использование дает рост производительность в десятки раз.
Кэш L3 обычно еще больше по размеру, хотя и несколько медленнее, чем L2 (за счет того, что шина между L2 и L3 более узкая, чем шина между L1 и L2). L3 обычно расположен отдельно от ядра ЦП, но может быть большим - более 32 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании. Применение кэша третьего уровня оправдано в очень узком круге задач и может не только не дать увеличения производительности, но наоборот и привести к общему снижению производительности системы.
Отключение кэша второго и третьего уровней наиболее полезно в математических задачах, когда объём данных меньше размера кэша. В этом случае, можно загрузить все данные сразу в кэш L1, а затем производить их обработку.
Периодически Jenga на уровне ОС реконфигурирует виртуальные иерархии для минимизации объемов обмена данных, учитывая ограниченность ресурсов и поведение приложений. Каждая реконфигурация состоит из четырех шагов.

Jenga распределяет данные не только в зависимости от того, какие программы диспетчеризируются - любящие большую односкоростную память или любящие быстродействие смешанных кэшей, но и в зависимости от физической близости ячеек памяти к обрабатываемым данным. Независимо от того - какой вид кэша требует программа по умолчанию или по иерархии. Главное чтобы минимизировать задержку сигнала и энергозатраты. В зависимости от того, сколько видов памяти «любит» программа, Jenga моделирует латентность каждой виртуальной иерархии с одним или двумя уровнями. Двухуровневые иерархии образуют поверхность, одноуровневые иерархии - кривую. Затем Jenga проектирует минимальную задержку в размерах VL1, что дает две кривые. Наконец, Jenga использует эти кривые для выбора лучшей иерархии (то есть размера VL1).
Применение Jenga дало ощутимый эффект. Виртуальный 36-ядерный чип стал работать на 30 процентов быстрее и использовал на 85 процентов меньше энергии. Конечно, пока Jenga - просто симуляция работающего компьютера и пройдет некоторое время, прежде чем вы увидите реальные примеры этого кеша и еще до того, как производители микросхем примут его, если понравится технология.
Конфигурация условной 36 ядерной машины
- Процессоры
. 36 ядер, x86-64 ISA, 2.4 GHz, Silvermont-like OOO: 8B-wide
ifetch; 2-level bpred with 512×10-bit BHSRs + 1024×2-bit PHT, 2-way decode/issue/rename/commit, 32-entry IQ and ROB, 10-entry LQ, 16-entry SQ; 371 pJ/instruction, 163 mW/core static power - Кэши уровня L1
. 32 KB, 8-way set-associative, split data and instruction caches,
3-cycle latency; 15/33 pJ per hit/miss - Служба предварительной выборки Prefetchers
. 16-entry stream prefetchers modeled after and validated against
Nehalem - Кэши уровня L2 . 128 KB private per-core, 8-way set-associative, inclusive, 6-cycle latency; 46/93 pJ per hit/miss
- Когерентный режим (Coherence) . 16-way, 6-cycle latency directory banks for Jenga; in-cache L3 directories for others
- Global NoC . 6×6 mesh, 128-bit flits and links, X-Y routing, 2-cycle pipelined routers, 1-cycle links; 63/71 pJ per router/link flit traversal, 12/4mW router/link static power
- Блоки статической памяти SRAM . 18 MB, one 512 KB bank per tile, 4-way 52-candidate zcache, 9-cycle bank latency, Vantage partitioning; 240/500 pJ per hit/miss, 28 mW/bank static power
- Многослойная динамическая память Stacked DRAM . 1152MB, one 128MB vault per 4 tiles, Alloy with MAP-I DDR3-3200 (1600MHz), 128-bit bus, 16 ranks, 8 banks/rank, 2 KB row buffer; 4.4/6.2 nJ per hit/miss, 88 mW/vault static power
- Основная память . 4 DDR3-1600 channels, 64-bit bus, 2 ranks/channel, 8 banks/rank, 8 KB row buffer; 20 nJ/access, 4W static power
- DRAM timings . tCAS=8, tRCD=8, tRTP=4, tRAS=24, tRP=8, tRRD=4, tWTR=4, tWR=8, tFAW=18 (все тайминги в tCK; stacked DRAM has half the tCK as main memory)
Приветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?
Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop.ua 2-ядерный процессор с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный , у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.


Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.

Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.

Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.

Arma 3 имеет хорошо выраженную процессорозависимость, а значит больший объем кэш-памяти должен сыграть свою позитивную роль даже при ультравысоких настройках графики. Тем более что нагрузка на видеокарту в обоих случаях достигала максимум 60%.

Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.

Завершает мини-серию живых геймплеев Evolve Stage 2 . Здесь мы наверняка увидели бы разницу между системами, поскольку в обоих случаях видеокарта загружена ориентировочно на половину. Поэтому субъективно кажется, что уровень FPS в случае Core i7 выше, но однозначно сказать нельзя, поскольку сцены не идентичные.

Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе - до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.

Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.

Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.


Больше всего удивила игра Dirt Rally , которую мы запустили с пресетом очень высоко. В определенные моменты разница доходила до 25 кадров/с исключительно из-за большего объема кэш-памяти L3. Это позволяло на 10-15% лучше загружать видеокарту. Однако средние показатели бенчмарка показали более скромную победу Core i7 - всего 11 FPS.


Интересная ситуация получилась и с Rainbow Six Siege : на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.


The Division при максимальном качестве графики также хорошо реагирует на увеличение объема кэш памяти. Уже первые кадры бенчмарка по полной загрузили все потоки Core i3, а вот общая нагрузка на Core i7 составляла 70-80%. Однако разница в скорости в эти моменты составляла всего 2-3 FPS. Чуть позже нагрузка на оба процессора достигла 100%, а разница в определенные моменты уже была за Core i3, но лишь на 1-2 кадра/с. В среднем же она составила около 1 FPS в пользу Core i7.

В свою очередь бенчмарк Rise of Tomb Rider при высоких настройках графики во всех трех тестовых сценах наглядно показал преимущество процессора с значительно большим объемом кэш памяти. Средние показатели у него на 5-6 FPS лучше, но если внимательно посмотреть каждую сцену, то местами отставание Core i3 превышает 10 кадров/с.


А вот при выборе пресета с очень высокими настройками возрастает нагрузка на видеокарту и процессоры, поэтому в большинстве своем разница между системами уменьшается до нескольких кадров. И лишь кратковременно Core i7 может показывать более значимые результаты. Средние показатели его преимущества по итогам бенчмарка снизились до 3-4 FPS.

Hitman также меньше подвержен влиянию кэш-памяти L3. Хотя и здесь при ультравысоком профиле детализации дополнительные 5 МБ обеспечили лучшую загрузку видеокарты, превратив это в дополнительные 3-4 кадра/с. Особо критичного влияния на производительность они не оказывают, но из чисто спортивного интереса приятно, что есть победитель.


Высокие настройки графики Deus ex: Mankind divided сразу же потребовали максимальной вычислительной мощности от обеих систем, поэтому разница в лучшем случае составляла 1-2 кадра в пользу Core i7, на что указывает и средний показатель.


Повторный запуск при ультравысоком пресете еще сильнее загрузил видеокарту, поэтому влияние процессора на общую скорость стало еще меньшим. Соответственно, разница в кэш-памяти L3 практически не влияла на ситуацию и средний FPS отличался менее чем на полкадра.
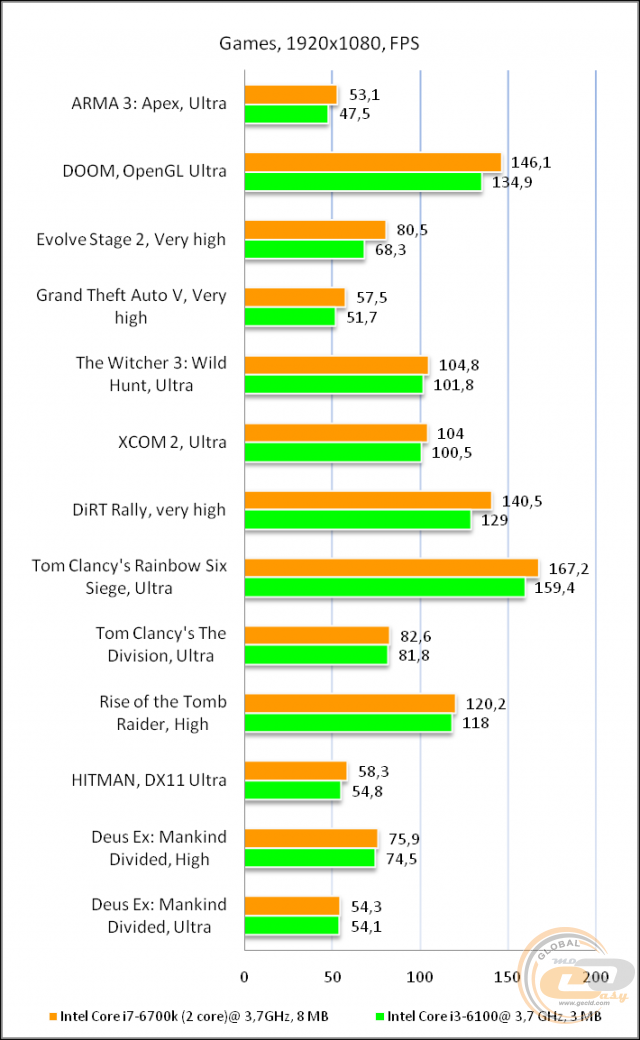
По итогам тестирования можно отметить, что влияние кэш-памяти L3 на производительность в играх действительно имеет место, но оно проявляется лишь тогда, когда видеокарта не загружена на полную мощность. В таких случаях можно было бы получить прирост в 5-10 FPS, если бы кэш увеличился в 2,5 раза. То есть ориентировочно получается, что при прочих равных каждый дополнительный МБ кэш-памяти L3 добавляет только 1-2 FPS к скорости отображения видеоряда.
Так что, если сравнивать соседние линейки, например, Celeron и Pentium, или модели с разным объем кэш-памяти L3 внутри серии Core i3, то основной прирост производительности достигается благодаря более высоким частотам, а потом и наличию дополнительных процессорных потоков и ядер. Поэтому, выбирая процессор, в первую очередь, все же, нужно ориентироваться на основные характеристики, а только потом обращать внимание на объем кэш-памяти.
На этом все. Спасибо за внимание. Надеемся, этот материал был полезным и интересным.
Режим системного управления (System Management Mode)
Защищенный режим (Protected Mode)
Основным режимом работы МП(микропроцессора) является защищенный режим . Ключевые особенности защищенного режима: виртуальное адресное пространство, защита и многозадачность . МП может быть переведен в защищенный режим установкой бита 0 (Protect Enable) в регистре CR0. Вернуться в режим реального адреса МП может по сигналу RESET или сбросом бита PE (в Intel-286 недоступно).
В защищенном режиме программа оперирует с адресами, которые могут относиться к физически отсутствующим ячейкам памяти, поэтому такое адресное пространство называется виртуальным . Размер виртуального адресного пространства программы может превышать емкость физической памяти и достигать 64Тбайт.
Преобразование логического адреса в физический происходит в два этапа: сначала блок управления сегментами выполняет трансляцию адреса в соответствии с сегментированной моделью памяти, получая 32-битный линейный адрес, а затем блок страничного преобразования выполняет разбиение на страницы, преобразуя 32-битный линейный адрес в 32-битный или 36-битный (P6) физический. МП не предусматривает механизмов запрещения сегментации ; с другой стороны, страничная трансляция есть опциональный механизм и может использоваться либо не использоваться в зависимости от особенностей операционной системы.
В рамках сегментированной модели адресации для программы память представляется группой независимых адресных блоков, называемых сегментами. Для адресации байта памяти программа должна использовать логический адрес, состоящий из селектора сегмента и смещения. Селектор сегмента выбирает определенный сегмент, а смещение указывает на конкретный байт в адресном пространстве выбранного сегмента. Селектор сегмента может находиться либо непосредственно в коде команды, либо в одном из сегментных регистров. Смещение также может либо непосредственно находиться в коде команды, либо вычисляться на основе значений регистров общего назначения.
С каждым сегментом связана особая структура, хранящая информацию о нем: дескриптор . Дескриптор - это 8-байтная единица описательной информации, распознаваемая устройством управления памятью в защищенном режиме, хранящаяся в дескрипторной таблице. Дескриптор сегмента содержит базовый адрес описываемого сегмента, предел сегмента и права доступа к сегменту. В защищенном режиме сегменты могут начинаться с любого линейного адреса (который называется базовым адресом сегмента) и иметь любой предел вплоть до 4Гбайт.
Дескрипторные таблицы - это массивы памяти переменной длины, содержащие 8-байтные элементы: дескрипторы. Дескрипторная таблица может иметь длину от 8 байт до 64 Кбайт и в каждой таблице может быть до 8192 дескрипторов. Существуют две обязательных дескрипторных таблицы – глобальная дескрипторная таблица (Global Descriptor Table - GDT ) и дескрипторная таблица прерывания (Interrupt Descriptor Table - IDT ), а также множество (вплоть до 8191) необязательных локальных дескрипторных таблиц (Local Descriptor Table - LDT ), из которых в каждый момент времени процессору доступна только одна. Расположение дескрипторных таблиц определяется регистрами процессора GDTR, IDTR, LDTR.
GDT содержит дескрипторы, доступные всем задачам в системе. GDT может содержать дескрипторы любых типов: и дескрипторы сегментов, и системные дескрипторы (кроме шлюзов прерываний и ловушек). Первый элемент GDT (с нулевым индексом) не используется. Ему соответствует нуль-селектор, обозначающий "пустой" указатель.
LDT обеспечивают способ изоляции сегментов программы и данных исполняемой задачи от других задач. LDT связана с конкретной задачей и может содержать только дескрипторы сегментов, шлюзы вызовов и шлюзы задач.
Сегмент не может быть доступен задаче, если его дескриптор не существует ни в текущей таблице LDT , ни в таблице GDT . Использование двух-дескрипторных таблиц позволяет, с одной стороны, изолировать и защищать сегменты исполняемой задачи, а с другой - позволяет разделять глобальные данные и код между различными задачами.
IDT может содержать только шлюзы задач, шлюзы прерываний или шлюзы ловушек.
Для вычисления линейного адреса МП выполняет следующие действия (рис. 4.1 ):
МП использует селектор сегмента для нахождения дескриптора сегмента. Селектор содержит индекс дескриптора в дескрипторной таблице (Index), бит TI, определяющий, к какой дескрипторной таблице производится обращение (LDT или GDT ), а также запрашиваемые права доступа к сегменту (RPL ). Если селектор хранится в сегментном регистре, то обращение к дескрипторным таблицам происходит только при загрузке селектора в сегментный регистр, т. к. каждый сегментный регистр хранит соответствующий дескриптор в программно-недоступном ("теневом") регистре-кэше.
МП анализирует дескриптор сегмента, контролируя права доступа (сегмент доступен с текущего уровня привилегий ) и предел сегмента (смещение не превышает предел);
МП добавляет смещение к базовому адресу сегмента и получает линейный адрес.
Если страничная трансляция отключена, то сформированный линейный адрес считается физическим и выставляется на шину процессора для выполнения цикла чтения или записи памяти.
Механизм сегментации обеспечивает превосходную защиту, но он не очень удобен для реализации виртуальной памяти (подкачки). В дескрипторе сегмента есть бит присутствия , по нему процессор определяет, находится ли данный сегмент в физической памяти или на внешнем запоминающем устройстве (на винчестере ). В последнем случае генерируется исключение #11, обработчик которого может подгрузить сегмент в память. Неудобство заключается в том, что различные сегменты могут иметь различную длину. Этого можно избежать, если механизм подкачки реализовывать на основе страничного преобразования . Особенностью этого преобразования является то, что процессор в этом случае оперирует с блоками физической памяти равной длины (4 Кбайт) - страницами. Страницы не имеют непосредственного отношения к логической структуре программы. Кроме того, в МП подсемейства P6 страничная трансляция обеспечивает 36-битную физическую адресацию памяти (64 Гбайт). Страничное преобразование действует только в защищенном режиме и включается установкой в 1 бита PG в регистре CR0.
33. Страничная организация – реализация виртуальной памяти.
Каждый компьютер с виртуальной памятью содержит устройство для осуществления отображения виртуальных адресов на физические. Этоиустройство называется контроллером управления памятью (MMU – Memory Management Unit). Он может находиться на микросхеме процессора или на отдельной микросхеме рядом с процессором.ной микросхеме рядом с процессором.
Ч тобы
понять, как работает контроллер управления
памятью, рассмотрим при-
тобы
понять, как работает контроллер управления
памятью, рассмотрим при-
мер на рис. 6.4. Когда в контроллер управления памятью поступает 32-битный вир-
туальный адрес, он разделяет этот адрес на 20-битный номер виртуальной страни-
цы и 12-битное смещение внутри этой страницы (поскольку страницы в нашем
примере по 4 К). Номер виртуальной страницы используется в качестве индекса
в таблице страниц для нахождения нужной страницы. На рис. 6.4 номер виртуаль-
ной страницы равен 3, поэтому из таблицы выбирается элемент 3.
Сначала контроллер управления памятью проверяет, находится ли нужная стра-
н ица
в текущий момент в памяти. Поскольку у
нас есть 220 виртуальных страниц и
ица
в текущий момент в памяти. Поскольку у
нас есть 220 виртуальных страниц и
всего 8 страничных кадров, не все виртуальные страницы могут находиться в па-
мяти одновременно. Контроллер управления памятью проверяет бит присутствия
в данном элементе таблицы страниц. В нашем примере этот бит равен 1. Это зна-
чит, что страница в данный момент находится в памяти.
Рис. 6.4. Формирование адреса основной памяти из адреса виртуальной памяти
(в нашем примере - 6) и скопировать его в старшие три бита 15-битного выходного
регистра. Нужно именно три бита, потому что в физической памяти находится
8 страничных кадров. Параллельно с этой операцией младшие 12 битов виртуально-
го адреса (поле смещения страницы) копируются в младшие 12 битов выходного регистра. Затем полученный 15-битный адрес отправляется в кэш-память или основную память для поиска.
На рисунке 6.5 показано возможное отображение виртуальных страниц в физические страничные кадры. Виртуальная страница 0 находится в страничном кадре 1.
Виртуальная страница 1 находится в страничном кадре 0. Виртуальной страницы 2 и т.д.
Всем пользователям хорошо известны такие элементы компьютера, как процессор, отвечающий за обработку данных, а также оперативная память (ОЗУ или RAM), отвечающая за их хранение. Но далеко не все, наверное, знают, что существует и кэш-память процессора(Cache CPU), то есть оперативная память самого процессора (так называемая сверхоперативная память).
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:

Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
История кэш-памяти
Строго говоря, до того, как кэш-память перебралась на персоналки, она уже несколько десятилетий успешно использовалась в суперкомпьютерах.
Впервые кэш-память объемом всего в 16 КБ появилась в ПК на базе процессора i80386. На сегодняшний день современные процессоры используют различные уровни кэша, от первого (самый быстрый кэш самого маленького объема – как правило, 128 КБ) до третьего (самый медленный кэш самого большого объема – до десятков МБ).
Сначала внешняя кэш-память процессора размещалась на отдельном чипе. Со временем, однако, это привело к тому, что шина, расположенная между кэшем и процессором, стала узким местом, замедляющим обмен данными. В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
Долгое время в процессорах существовали всего два уровня кэша, но в CPU Intel Itanium впервые появилась кэш-память третьего уровня, общая для всех ядер процессора. Существуют и разработки процессоров с четырехуровневым кэшем.
Архитектуры и принципы работы кэша
На сегодняшний день известны два основных типа организации кэш-памяти, которые берут свое начало от первых теоретических разработок в области кибернетики – принстонская и гарвардская архитектуры. Принстонская архитектура подразумевает единое пространство памяти для хранения данных и команд, а гарвардская – раздельное. Большинство процессоров персональных компьютеров линейки x86 использует раздельный тип кэш-памяти. Кроме того, в современных процессорах появился также третий тип кэш-памяти – так называемый буфер ассоциативной трансляции, предназначенный для ускорения преобразования адресов виртуальной памяти операционной системы в адреса физической памяти.
Упрощенно схему взаимодействия кэш-памяти и процессора можно описать следующим образом. Сначала происходит проверка наличия нужной процессору информации в самом быстром - кэше первого уровня, затем - в кэше второго уровня, и.т.д. Если же нужной информации в каком-либо уровне кэша не оказалось, то говорят об ошибке, или промахе кэша. Если информации в кэше нет вообще, то процессору приходится брать ее из ОЗУ или даже из внешней памяти (с жесткого диска).
Порядок поиска процессором информации в памяти:

Именно таким образом Процессор осуществляет поиск инфоромации
Для управления работой кэш-памяти и ее взаимодействия с вычислительными блоками процессора, а также ОЗУ существует специальный контроллер.
Схема организации взаимодействия ядра процессора, кэша и ОЗУ:

Кэш-контроллер является ключевым элементом связи процессора, ОЗУ и Кэш-памяти
Следует отметить, что кэширование данных – это сложный процесс, в ходе которого используется множество технологий и математических алгоритмов. Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Методы записи кэша
Существует два основных метода записи информации в кэш-память:
- Метод write-back (обратная запись) – запись данных производится сначала в кэш, а затем, при наступлении определенных условий, и в ОЗУ.
- Метод write-through (сквозная запись) – запись данных производится одновременно в ОЗУ и в кэш.
Архитектура ассоциативности кэш-памяти
Архитектура ассоциативности кэша определяет способ, при помощи которого данные из ОЗУ отображаются в кэше. Существуют следующие основные варианты архитектуры ассоциативности кэширования:
- Кэш с прямым отображением – определенный участок кэша отвечает за определенный участок ОЗУ
- Полностью ассоциативный кэш – любой участок кэша может ассоциироваться с любым участком ОЗУ
- Смешанный кэш (наборно-ассоциативный)
На различных уровнях кэша обычно могут использоваться различные архитектуры ассоциативности кэша. Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Заключение
В этой статье вы познакомились с понятием кэш-памяти, архитектурой кэш-памяти и методами кэширования, узнали о том, как она влияет на производительность современного компьютера. Наличие кэш-памяти позволяет значительно оптимизировать работу процессора, уменьшить время его простоя, а, следовательно, и увеличить быстродействие всей системы.