В наше время существует две самые популярные архитектуры процессоров. Это x86, которая была разработана еще 80х годах и используется в персональных компьютерах и ARM — более современная, которая позволяет сделать процессоры меньше и экономнее. Она используется в большинстве мобильных устройств или планшетов.
Обе архитектуры имеют свои плюсы и минусы, а также сферы применения, но есть и общие черты. Многие специалисты говорят, что за ARM будущее, но у нее остаются некоторые недостатки, которых нет в x86. В нашей сегодняшней статье мы рассмотрим чем архитектура arm отличается от x86. Рассмотрим принципиальные отличия ARM или x86, а также попытаемся определить что лучше.
Что такое архитектура?
Процессор — это основной компонент любого вычислительного устройства, будь то смартфон или компьютер. От его производительности зависит то, насколько быстро будет работать устройство и сколько оно сможет работать от батареи. Если говорить просто, то архитектура процессора — это набор инструкций, которые могут использоваться при составлении программ и реализованы на аппаратном уровне с помощью определенных сочетаний транзисторов процессора. Именно они позволяют программам взаимодействовать с аппаратным обеспечением и определяют каким образом будут передаваться данные в память и считываться оттуда.
На данный момент существуют два типа архитектур: CISC (Complex Instruction Set Computing) и RISC (Reduced Instruction Set Computing). Первая предполагает, что в процессоре будут реализованы инструкции на все случаи жизни, вторая, RISC — ставит перед разработчиками задачу создания процессора с набором минимально необходимых для работы команд. Инструкции RISC имеют меньший размер и более просты.

Архитектура x86
Архитектура процессора x86 была разработана в 1978 году и впервые появилась в процессорах компании Intel и относится к типу CISC. Ее название взято от модели первого процессора с этой архитектурой — Intel 8086. Со временем, за неимением лучшей альтернативы эту архитектуру начали поддерживать и другие производители процессоров, например, AMD. Сейчас она является стандартом для настольных компьютеров, ноутбуков, нетбуков, серверов и других подобных устройств. Но также иногда процессоры x86 применяются в планшетах, это довольно привычная практика.
Первый процессор Intel 8086 имел разрядность 16 бит, далее в 2000 годах вышел процессор 32 битной архитектуры, и еще позже появилась архитектура 64 бит. Мы подробно рассматривали в отдельной статье. За это время архитектура очень сильно развилась были добавлены новые наборы инструкций и расширения, которые позволяют очень сильно увеличить производительность работы процессора.
В x86 есть несколько существенных недостатков. Во-первых — это сложность команд, их запутанность, которая возникла из-за длинной истории развития. Во-вторых, такие процессоры потребляют слишком много энергии и из-за этого выделяют много теплоты. Инженеры x86 изначально пошли по пути получения максимальной производительности, а скорость требует ресурсов. Перед тем, как рассмотреть отличия arm x86, поговорим об архитектуре ARM.
Архитектура ARM
Эта архитектура была представлена чуть позже за x86 — в 1985 году. Она была разработана известной в Британии компанией Acorn, тогда эта архитектура называлась Arcon Risk Machine и принадлежала к типу RISC, но затем была выпущена ее улучшенная версия Advanted RISC Machine, которая сейчас и известна как ARM.
При разработке этой архитектуры инженеры ставили перед собой цель устранить все недостатки x86 и создать совершенно новую и максимально эффективную архитектуру. ARM чипы получили минимальное энергопотребление и низкую цену, но имели низкую производительность работы по сравнению с x86, поэтому изначально они не завоевали большой популярности на персональных компьютерах.
В отличие от x86, разработчики изначально пытались получить минимальные затраты на ресурсы, они имеют меньше инструкций процессора, меньше транзисторов, но и соответственно меньше всяких дополнительных возможностей. Но за последние годы производительность процессоров ARM улучшалась. Учитывая это, и низкое энергопотребление они начали очень широко применяться в мобильных устройствах, таких как планшеты и смартфоны.
Отличия ARM и x86
А теперь, когда мы рассмотрели историю развития этих архитектур и их принципиальные отличия, давайте сделаем подробное сравнение ARM и x86, по различным их характеристикам, чтобы определить что лучше и более точно понять в чем их разница.
Производство
Производство x86 vs arm отличается. Процессоры x86 производят только две компании Intel и AMD. Изначально эта была одна компания, но это совсем другая история. Право на выпуск таких процессоров есть только у этих компаний, а это значит, что и направлением развития инфраструктуры будут управлять только они.
ARM работает совсем по-другому. Компания, разрабатывающая ARM, не выпускает ничего. Они просто выдают разрешение на разработку процессоров этой архитектуры, а уже производители могут делать все, что им нужно, например, выпускать специфические чипы с нужными им модулями.
Количество инструкций
Это главные различия архитектуры arm и x86. Процессоры x86 развивались стремительно, как более мощные и производительные. Разработчики добавили большое количество инструкций процессора, причем здесь есть не просто базовый набор, а достаточно много команд, без которых можно было бы обойтись. Изначально это делалось чтобы уменьшить объем памяти занимаемый программами на диске. Также было разработано много вариантов защит и виртуализаций, оптимизаций и многое другое. Все это требует дополнительных транзисторов и энергии.
ARM более прост. Здесь намного меньше инструкций процессора, только те, которые нужны операционной системе и реально используются. Если сравнивать x86, то там используется только 30% от всех возможных инструкций. Их проще выучить, если вы решили писать программы вручную, а также для их реализации нужно меньше транзисторов.
Потребление энергии
Из предыдущего пункта выплывает еще один вывод. Чем больше транзисторов на плате, тем больше ее площадь и потребление энергии, правильно и обратное.
Процессоры x86 потребляют намного больше энергии, чем ARM. Но на потребление энергии также влияет размер самого транзистора. Например, процессор Intel i7 потребляет 47 Ватт, а любой процессор ARM для смартфонов — не более 3 Ватт. Раньше выпускались платы с размером одного элемента 80 нм, затем Intel добилась уменьшения до 22 нм, а в этом году ученые получили возможность создать плату с размером элемента 1 нанометр. Это очень сильно уменьшит энергопотребление без потерь производительности.

За последние годы потребление энергии процессорами x86 очень сильно уменьшилось, например, новые процессоры Intel Haswell могут работать дольше от батареи. Сейчас разница arm vs x86 постепенно стирается.
Тепловыделение
Количество транзисторов влияет еще на один параметр — это выделение тепла. Современные устройства не могут преобразовывать всю энергию в эффективное действие, часть ее рассеивается в виде тепла. КПД плат одинаковый, а значит чем меньше транзисторов и чем меньше их размер — тем меньше тепла будет выделять процессор. Тут уже не возникает вопрос ARM или x86 будет выделять меньше теплоты.
Производительность процессоров
ARM изначально не были заточены для максимальной производительности, это область преуспевания x86. Отчасти этому причина меньше количество транзисторов. Но в последнее время производительность ARM процессоров растет, и они уже могут полноценно использоваться в ноутбуках или на серверах.
Выводы
В этой статье мы рассмотрели чем отличается ARM от x86. Отличия довольно серьезные. Но в последнее время грань между обоими архитектурами стирается. ARM процессоры становятся более производительными и быстрыми, а x86 благодаря уменьшению размера структурного элемента платы начинают потреблять меньше энергии и выделять меньше тепла. Уже можно встретить ARM процессор на серверах и в ноутбуках, а x86 на планшетах и в смартфонах.
А как вы относитесь к этим x86 и ARM? За какой технологией будущее по вашему мнению? Напишите в комментариях! Кстати, .
На завершение видео о развитии арихтектуры ARM:
Основные особенности архитектуры
SSE4 состоит из 54 инструкций, 47 из них относят к SSE4.1 (они есть только в процессорах Penryn). Полный набор команд (SSE4.1 и SSE4.2, то есть 47 + оставшиеся 7 команд) доступен в процессорах Nehalem . Ни одна из SSE4 инструкций не работает с 64-битными mmx регистрами, только со 128-битными xmm0-15. 32-битных процессоров с SSE4 не было выпущено.
Добавлены инструкции, ускоряющие компенсацию движения в видеокодеках , быстрое чтение из USWC памяти, множество инструкций для упрощения векторизации программ компиляторами. Кроме того, в SSE4.2 добавлены инструкции обработки строк 8/16 битных символов, вычисления CRC32, popcnt. Впервые в SSE4 регистр xmm0 стал использоваться как неявный аргумент для некоторых инструкций.
Новые инструкции SSE4.1 включают ускорение видео, работу с векторными примитивами, вставки/извлечения, скалярное умножение векторов, смешивания, проверки бит, округления, чтение WC-памяти.
Новые инструкции SSE4.2 включают обработку строк, подсчёт CRC32, подсчет популяции единичных бит, работу с векторными примитивами.
SSE5
Новое расширение x86 инструкций от AMD, названное SSE5. Этот абсолютно новый набор SSE инструкций, созданный специалистами AMD, станет поддерживаться перспективными CPU компаниями, начиная с 2009 года.
SSE5 привносят в классическую x86 архитектуру некоторые возможности, доступные ранее исключительно в RISC процессорах. Набор инструкций SSE5 определяет 47 новых базисных команд, призванных ускорить однопоточные вычисления благодаря увеличению «плотности» обрабатываемых данных.
Среди новых инструкций выделяется две основные группы. В первую входят инструкции, аккумулирующие результаты умножения. Инструкции такого типа могут быть полезны для организации итерационных вычислительных процессов при рендеринге изображений или при создании трёхмерных аудио эффектов. Вторая группа новых команд включает инструкции, оперирующие с двумя регистрами и сохраняющие результат в третьем. Это нововведение может позволить разработчикам обойтись без лишних пересылок данных между регистрами в вычислительных алгоритмах. Также SSE5 содержит и несколько новых инструкций для сравнения векторов, для перестановки и перемещения данных, а также для изменения точности и округления.
Основными применениями для SSE5 AMD видит расчётные задачи, обработку мультимедиа контента и средства шифрования. Ожидается, что в счётных приложениях, использующих матричные операции, использование SSE5 может дать 30%-й прирост производительности. Мультимедийные задачи, требующие выполнения дискретного косинусного преобразования, могут получить 20%-е ускорение. А алгоритмы шифрования благодаря SSE5 способны получить пятикратный выигрыш в скорости обработки данных.
AVX
Следующий набор расширений от Intel. Поддерживается обработка чисел с плавающей запятой упакованных в 256-битные «слова». Для них вводится поддержка тех же команд, что и в семействе SSE. 128-битные регистры SSE XMM0 - XMM15 расширяются до 256-битных YMM0-YMM15
Intel Post 32nm processor extensions - новый набор инструкций Intel, позволяющий конвертировать числа с половинной точностью в числа с одинарной и двойной, аппаратно получать истинно случайные числа и обращаться к регистрам FS/GS.
AVX2
Дальнейшее развитие AVX. Целочисленные команды SSE начинают работать с 256-битными AVX регистрами.
AES
Расширение системы команд AES - реализация в микропроцессоре шифрования AES .
3DNow!
Набор инструкций для потоковой обработки вещественных чисел одинарной точности. Поддерживается процессорами AMD начиная с K6-2. Процессорами Intel не поддерживается.
Инструкции 3DNow! используют регистры MMX в качестве операндов (в один регистр помещается два числа одинарной точности), поэтому, в отличие от SSE, при переключении задач не требуется отдельно сохранять контекст 3DNow!.
64-битный режим
Суперскалярность - означает, что процессор позволяет выполнять более одной операции за один такт. Суперконвейерность означает, что процессор имеет несколько вычислительных конвейеров . У Pentium их два, что позволяет ему при одинаковых частотах в идеале быть вдвое производительней 486, выполняя сразу 2 инструкции за такт.
Кроме того, особенностью процессора Pentium являлся полностью переработанный и очень мощный на то время блок FPU , производительность которого оставалась недостижимой для конкурентов вплоть до конца 1990-х годов.
Pentium OverDrive
Кроме того, в ядро Pentium II был добавлен блок MMX.
Celeron
Первый представитель этого семейства базировался на архитектуре Pentium II , представлял собой картдридж с печатной платой, на которой монтировались ядро, кэш-память второго уровня и тег кэша. Монтировался в гнездо Slot 2 .
Современные Xeon базируются на архитектуре Core 2 /Core i7 .
Процессоры AMD
Am8086 / Am8088 / Am186 / Am286 / Am386 / Am486Принципиально новый процессор AMD (апрель 1997 года), основанный на ядре, приобретённом у NexGen . Данный процессор имел конструктив пятого поколения, однако относился к шестому поколению и позиционировался как конкурент Pentium II . Включал в себя блок MMX и несколько переработанный блок FPU . Однако данные блоки всё равно работали на 15-20 % медленнее, чем у аналогичных по частоте процессоров Intel. Процессор имел 64 Кбайт кэша первого уровня.
В целом, сравнимая с Pentium II производительность, совместимость со старыми материнскими платами и более ранний старт (AMD представила К6 на месяц раньше, чем Intel представила P-II) и более низкая цена сделали его достаточно популярным, однако проблемы с производством у AMD значительно испортили репутацию данного процессора.
K6-2Дальнейшее развитие ядра К6. В этих процессорах была добавлена поддержка специализированного набора команд 3DNow! . Реальная производительность, однако, оказалась существенно ниже, чем у аналогичных по частоте Pentium II (это было вызвано тем, что прирост производительности с ростом частоты у P-II был выше благодаря внутреннему кэшу) и конкурировать К6-2 смогли лишь с Celeron. Процессор имел 64 Кбайт кэша первого уровня.
K6-IIIБолее успешная в технологическом плане, чем K6-2, попытка создания аналога Pentium III . Однако маркетингового успеха не имела. Отличается наличием 64 Кбайт кэша первого уровня и 256 Кбайт кэша второго уровня в ядре, что позволяло ему на равной тактовой частоте обгонять по производительности Intel Celeron и не очень существенно уступать ранним Pentium III.
K6-III+Аналог K6-III с технологией энергосбережения PowerNow! и более высокой частотой и расширенным набором инструкций. Изначально предназначался для ноутбуков . Устанавливался и в настольные системы с процессорным разъёмом Super 7 . Применялся для апгрейда настольных систем с процессорным разъёмом Socket 7 (Только на материнских платах которые подают на процессор два напряжения питания, первое для блоков ввода/вывода процессора и второе для ядра процессора. Не все изготовители обеспечивали двойное питание на первых моделях своих материнских плат с разъемом Socket 7).
Аналог К6-III+ с урезанным до 128 Кбайт кэшем второго уровня.
AthlonОчень успешный процессор, благодаря которому фирма AMD сумела восстановить почти утраченные позиции на рынке микропроцессоров. Кэш первого уровня - 128 Кбайт. Первоначально процессор выпускался в картридже с размещением кэша второго уровня (512 Кбайт) на плате и устанавливался в разъём Slot A (который механически, но не электрически совместим со Slot 1 от Intel). Затем перешёл на разъём Socket A и имел 256 Кбайт кэша второго уровня в ядре. По быстродействию - примерный аналог Pentium III.
DuronУрезанная версия Athlon, отличается от родителя объёмом кэша второго уровня (всего 64 Кбайт, зато интегрированным в кристалл и работавшем на частоте ядра).
Конкурент Celeron поколений Pentium III / Pentium 4. Производительность заметно выше, чем у аналогичных Celeron, и при выполнении многих задач соответствует Pentium III.
Athlon XPПродолжение развития архитектуры Athlon. По быстродействию - аналог Pentium 4 . По сравнению с обычным Athlon, добавлена поддержка инструкций SSE .
SempronБолее дешёвый (за счёт уменьшенного кэша второго уровня) вариант процессоров Athlon XP и Athlon 64.
Первые модели Sempron являлись перемаркированными чипами Athlon XP на ядре Thoroughbred и Thorton, имевшими 256 Кбайт кэша второго уровня, и работавшими на 166 (333 DDR) шине. Позднее под маркой Sempron выпускались (и выпускаются) урезанные версии Athlon 64/Athlon II, позиционируемые как конкуренты Intel Celeron. Все Sempron имеют урезанный кеш 2-го уровня; младшие модели Socket 754 имели заблокированные Cool&quiet и x86-64 ; Socket 939 модели имели заблокированный двухканальный режим работы памяти.
OpteronПервый процессор, поддерживающий архитектуру x86-64 .
Athlon 64Первый не серверный процессор, поддерживающий архитектуру x86-64.
Athlon 64 X2Продолжение архитектуры Athlon 64, имеет 2 вычислительных ядра.
Athlon FX
Имел репутацию «самого быстрого процессора для игрушек». Является, по сути, серверным процессором Opteron 1xx на десктопных сокетах без поддержки registered-memory. Выпускается малыми партиями. Стоит значительно дороже своих «массовых» собратьев.
PhenomДальнейшее развитие архитектуры Athlon 64, выпускается в вариантах с двумя (Athlon 64 X2 Kuma), тремя (Phenom X3 Toliman) и четырьмя (Phenom X4 Agena) ядрами.
Phenom IIПроцессоры VIA
Cyrix III / VIA C3Первый процессор, выпущенный под маркой VIA . Выпускался с разными ядрами от разных команд разработчиков. Разъём Socket 370 .
Первый выпуск - на базе ядра Joshua, доставшегося VIA вместе с командой разработчиков Cyrix .
Второй выпуск - с ядром Samuel, разработанным на базе так и не вышедшего IDT WinChip -3. Отличался отсутствием кэш-памяти второго уровня и, соответственно, крайне низким уровнем производительности.
Третий выпуск - с ядром Samuel-2, улучшенной версией предыдущего ядра, оснащённой кэш-памятью второго уровня. Процессор выпускался по более тонкой технологии и имел сниженное энергопотребление. После выпуска этого ядра бренд «VIA Cyrix III» окончательно уступил место «VIA С3».
Четвёртый выпуск - с ядром Ezra. Был также вариант Ezra-T, адаптированный для работы с шиной, предназначенной для процессоров Intel с ядром Tualatin . Дальнейшее развитие в направлении энергосбережения.
Пятый выпуск - с ядром Nehemiah (C5P). Это ядро наконец получило полноскоростной сопроцессор, поддержку инструкций или .
Процессоры на основе ядра V33 не имели режима эмуляции 8080, зато поддерживали, при помощи двух дополнительных инструкций, расширенный режим адресации.
Процессоры NexGen
Nx586В марте 1994 был представлен процессор NexGen Nx586. Он позиционировался как конкурент Pentium, однако изначально не имел встроенного сопроцессора. Использование собственной шины повлекло за собой необходимость применения собственных чипсетов, NxVL (VESA Local Bus) и NxPCI 820C500 (PCI), и ни с чем несовместимого процессорного гнезда. Чипсеты разрабатывались совместно с VLSI и Fujitsu. Nx586 был суперскалярным процессором и мог исполнять по две инструкции за такт. Кэш L1 был раздельным (16 Кбайт под инструкции + 16 Кбайт под данные). Контроллер кэша L2 был интегрирован в процессор, сам же кэш находился на материнской плате. Так же, как и Pentium Pro, Nx586 внутри был RISC-процессором. Отсутствие поддержки инструкций CPUID в ранних модификациях этого процессора приводило к тому, что программно он определялся как быстрый 386 процессор. С этим же было связано то, что Windows 95 отказывался устанавливаться на компьютеры с такими процессорами. Для решения этой проблемы применялась специальная утилита (IDON.COM), представлявшая Nx586 для Windows как 586 class CPU. Nx586 выпускался на мощностях IBM.
Был также разработан сопроцессор Nx587 FPU, который монтировался на заводе поверх кристалла процессора. Такие «сборки» получили маркировку Nx586Pf. При обозначении производительности Nx586 использовался P-rating - c PR75 (70 МГц) до PR120 (111 МГц).
Следующее поколение процессоров NexGen, которое так и не было выпущено, однако послужило основой для AMD K6.
Процессоры SiS
SiS550Семейство SoC SiS550 базируется на лицензированном ядре Rise mP6 и выпускается с частотами от 166 до 266 МГц. При этом самые скоростные решения потребляют всего 1,8 Вт. У ядра три целочисленных 8-ступенчатых конвейера. Кэш L1 раздельный, 8+8 Кбайт. Встроенный сопроцессор конвейеризован. В состав SiS550, кроме стандартного набора портов, входят 128-битное UMA-видеоядро AGP 4x, 5.1-канальный звук, поддержка 2-х -инструкции под названием Code Morphing Software. Это позволяет адаптировать процессор к любому набору команд и улучшает энергоэффективность, но производительность такого решения заведомо меньше, чем у процессоров с нативной системой команд x86.математического сопроцессора , а варианты с сопроцессором должны были называться U5D, но так и не были выпущены.
Intel добилась судебного запрета на продажу Green CPU в США, обосновав это тем, что UMC использовала в своих процессорах микрокод Intel, не имея лицензии.
Существовали и некоторые проблемы с ПО. Например, игра Doom отказывалась запускаться на этом процессоре без правки конфигурации, а Windows 95 время от времени зависала. Это было связано с тем, что программы находили в U5S отсутствующий сопроцессор и попытки обращения к нему заканчивались крахом.
Процессоры, выпускавшиеся в СССР и России
КР1810ВМ86Процессоры BLX IC Design/ICT
BLX IC Design и Институт компьютерных технологий Китая с 2001 разрабатывает MIPS-based процессоры с аппаратной трансляцией x86 команд. Выпускаются эти процессоры STMicroelectronics. Рассматривается партнерство с TSMC.
Godson (Longxin, Loongson , Dragon)
Godson - 32-разрядный RISC-процессор на базе MIPS. Технология - 180 нм. Представлен в 2002 году. Частота - 266 МГц, через год - версия с частотой 500 МГц.
Godson 2
- Godson 2 - 64-разрядный RISC-процессор на базе MIPS III. Технология 90 нм. На равной частоте превосходит своего предшественника по быстродействию в 10 раз. Представлен 19 апреля 2005 года.
- Godson-2E - 500 МГц, 750 МГц, позже - 1 ГГц. Технология - 90 нм. 47 млн транзисторов, энергопотребление - 5…7,5 Вт. Первый Godson с аппаратной трансляцией команд x86, причем на неё тратится до 60 % производительности процессора. Представлен в ноябре 2006 года.
- Godson 2F - 1,2 ГГц, выпускается с марта 2007 года. Декларируется повышение производительности по сравнению с предшественником на 20-30 %.
- Godson 2H - планировался к выпуску в 2011 году. Будет оснащен встроенными видеоядром и контроллером памяти и предназначается для потребительских систем.
- Godson 3 - 4 ядра, технология 65 нм. Энергопотребление - около 20 Вт.
- Godson 3B - 8 ядер, технология 65 нм (планируется переход на 28 нм), тактовая частота в пределах 1 ГГц. Площадь кристалла - 300 мм². Производительность на операциях с плавающей точкой составляет 128 GigaFLOPS. Энергопотребление 8-ядерного Godson 3-40 Вт. Трансляция в код x86 выполняется с помощью набора из 200 инструкций, на трансляцию тратится порядка 20 % производительности процессора. В процессоре присутствует 256-разрядный векторный SIMD-блок обработки. Процессор предназначен для использования в серверах и встраиваемых системах.
Структура же произвольной инструкции следующая:
- Префиксы (каждый из них опционален):
- Однобайтовый префикс смены режима адресации AddressSize (значение 67h).
- Однобайтовый префикс изменения сегмента Segment (значения 26h, 2Eh, 36h, 3Eh, 64h и 65h).
- Однобайтовый префикс BranchHint для указания предпочтительной ветки перехода (значения 2Eh и 3Eh).
- Двухбайтовый или трёхбайтовый сложноструктурированный префикс Vex (первый байт всегда имеет значение C4h для двухбайтового варианта или C5h для трёхбайтового).
- Однобайтовый префикс Lock для запрета модификации памяти другими процессорами или ядрами (значение F0h).
- Однобайтовый префикс OperandsSize для изменения размера операнда (значение 66h).
- Однобайтовый префикс Mandatory для уточнения инструкции (значения F2h и F3h).
- Однобайтовый префикс Repeat означает повторение (значения F2h и F3h).
- Однобайтовый структурированный префикс Rex нужен для указания 64-битных или расширенных регистров (имеет значения 40h..4Fh).
- Префикс Escape. Всегда состоит как минимум из одного байта 0Fh. За этим байтом опционально идёт байт 38h или 3Ah. Предназначен для уточнения инструкции.
- Точно определяющие инструкцию байты:
- Байт Opcode (произвольное константное значение).
- Байт Opcode2 (произвольное константное значение).
- Байт Params (имеет сложную структуру).
- Байт ModRm используется для операндов в памяти (имеет сложную структуру).
- Байт SIB так же используется для операндов в памяти и имеет сложную структуру.
- Встроенные в инструкцию данные (опциональны):
- Смещение или адрес в памяти (Displacement). Целое число со знаком размером 8, 16, 32 или 64 бита.
- Первый или единственный непосредственный операнд (Immediate). Может быть размером 8, 16, 32 или 64 бита.
- Второй непосредственный операнд (Immediate2). Если присутствует, то обычно имеет размер в 8 бит.
В списке выше и далее для технических имён принято наименование «только латиница, арабские цифры» и знак минуса «-» со знаком подчёкивания «_», а регистр - CamelCase (любое слово начинается с прописной, а далее только строчные даже если аббревиатура: «UTF-8» → «Utf8» - все слова вместе). Префиксы AddressSize, Segment, BranchHint, Lock, OperandsSize и Repeat могут перемешаны между собой. Остальные элементы должны идти именно в указанном порядке. И видно что байтовые значения некоторых префиксов совпадают. Их назначение и наличие определяет уже сама инструкция. Префиксы переопределения сегмента могут применяться с большинством инструкций, а префиксы BranchHint применяются только с инструкциями условного перехода. Аналогичная ситуация с префиксами Mandatory и Repeat - где-то они уточняют инструкцию, а где-то указывают на повторение. Префикс OperandSize вместе в префиксами Mandatory ещё относят к префиксам SIMD-инструкции. Отдельно следует сказать про префикс Vex. Он заменяет префиксы Rex, Mandatory, Escape и OperandsSize, компактизируя их в себе. С ним не допустимо использование префикса Lock. Сам же префикс Lock может добавляться когда приёмником является операнд в памяти.
Обзорный список всех интересующих режимов с точки зрения кодирования инструкций:
- 16-битный («Real Mode», реальный режим с сегментной адресацией).
- 32-битный («Protected Mode», защищённый режим с плоской моделью памяти).
- 64-битный («Long Mode», как 32-битный защищённый с плоской моделью памяти, но адреса уже 64-битные).
В скобках английские названия режимов соответствуют официальным. Ещё есть синтетические режимы на вроде нереального (Unreal x86 Mode), но они все вытекают из этих трёх (по сути это гибриды, которые отличаются лишь размером адреса, операндов и прочим). В каждом из них используется «родной» режим адресации, но его можно сменить на альтернативный префиксом OperandsSize. В 16-битном режиме включится 32-битный режим адресации, в 32-битном режиме - 16-битный, а в 64-битном - 32-битный. Но если это делать, то адрес расширяется с дополнением нулями (если он меньше) или же его старшие биты сбрасываются (если он больше).
4.6. Особенности архитектуры современных x86 процессоров
4.6.1. Архитектура процессоров Intel Pentium (P5/P6)
Процессоры семейства Pentium имеют ряд архитектурных и структурных особенностей по сравнению с предыдущими моделями микропроцессоров фирмы Intel. Наиболее характерными из них являются:
Гарвардская архитектура с разделением потоков команд и данных при помощи введения отдельных внутренних блоков кэш-памяти для хранения команд и данных, а также шин для их передачи;
Суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
Динамическое исполнение команд, реализующее изменение последовательности команд, использование расширенного регистрового файла (переименование регистров) и эффективное предсказание ветвлений;
Двойная независимая шина, содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Основные характеристики процессоров семейства Pentium следующие:
32-разрядная внутренняя структура;
Использование системной шины с 36 разрядами адреса и 64 разрядами данных;
Раздельная внутренняя кэш-память первого уровня для команд и данных емкостью по 16 Кбайт;
Поддержка общей кэш-памяти команд и данных второго уровня емкостью до 2 Мбайт;
Конвейерное исполнение команд;
Предсказание направления программного ветвления с высокой точностью;
Ускоренное выполнение операций с плавающей точкой;
Приоритетный контроль при обращении к памяти;
Поддержка реализации мультипроцессорных систем;
Наличие внутренних средств, обеспечивающих самотестирование, отладку и мониторинг производительности.
Новая микроархитектура процессоров Pentium (рис. 4.6 ) и более поздних базируется на методе суперскалярной обработки .
Под суперскалярностью подразумевается наличие более одного конвейера для обработки команд (в отличие от скалярной – одноконвейерной архитектуры).
Рисунок 4.6 – Блок-схема архитектуры МП Pentium
В МП Pentium команды распределяются по двум независимым исполнительным конвейерам (U и V). Конвейер U может выполнять любые команды семейства IA-32, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная – в конвейер V.
Однако, такая попарная обработка команд (спаривание) возможна только для ограниченного подмножества целочисленных команд. Команды вещественной арифметики не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам.
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA-32 является динамическое (спекулятивное) исполнение . Под этим термином подразумевается следующая совокупность возможностей:
- глубокое предсказание ветвлений (с вероятностью > 90% можно предсказать 10-15 ближайших переходов);
- анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам);
- опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC, поэтому блок выборки команд , считав поток инструкций IA-32 из L1 кэша инструкций , декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания (пул инструкций) . В нем содержатся как не выполненные пока микрооперации, так и уже выполненные, но еще не повлиявшие на состояние процессора.
Для декодирования инструкций предназначены три параллельных дешифратора : два для простых и один для сложных инструкций.
Каждая инструкция IA-32 декодируется в 1-4 микрооперации. Микрооперации выполняются пятью параллельными исполнительными устройствами : два для целочисленной арифметики , два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации, которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации, следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения , используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Описанная схема отображена на рис. 4.7.

Рисунок 4.7 – Блок схема микропроцессора Pentium Pro
4.6.2. SIMD-расширения ММХ
Многие алгоритмы работы с мультимедийными данными допускают простейшие элементы распараллеливания, когда одна операция может выполняться параллельно над несколькими числами. Такой подход называется SIMD – single-instruction multiple-data (одна инструкция – множество данных) . Впервые эта технология была реализована в поколении P55 (микропроцессор Pentium MMX).
MMX (Multi-Media eXtension) – это SIMD-расширение для потоковой обработки целочисленных данных, реализованное на основе блока FPU (с использованием регистров FPU).
Одна инструкция MMX может выполнить арифметическую или логическую операцию над "пакетами" целых чисел, упакованных в регистрах MMX. Например, инструкция PADDSB складывает 8 байт одного "пакета" с соответствующими восьмью байтами другого пакета, фактически выполняя сложение восьми пар чисел одной инструкцией.
4.6.3. Процессоры Pentium Pro, Pentium II, Pentium III
В процессоре Pentium II соединены лучшие свойства процессоров Intel: производительность процессора Pentium Pro и возможности технологии MMX. Это сочетание обеспечивает существенное увеличение производительности процессоров Pentium II по сравнению с предыдущими процессорами IA-32-архитектуры.
Процессор содержит раздельные внутренние блоки кэш-памяти команд и данных по 16 Кбайт и 512 Кбайт общей неблокирующей кэш-памяти второго уровня.
Повышение производительности IA-32 достигалось не только путем оптимизации конвейера команд и добавления исполнительных блоков, но и, например, внедрением кэш-памяти в ядро процессора. В семействе IA-32 встроенный кэш L1 размером 8 Кбайт впервые был реализован в процессорах Intel-486. В процессорах Pentium размер кэша был удвоен. Первые представители P6 (Pentium Pro) содержали также кэш L2 размером 256 или 512 Кбайт. Однако такое решение в то время оказалось слишком дорогим и невыгодным, поэтому в Pentium II была представлена технология Dual Independent Bus (DIB) – двойная независимая шина. Для доступа к кэшу и для доступа к внешней памяти использовались раздельные шины. Такое же архитектурное решение использовалось в первых моделях Pentium III. Начиная с 1999 года (Pentium III Coppermine), кэш L2 вновь был возвращен внутрь кристаллов процессоров.
Развитием идеи SIMD для вещественных чисел стала технология SSE (Streamed SIMD Extensions) , впервые представленная в процессорах Pentium III. Блок SSE дополняет технологию MMX восемью 128-битными регистрами XMM0-XMM7 и 32-битным регистром управления и состояния MXCSR.
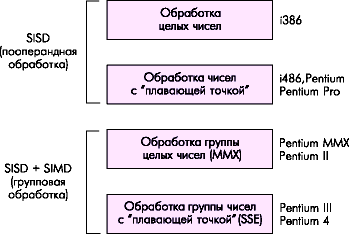
Рисунок 4.9 - Эволюция процесса обработки данных в процессорах Intel Pentium
4.6.4. Pentium 4 (P7) – микроархитектура Net Burst
Процессор Pentium 4 является 32-разрядным представителем семейства IA-32, по микроархитектуре принадлежащим к новому, седьмому (по классификации Intel) поколению. С программной точки зрения он представляет собой процессор IA-32 с очередным расширением системы команд – SSE2 . По набору программно-доступных регистров Pentium 4 повторяет процессор Pentium III. С внешней, аппаратной точки зрения – это процессор с системной шиной нового типа, в которой кроме повышения тактовой частоты применены ставшие уже привычными принципы двойной (2х) и четырехкратной (4х) синхронизации, а также предпринят ряд мер по обеспечению работоспособности на ранее немыслимых частотах. Микроархитектура процессора, получившая название Net Burst, разработана с учетом высоких частот как ядра (более 1,4 ГГц), так и системной шины (400 МГц).
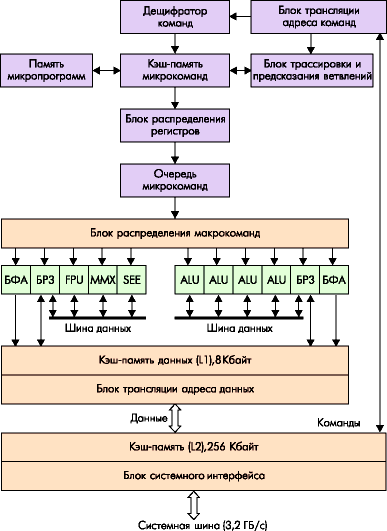
Рисунок 4.10 – Микроархитектура NetBurst
Процессор Pentium 4 является однокристальным. Кроме собственно вычислительного ядра, он содержит кэш-память двух уровней. Вторичный кэш, общий для инструкций и данных, имеет размер 256 Кбайт и разрядность шины 256 бита (32 байта), как и в последних процессорах Pentium III. Шина вторичного кэша работает на частоте ядра, что обеспечивает ее пропускную способность 32х1,4 = 44,8 Гбайт/с на частоте 1,4 ГГц. Вторичный кэш имеет ЕСС-контроль, позволяющий обнаруживать и исправлять ошибки. Первичный кэш данных имеет такую же высокую пропускную способность (44,8 Гбайт/с), но его объем сократился вдвое (8 Кбайт против 16 в Pentium III). Первичный кэш инструкций в привычном понимании отсутствует, его заменил кэш трассы (trace cache). В нем хранятся последовательности микроопераций, в которые декодированы инструкции. Здесь могут помещаться до 12К микроинструкций.
Интерфейс системной шины процессора рассчитан только на однопроцессорные конфигурации. Интерфейс во многом напоминает шину Р6, протокол также ориентирован на одновременное выполнение нескольких транзакций. Принят ряд мер по обеспечению высокой пропускной способности. В процессоре Pentium 4 частота шины 400 МГц с "четырехкратной накачкой" (quad pumped) – тактовая частота системной шины составляет 100 МГц, но частота передачи адресов и данных выше. Новая информация по линиям с общей синхронизацией может передаваться на каждом такте с частотой 100 МГц. Для 2 и 4-кратной передачи используется синхронизация от источника данных.
Исполнительные устройства МП (АЛУ) работают на удвоенной частоте, что дает возможность выполнять большинство целочисленных инструкций за половину такта. По сравнению с предыдущими поколениями IA-32, Pentium 4 содержит самый длинный конвейер команд, состоящий из 20 этапов и названный гиперконвейером . В связи с этой особенностью многие специалисты отмечают, что микроархитектура NetBurst будет иметь максимальную производительность исполнения предсказуемых (линейных и циклических) участков программы, характерных для приложений, на которые ориентирован Pentium 4. На непредсказуемо ветвящихся программах, к которым относятся, например, офисные приложения, длинный гиперконвейер оказывается менее эффективным, чем конвейер Р6, если бы тот удалось разогнать до частот 1,4 ГГц и выше. Чтобы частично компенсировать этот недостаток, были существенно оптимизированы механизмы спекулятивного исполнения и предсказания ветвлений.
Материал главы 4 основан на обобщении работ .
Disclaimer
Наверное, наиболее точно причину появления данного материала можно сформулировать так: «даже не столько нужно, чтобы он был - сколько странно, что его до сих пор не было». И действительно: в комментариях к результатам тестов, мы постоянно оперируем такими понятиями как «ёмкость кэша», «скорость процессорной шины», «поддержка расширенных наборов инструкций», но единой статьи, в которой были бы собраны разъяснения всех этих терминов - на сайте нет. Такое упущение, разумеется, следовало устранить. Данная статья с подзаголовком «x86 CPU FAQ» и является попыткой сделать это. Разумеется, некоторые её разделы могут быть отнесены не только к процессорам архитектуры x86, и не только с десктопным (предназначенным для установки в ПК) их вариантам, однако вот уж на такой глобализм мы совершенно точно не замахиваемся. Поэтому просьба помнить, что в рамках данного материала, если в явной форме не указано иное, слово «процессор» обозначает «процессор архитектуры x86, предназначенный для установки в десктопы». Возможно, в процессе дальнейшего совершенствования и расширения, появятся в статье разделы, посвящённые серверным CPU или даже процессорам других архитектур, но это уже дело будущего…
Введение
Код и данные: основной принцип работы процессора
Итак, если не пытаться изложить здесь «кратенько» курс информатики для средней школы, то единственное что хотелось бы напомнить - это то, что процессор (за редкими исключениями) исполняет не программы, написанные на каком-нибудь языке программирования (один из которых, вы, возможно, даже знаете), а некий «машинный код». То есть командами для него являются последовательности байтов, находящихся в памяти компьютера. Иногда команда может быть равна одному байту, иногда она занимает несколько байт. Там же, в основной памяти (ОЗУ, RAM) находятся и данные. Они могут находиться в отдельной области, а могут и быть «перемешаны» с кодом. Различие между кодом и данными состоит в том, что данные - это то, над чем процессор производит какие-то операции. А код - это команды, которые ему сообщают, какую именно операцию он должен произвести. Для упрощения, мы можем представить себе программу и ее данные в виде последовательности байтов некой конечной длины, располагающуюся непрерывно (не будем усложнять) в общем массиве памяти. Например, у нас есть массив памяти длиной в 1’000’000 байт, а наша программа (вместе с данными) - это байты с номерами от 1000 до 20’000. Прочие байты - это другие программы или их данные, или просто свободная память, не занятая ничем полезным.
Таким образом, «машинный код» - это команды процессора, располагающиеся в памяти. Там же располагаются данные. Для того чтобы исполнить команду, процессор должен прочитать ее из памяти. Для того чтобы произвести операцию над данными, процессор должен прочитать их из памяти, и, возможно, после произведения над ними определенного действия, записать их обратно в память в обновленном (измененном) виде. Команды и данные идентифицируются их адресом, который, по сути, представляет собой порядковый номер ячейки памяти.
Общие принципы взаимодействия
процессора и ОЗУ
Возможно, кого-то удивит, что достаточно большой раздел в FAQ, посвященном x86 CPU, выделен под объяснение особенностей функционирования памяти в современных системах, основанных на данном типе процессоров. Однако факты - упрямая вещь: сами x86-процессоры ныне содержат так много блоков, отвечающих именно за оптимизацию их работы с ОЗУ, что игнорировать эту тесную связь было бы совершенно нелепо. Можно сказать даже так: уж, коль решения, связанные с оптимизацией работы с памятью, стали неотъемлемой частью самих процессоров - то и саму память можно рассматривать в качестве некоего «придатка», функционирование которого оказывает непосредственное влияние на скорость работы CPU. Без понимания особенностей взаимодействия процессора с памятью, невозможно понять, за счёт чего тот или иной процессор (та или иная система) исполняет программы медленнее или быстрее.
Контроллер памяти
Итак, ранее выше мы уже говорили о том, что как команды, так и данные, попадают в процессор из оперативной памяти. На самом деле всё немного сложнее. В большинстве современных x86-систем (то есть компьютеров на базе x86-процессоров), процессор как устройство к памяти обращаться вообще не может, так как не имеет в своем составе соответствующих узлов. Поэтому он обращается к «промежуточному» специализированному устройству, называемому контроллером памяти, а уже тот, в свою очередь - к микросхемам ОЗУ, размещенным на модулях памяти. Модули вы наверняка видели - это такие длинные узкие текстолитовые «планочки» (фактически - небольшие платы) с некоторым количеством микросхем на них, вставляемые в специальные разъемы на системной плате. Роль контроллера ОЗУ, таким образом, проста: он служит своего рода «мостом»* между памятью и использующими ее устройствами (кстати, к ним относится не только процессор, но об этом - чуть позже). Как правило, контроллер памяти входит в состав чипсета - набора микросхем, являющегося основой системной платы. От быстродействия контроллера во многом зависит скорость обмена данными между процессором и памятью, это один из важнейших компонентов, влияющих на общую производительность компьютера.
* - кстати, контроллер памяти физически находится в микросхеме чипсета, традиционно называемой «северным мостом».
Процессорная шина
Любой процессор обязательно оснащён процессорной шиной, которую в среде x86 CPU принято называть FSB (Front Side Bus). Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском, и так далее. Впрочем, как мы уже знаем из предыдущего раздела, между собственно памятью и процессором находится контроллер памяти. Соответственно: процессор посредством FSB связывается с контроллером памяти, а уже тот, в свою очередь, по специальной шине (назовём её, не мудрствуя лукаво, «шиной памяти») - с модулями ОЗУ на плате. Однако, повторимся: поскольку «внешняя» шина у классического x86 CPU всего одна, она используется не только для работы с памятью, но и для общения процессора со всеми остальными устройствами.
Различия между традиционной для
x86 CPU архитектурой и K8/AMD64
Революционность подхода компании AMD состоит в том, что её процессоры с архитектурой AMD64 (и микроархитектурой, которую условно принято называть «K8») оснащены множеством «внешних» шин. При этом одна или несколько шин HyperTransport служат для связи со всеми устройствами кроме памяти, а отдельная группа из одной или двух (в случае двухканального контроллера) шин - исключительно для работы процессора с памятью. Преимущество интеграции контроллера памяти прямо в процессор, очевидно: «путь от ядра до памяти» становится заметно «короче», что позволяет работать с ОЗУ быстрее. Правда, имеются у данного подхода и недостатки. Так, например, если ранее устройства типа жёсткого диска или видеокарты могли работать с памятью через выделенный, независимый контроллер - то в случае с архитектурой AMD64 они вынуждены работать с ОЗУ через контроллер, размещённый на процессоре. Так как CPU в данной архитектуре является единственным устройством, имеющим прямой доступ к памяти. Де-факто, в противостоянии «внешний контроллер vs. интегрированный», сложился паритет: с одной стороны, на данный момент AMD является единственным производителем десктопных x86-процессоров с интегрированным контроллером памяти, с другой - компания вроде бы вполне довольна этим решением, и не собирается от него отказываться. С третьей - Intel тоже не собирается отказываться от внешнего контроллера, и вполне довольна «классической схемой», проверенной годами.
Оперативная память
Разрядность шины памяти, N-канальные контроллеры памяти
По состоянию на сегодняшний день, вся память, используемая в современных десктопных x86-системах имеет шину шириной 64 бита. Это означает, что за один такт по данной шине одновременно может быть передано количество информации, кратное 8 байтам (8 байт для SDR-шин, 16 байт для DDR-шин). Особняком стоит только память типа RDRAM, применявшаяся в системах на базе процессоров Intel Pentium 4 на заре становления архитектуры NetBurst, но сейчас это направление признано тупиковым для x86-ПК (к слову - руку к этому приложила всё та же компания Intel, которая в своё время активно пропагандировала данный тип памяти). Некоторую неразбериху вносят лишь двухканальные контроллеры, обеспечивающие одновременную работу с двумя отдельными друг от друга 64-битными шинами, благодаря чему некоторые производители заявляют о некой «128-битности». Это, разумеется, чистой воды профанация. Арифметика на уровне 1-го класса в данном случае, увы, не работает: 2x64 вовсе не равно 128. Почему? Да хотя бы потому, что даже самые современные x86 CPU (см. ниже раздел FAQ «64-битные расширения классической x86 (IA32) архитектуры») не могут работать со 128-битной шиной и 128-битной адресацией. Грубо говоря: две независимые параллельно идущие дороги, шириной 2 метра каждая - могут обеспечить одновременный проезд двух автомобилей, шириной 2 метра - но никоим образом не одного, шириной 4 метра. Точно так же, N-канальный контроллер памяти может увеличить скорость работы с данными в N раз (и то больше теоретически, чем практически) - но никак не способен увеличить разрядность этих данных. Ширина шины памяти во всех современных контроллерах, применяемых в x86-системах, равна 64 битам - независимо от того, находится этот контроллер в чипсете, или в самом процессоре. Некоторые контроллеры оснащены двумя независимыми 64-битными каналами, но на разрядность шины памяти это никак не влияет - только на скорость считывания и записи информации.
Скорость чтения и записи
Скорость чтения и записи информации в память теоретически ограничивается исключительно пропускной способностью самой памяти. Так, например, двухканальный контроллер памяти стандарта DDR400 теоретически способен обеспечить скорость чтения и записи информации, равную 8 байт (ширина шины) * 2 (количество каналов) * 2 (протокол DDR, обеспечивающий передачу 2 пакетов данных за 1 такт) * 200"000"000 (фактическая частота работы шины памяти равная 200 МГц, то есть 200"000"000 тактов в секунду). Значения, получаемые в результате практических тестов, как правило, чуть ниже теоретических: сказывается «неидеальность» конструкции контроллера памяти, плюс накладки (задержки), вызванные работой подсистемы кэширования самого процессора (см. ниже раздел про процессорный кэш). Однако основной «подвох» содержится даже не в накладках, связанных с работой контроллера и подсистемы кэширования, а в том, что скорость «линейного» чтения или записи является вовсе не единственной характеристикой, влияющей на фактическую скорость работы процессора с ОЗУ. Для того чтобы понять, из каких составляющих складывается фактическая скорость работы процессора с памятью, нам необходимо кроме линейной скорости считывания или записи учитывать ещё и такую характеристику, как латентность .
Латентность
Латентность является не менее важной характеристикой с точки зрения быстродействия подсистемы памяти, чем скорость «прокачки данных», но совершенно другой, по сути. Большая скорость обмена данными хороша тогда, когда их размер относительно велик, но если нам требуется «понемногу с разных адресов» - то на первый план выходит именно латентность. Что это такое? В общем случае - время, которое требуется для того, чтобы начать считывать информацию с определённого адреса. И действительно: с момента, когда процессор посылает контроллеру памяти команду на считывание (запись), и до момента, когда эта операция осуществляется, проходит определённое количество времени. Причём оно вовсе не равно времени, которое требуется на пересылку данных. Приняв команду на чтение или запись от процессора, контроллер памяти «указывает» ей, с каким адресом он желает работать. Доступ к любому произвольно взятому адресу не может быть осуществлён мгновенно, для этого требуется определённое время. Возникает задержка: адрес указан, но память ещё не готова предоставить к нему доступ. В общем случае, эту задержку и принято называть латентностью. У разных типов памяти она разная. Так, например, память типа DDR2 имеет в среднем гораздо большие задержки, чем DDR (при одинаковой частоте передачи данных). В результате, если данные в программе расположены «хаотично» и «небольшими кусками», скорость их считывания становится намного менее важной, чем скорость доступа к «началу куска», так как задержки при переходе на очередной адрес влияют на быстродействие системы намного сильнее, чем скорость считывания или записи.
«Соревнование» между скоростью чтения (записи) и латентностью - одна из основных головных болей разработчиков современных систем: к сожалению, рост скорости чтения (записи), почти всегда приводит к увеличению латентности. Так, например, память типа SDR (PC66, PC100, PC133) обладает в среднем лучшей (меньшей) латентностью, чем DDR. В свою очередь, у DDR2 латентность ещё выше (то есть хуже), чем у DDR.
Следует понимать, что «общая» латентность подсистемы памяти зависит не только от неё самой, но и от контроллера памяти и места его расположения - все эти факторы тоже влияют на задержку. Именно поэтому компания AMD в процессе разработки архитектуры AMD64 решила «одним махом» решить проблему высокой латентности, интегрировав контроллер прямо в процессор - чтобы максимально «сократить дистанцию» между процессорным ядром и модулями ОЗУ. Затея удалась, но дорогой ценой: теперь система на базе определённого CPU архитектуры AMD64 может работать только с той памятью, на которую рассчитан его контроллер. Наверное, именно поэтому компания Intel до сих пор не решилась на такой кардинальный шаг, предпочитая действовать традиционными методами: усовершенствуя контроллер памяти в чипсете и механизм Prefetch в процессоре (про него см. ниже).
В завершение, заметим, что понятия «скорость чтения / записи» и «латентность», в общем случае, применимы к любому типу памяти - в том числе не только к классической DRAM (SDR, Rambus, DDR, DDR2), но и к кэшу (см. ниже).
Процессор: сведения общего характера
Понятие архитектуры
Архитектура как совместимость с кодом
Наверняка вы часто встречались с термином «x86», или «Intel-совместимый процессор» (или «IBM PC compatible» - но это уже по отношению к компьютеру). Иногда также встречается термин «Pentium-совместимый» (почему именно Pentium - вы поймете сами чуть позже). Что за всеми этими названиями скрывается на самом деле? На данный момент наиболее корректно с точки зрения автора выглядит следующая простая формулировка: современный x86-процессор - это процессор, способный корректно исполнять машинный код архитектуры IA32 (архитектура 32-битных процессоров Intel) . В первом приближении это код, исполняемый процессором i80386 (известным в народе как «386-й»), окончательно же основной набор команд IA32 сформировался с выходом процессора Intel Pentium Pro. Что означает «основной набор» и какие есть еще? Для начала ответим на первую часть вопроса. «Основной» в данном случае означает то, что с помощью исключительно этого набора команд, может быть написана любая программа, которая вообще может быть написана для процессора архитектуры x86 (или IA32, если вам так больше нравится).
Кроме того, у архитектуры IA32 существуют «официальные» расширения (дополнительные наборы команд) от разработчика самой архитектуры, компании Intel: MMX, SSE, SSE2 и SSE3. Также существуют «неофициальные» (не от Intel) расширенные наборы команд: EMMX, 3DNow! и Extended 3DNow! - их разработала компания AMD. Впрочем, «официальность» и «неофициальность» в данном случае понятие относительное - де-факто все сводится к тому, что некоторые расширения набора команд Intel как разработчик изначального набора признает, а некоторые - нет, разработчики же программного обеспечения используют то, что им лучше всего подходит. В отношении расширенных наборов команд существует одно простое правило хорошего тона: прежде чем их использовать, программа должна проверить, поддерживает ли их процессор. Иногда отступления от этого правила встречаются (и могут приводить к неправильному функционированию программ), но объективно это является проблемой некорректно написанного программного обеспечения, а не процессора.
Для чего предназначены дополнительные наборы команд? В первую очередь - для увеличения быстродействия при выполнении некоторых операций. Одна команда из дополнительного набора, как правило, выполняет действие, для которого понадобилась бы небольшая программа, состоящая из команд основного набора. Опять-таки, как правило, одна команда выполняется процессором быстрее, чем заменяющая ее последовательность. Однако в 99% случаев, ничего такого, чего нельзя было бы сделать с помощью основных команд, с помощью команд из дополнительного набора сделать нельзя .
Таким образом, упомянутая выше проверка программой поддержки дополнительных наборов команд процессором, должна выполнять очень простую функцию: если, например, процессор поддерживает SSE - значит, считать будем быстро и с помощью команд из набора SSE. Если нет - будем считать медленнее, с помощью команд из основного набора. Корректно написанная программа обязана действовать именно так. Впрочем, сейчас практически никто не проверяет у процессора наличие поддержки MMX, так как все CPU, вышедшие за последние 5 лет, этот набор поддерживают гарантированно. Для справки приведем табличку, на которой обобщена информация о поддержке различных расширенных наборов команд различными десктопными (предназначенными для настольных ПК) процессорами.
| Процессор | |||||||
| Intel Pentium II | |||||||
| Intel Celeron до 533 MHz | |||||||
| Intel Pentium III | |||||||
| Intel Celeron 533-1400 MHz | |||||||
| Intel Pentium 4 | |||||||
| Intel Celeron от 1700 MHz | |||||||
| Intel Celeron D | |||||||
| Intel Pentium 4 eXtreme Edition | |||||||
| Intel Pentium eXtreme Edition | |||||||
| Intel Pentium D | |||||||
| AMD K6 | |||||||
| AMD K6-2 | |||||||
| AMD K6-III | |||||||
| AMD Athlon | |||||||
| AMD Duron до 900 MHz | |||||||
| AMD Athlon XP | |||||||
| AMD Duron от 1000 MHz | |||||||
| AMD Athlon 64 / Athlon FX | |||||||
| AMD Sempron | |||||||
| AMD Athlon 64 X2 | |||||||
| VIA C3 |
* в зависимости от модификации
На данный момент всё популярное десктопное программное обеспечение (операционные системы Windows и Linux, офисные пакеты, компьютерные игры, и прочее) разрабатывается именно для x86-процессоров. Оно выполняется (за исключением «дурно воспитанных» программ) на любом x86-процессоре, независимо от того, кто его произвел. Поэтому вместо ориентированных на разработчика изначальной архитектуры терминов «Intel-совместимый» или «Pentium-совместимый», стали употреблять нейтральное название: «x86-совместимый процессор», «процессор с архитектурой x86». В данном случае под «архитектурой» понимается совместимость с определённым набором команд, то есть, можно сказать, «архитектура процессора с точки зрения программиста». Есть и другая трактовка того же термина.
Архитектура как характеристика семейства процесcоров
«Железячники» - люди, работающие в основном не с программным обеспечением, а с аппаратным, под «архитектурой» понимают несколько другое (правда, более корректно то, что они называют «архитектурой», называется «микроархитектурой», но де-факто приставку «микро» частенько опускают). Для них «архитектура CPU» - это некий набор свойств, присущий целому семейству процессоров, как правило, выпускаемому в течение многих лет (иначе говоря - «внутренняя конструкция», «организация» этих процессоров). Так, например, любой специалист по x86 CPU вам скажет, что процессор с ALU, работающими на удвоенной частоте, QDR-шиной, Trace cache, и, возможно, поддержкой технологии Hyper-Threading - это «процессор архитектуры NetBurst» (не пугайтесь незнакомых терминов - все они будут разъяснены чуть позже). А процессоры Intel Pentium Pro, Pentium II и Pentium III - это «архитектура P6». Таким образом, понятие «архитектуры» применительно к процессорам несколько двойственно: под ним может пониматься как совместимость с неким единым набором команд, так и совокупность аппаратных решений, присущих определённой достаточно широкой группе процессоров. Разумеется, такой дуализм одного из основополагающих понятий не очень удобен, однако так уж сложилось, и вряд ли в ближайшее время что-то поменяется…
64-битные расширения классической x86 (IA32) архитектуры
Не так давно оба ведущих производителя x86 CPU анонсировали две практически идентичных* технологии (впрочем, AMD предпочитает называть это архитектурой), благодаря которым классические x86 (IA32) CPU получили статус 64-битных. В случае с AMD данная технология получила наименование «AMD64» (64-битная архитектура AMD), в случае с Intel - «EM64T» (расширенная 64-битная технология работы с памятью). Также почтенные аксакалы, знакомые с историей вопроса, иногда употребляют наименование «x86-64» - как общее обозначение всех 64-битных расширений архитектуры x86, не привязанное к зарегистрированным торговым маркам какого-либо производителя. Де-факто, употребление одного из трёх, приведенных выше, наименований, зависит больше от личных предпочтений употребляющего, чем от фактических различий - ибо различия между AMD64 и EM64T умещаются на кончике очень тонкой иглы. К тому же, сама AMD ввела «фирменное» наименование «AMD64» лишь незадолго до анонса собственных процессоров на основе данной архитектуры, а до этого совершенно спокойно употребляла в собственных документах более нейтральное «x86-64». Однако так или иначе, всё сводится к одному: некоторые внутренние регистры процессоров стали вместо 32-битных 64-битными, 32-битные команды x86-кода получили свои 64-битные аналоги, кроме того, объём адресуемой памяти (включая не только физическую, но и виртуальную) многократно увеличился (за счёт того, что адрес приобрёл вместо 32-битного 64-битный формат). Количество маркетинговых спекуляций на тему «64-битности» превысило все разумные пределы, поэтому нам следует рассмотреть достоинства данного нововведения особенно пристально. Итак: что же на самом деле изменилось, а что - нет?
* - Доводы о том, что Intel, дескать, «нагло скопировала EM64T с AMD64» не выдерживают никакой критики. И вовсе не потому, что это не так - а потому, что вовсе не «нагло». Есть такое понятие: «кросс-лицензионное соглашение». Если таковое соглашение имеет место быть, это означает, что все разработки одной компании в определённой области, становятся автоматически доступными другой, равно как и разработки другой автоматически становятся доступны первой. Intel воспользовалась кросс-лицензированием для разработки EM64T, взяв за основу AMD64 (чего никто никогда не отрицал). AMD воспользовалась тем же соглашением для введения в свои процессоры поддержки наборов дополнительных инструкций SSE2 и SSE3, разработанных Intel. И ничего в этом постыдного нет: раз договорились «делиться» разработками - значит, надо делиться.
Что не изменилось? В первую очередь - быстродействие процессоров. Вопиющей глупостью будет считать, что один и тот же процессор при переходе из привычного 32-битного в 64-битный режим (а 32-битный режим все нынешние x86 CPU поддерживают в обязательном порядке) станет работать в 2 раза быстрее. Разумеется, в некоторых случаях некое ускорение от использования 64-битной целочисленной арифметики может присутствовать - но количество этих случаев сильно ограничено, и большинства современного пользовательского программного обеспечения они никак не касаются. Кстати: а почему мы употребили термин «64-битная целочисленная арифметика»? А потому, что блоки операций с плавающей точкой (см. ниже) во всех x86-процессорах уже давным-давно не 32-битные. И даже не 64-битные. Классический x87 FPU (см. ниже), окончательно ставший частью CPU ещё во времена старого доброго 32-битного Intel Pentium - уже был 80-битным . Операнды команд SSE и SSE2/3 - и вовсе 128-битные! В этом плане архитектура x86 достаточно парадоксальна: при всём притом, что формально процессоры данной архитектуры достаточно долгое время оставались 32-битными - разрядность тех блоков, где «бо льшая битность» была реально необходима - наращивалась совершенно независимо от остальных. Например, процессоры AMD Athlon XP и Intel Pentium 4 «Northwood» совмещали в себе блоки, работающие с 32-битными, 80-битными, и 128-битными операндами. 32-битными оставались лишь основной набор команд (унаследованный от первого процессора архитектуры IA32 - Intel 386) и адресация памяти (максимум 4 гигабайта, если не считать «извращений» типа Intel PAE).
Таким образом, то, что процессоры AMD и Intel стали «формально 64-битными», на практике принесло нам лишь три усовершенствования: появление команд для работы с 64-битными целыми числами, увеличение количества и/или разрядности регистров, и увеличение максимального объёма адресуемой памяти. Заметим: реальной пользы этих нововведений (особенно третьего!) никто не отрицает. Равно как никто не отрицает заслуг компании AMD в продвижении идеи «осовременивания» (за счёт введения 64-битности) x86-процессоров. Мы лишь хотим предостеречь от чрезмерных ожиданий: не стоит надеяться на то, что компьютер, покупавшийся «в ценовом классе ВАЗа», от установки 64-битного программного обеспечения станет «лихим Мерседесом». Чудес на свете не бывает…
Процессорное ядро
Различия между ядрами одной микроархитектуры
«Процессорное ядро» (как правило, для краткости его называют просто «ядро») - это конкретное воплощение [микро]архитектуры (т.е. «архитектуры в аппаратном смысле этого слова»), являющееся стандартом для целой серии процессоров. Например, NetBurst - это микроархитектура, которая лежит в основе многих сегодняшних процессоров Intel: Celeron, Pentium 4, Xeon. Микроархитектура задает общие принципы: длинный конвейер, использование определенной разновидности кэша кода первого уровня (Trace cache), прочие «глобальные» особенности. Ядро - более конкретное воплощение. Например, процессоры микроархитектуры NetBurst с шиной 400 МГц, кэшем второго уровня 256 килобайт, и без поддержки Hyper-Threading - это более-менее полное описание ядра Willamette. А вот ядро Northwood имеет кэш второго уровня уже 512 килобайт, хотя также основано на NetBurst. Ядро AMD Thunderbird основано на микроархитектуре K7, но не поддерживает набор команд SSE, а вот ядро Palomino - уже поддерживает.
Таким образом, можно сказать что «ядро» – это конкретное воплощение определенной микроархитектуры «в кремнии», обладающее (в отличие от самой микроархитектуры) определенным набором строго обусловленных характеристик. Микроархитектура - аморфна, она описывает общие принципы построения процессора. Ядро - конкретно, это микроархитектура, «обросшая» всевозможными параметрами и характеристиками. Чрезвычайно редки случаи, когда процессоры сменяли микроархитектуру, сохраняя название. И, наоборот, практически любое наименование процессора хотя бы несколько раз за время своего существования «меняло» ядро. Например, общее название серии процессоров AMD - «Athlon XP» - это одна микроархитектура (K7), но целых четыре ядра (Palomino, Thoroughbred, Barton, Thorton). Разные ядра, построенные на одной микроархитектуре, могут иметь, в том числе разное быстродействие.
Ревизии
Ревизия - одна из модификаций ядра, крайне незначительно отличающаяся от предыдущей, почему и не заслуживает звания «нового ядра». Как правило, из выпусков очередной ревизии производители процессоров не делают большого события, это происходит «в рабочем порядке». Так что даже если вы покупаете один и тот же процессор, с полностью аналогичным названием и характеристиками, но с интервалом где-то в полгода - вполне возможно, фактически он будет уже немного другой. Выпуск новой ревизии, как правило, связан с какими-то мелкими усовершенствованиями. Например, удалось чуть-чуть снизить энергопотребление, или понизить напряжение питания, или еще что-то оптимизировать, или была устранена пара мелких ошибок. С точки зрения производительности мы не помним ни одного примера, когда бы одна ревизия ядра отличалась от другой настолько существенно, чтобы об этом имело смысл говорить. Хотя чисто теоретически возможен и такой вариант - например, подвергся оптимизации один из блоков процессора, ответственный за исполнение нескольких команд. Подводя итог, можно сказать что «заморачиваться» ревизиями процессоров чаще всего не стоит: в очень редких случаях изменение ревизии вносит какие-то кардинальные изменения в процессор. Достаточно просто знать, что есть такая штука - исключительно для общего развития.
Частота работы ядра
Как правило, именно этот параметр в просторечии именуют «частотой процессора». Хотя в общем случае определение «частота работы ядра» всё же более корректно, так как совершенно не обязательно все составляющие CPU функционируют на той же частоте, что и ядро (наиболее частым примером обратного являлись старые «слотовые» x86 CPU - Intel Pentium II и Pentium III для Slot 1, AMD Athlon для Slot A - у них L2-кэш функционировал на 1/2, и даже иногда на 1/3 частоты работы ядра). Ещё одним распространённым заблуждением является уверенность в том, что частота работы ядра однозначным образом определяет производительность. На самом деле это дважды не так: во-первых, каждое конкретное процессорное ядро (в зависимости от того, как оно спроектировано, сколько содержит исполняющих блоков различных типов, и т.д. и т.п.) может исполнять различное количество команд за один такт, частота же - это всего лишь количество таких тактов в секунду. Таким образом (приведенное далее сравнение, разумеется, очень сильно упрощено и поэтому весьма условно) процессор, ядро которого исполняет 3 инструкции за такт, может иметь на треть меньшую частоту, чем процессор, исполняющий 2 инструкции за такт - и при этом обладать полностью аналогичным быстродействием.
Во-вторых, даже в рамках одного и того же ядра, увеличение частоты вовсе не всегда приводит к пропорциональному увеличению быстродействия. Здесь вам очень пригодятся знания, которые вы могли почерпнуть из раздела «Общие принципы взаимодействия процессора и ОЗУ». Дело в том, что скорость исполнения команд ядром процессора - это вовсе не единственный показатель, влияющий на скорость выполнения программы. Не менее важна скорость поступления команд и данных на CPU. Представим себе чисто теоретически такую систему: быстродействие процессора - 10"000 команд в секунду, скорость работы памяти - 1000 байт в секунду. Вопрос: даже если принять, что одна команда занимает не более одного байта, а данных у нас нет совсем, с какой скоростью будет исполняться программа в такой системе? Правильно: не более 1000 команд в секунду, и производительность CPU тут совершенно ни при чём: мы будем ограничены не ей, а скоростью поступления команд в процессор. Таким образом, следует понимать: невозможно непрерывно наращивать одну только частоту ядра, не ускоряя одновременно подсистему памяти, так как в этом случае начиная с определённого этапа, увеличение частоты CPU перестанет сказываться на увеличении быстродействия системы в целом.
Особенности образования названий процессоров
Раньше, когда небо было голубее, пиво - вкуснее, а девушки - красивее, процессоры называли просто: имя производителя + название модельного ряда + частота. Например: «AMD K6-2 450 MHz». В настоящее время уже оба основных производителя от этой традиции отошли, и вместо частоты употребляют какие-то непонятные циферки, обозначающие невесть что. Краткому объяснению того, что же на самом деле эти циферки обозначают, и посвящены следующие два раздела.
Рейтинги от AMD
Причина, по которой компания AMD «изъяла» частоту из наименования своих процессоров, и заменила её некой абстрактной цифрой - общеизвестна: после появления процессора Intel Pentium 4, который работает на очень высоких частотах, процессоры AMD рядом с ним стали «плохо выглядеть на витрине» - покупатель не верил, что CPU с частотой, например, 1500 МГц, может обогнать CPU с частотой 2000 МГц. Поэтому частоту в наименовании заменили рейтингом. Формальная («де-юре», так сказать) трактовка этого рейтинга в устах AMD в разные времена звучала немного по-разному, но ни разу не прозвучала в том виде, в каком её воспринимали пользователи: процессор AMD с неким рейтингом, должен быть как минимум не медленнее процессора Intel Pentium 4 с соответствующей данному рейтингу частотой. Между тем, ни для кого не являлось особенным секретом, что именно такая трактовка и являлась конечной целью введения рейтинга. В общем, все всё прекрасно понимали, но AMD старательно делала вид, что она тут ни при чём:). Пенять ей за это не стоит: в конкурентной борьбе применяются совсем другие правила, чем в рыцарских поединках. Тем более что результаты независимых тестов демонстрировали: в целом, рейтинги своим процессорам AMD назначает достаточно справедливые. Собственно, именно до тех пор, пока это так - вряд ли имеет смысл протестовать против использования рейтинга. Правда, остаётся открытым один вопрос: а к чему же (нас интересует, понятное дело, состояние де-факто, а не разъяснения маркетингового отдела) будет привязан рейтинг процессоров AMD чуть позже, когда вместо Pentium 4 Intel начнёт выпускать какой-нибудь другой процессор?
Processor Number от Intel
Что нужно запомнить сразу: Processor Number (далее PN) у процессоров Intel - это не рейтинг. Не рейтинг производительности, и не рейтинг чего-либо другого. Фактически, это просто «артикул», элемент строчки в складской ведомости, единственная задача которого - сделать так, чтобы строчка, обозначающая один процессор, отличалась от строчки, обозначающей другой. В рамках серии (первая цифра PN), две остальные цифры, в принципе, кое о чём могут сказать, но, учитывая наличие таблиц, в которых приведено полное соответствие между PN и реальными параметрами, мы не видим особого смысла в том, чтобы заучивать какие-то промежуточные соответствия. Мотивация, которой руководствовалась Intel, вводя PN (вместо опять-таки указания частоты CPU) - более сложная, чем у AMD. Необходимость введения PN (как её объясняет сама Intel) связана, прежде всего, с тем, что два основных конкурента по-разному подходят к вопросу об уникальности наименования CPU. Например, у AMD название «Athlon 64 3200+» может обозначать сразу четыре процессора с несколько различными техническими характеристиками (но одинаковым «рейтингом»). Intel придерживается мнения, что наименование процессора должно быть уникальным, в связи с чем ранее компании приходилось «изворачиваться», добавляя к значению частоты в наименовании различные буквы, и это приводило к путанице. По идее, PN должен был эту путаницу устранить. Трудно сказать, была ли достигнута поставленная цель: всё равно номенклатура процессоров Intel осталась достаточно сложной. С другой стороны, это неизбежно, так как ассортимент продуктов уж больно велик. Однако независимо от всего прочего, одного эффекта де-факто добиться точно удалось: теперь только разбирающиеся в вопросе специалисты могут по названию процессора быстро и точно «по памяти» сказать, что он собой представляет, и какова будет его производительность в сравнении с другими CPU. Насколько это хорошо? Сложно сказать. Мы предпочтём воздержаться от комментариев.
Измерение скорости «в мегагерцах» - как это возможно?
Никак это невозможно, потому что скорость не измеряется в мегагерцах, как не измеряется расстояние в килограммах. Однако господа маркетологи давно уже поняли, что в словесном поединке между физиком и психологом побеждает всегда последний - причём независимо от того, кто на самом деле прав. Поэтому мы и читаем про «сверхбыструю 1066 MHz FSB», мучительно пытаясь понять, как скорость может измеряться с помощью частоты. На самом деле, раз уж прижилась такая извращённая тенденция, нужно просто чётко представлять себе, что имеется в виду. А имеется в виду следующее: если мы «закрепим» ширину шины на N битах - то её пропускная способность действительно будет зависеть от того, на какой частоте данная шина функционирует, и какое количество данных она способна передавать за такт. По обычной процессорной шине с «одинарной» скоростью (такая шина была, например, у процессора Intel Pentium III) за такт передаётся 64 бита, то есть 8 байт. Соответственно, если рабочая частота шины равна 100 МГц (100"000"000 тактов в секунду) - то скорость передачи данных будет равна 8 байт * 100"000"000 герц ~= 763 мегабайта в секунду (а если считать в «десятичных мегабайтах», в которых принято считать потоки данных , то ещё красивее - 800 мегабайт в секунду). Соответственно, если на тех же 100 мегагерцах работает DDR-шина, способная передавать за один такт удвоенный объём данных - скорость вырастет ровно вдвое. Поэтому, согласно парадоксальной логике господ маркетологов, данную шину следует именовать «200-мегагерцевой». А если это ещё и QDR (Quad Data Rate) шина - то она и вовсе «400-мегагерцевая» получается, так как за один такт передаёт четыре пакета данных. Хотя реальная частота работы у всех трёх вышеописанных шин одинаковая - 100 мегагерц. Вот так «мегагерцы» и стали синонимом скорости.
Таким образом, QDR-шина (с «учетверённой» скоростью), работающая на реальной частоте 266 мегагерц, волшебным образом оказывается у нас «1066-мегагерцевой». Цифра «1066» в данном случае олицетворяет то, что её пропускная способность ровно в 4 раза больше «односкоростной» шины, работающей на той же самой частоте. Вы ещё не запутались?.. Привыкайте! Это вам не какая-нибудь теория относительности, тут всё намного сложней и запущенней… Впрочем, самое главное здесь - выучить наизусть один простой принцип: если уж мы занимаемся таким извращением, как сравнение скорости двух шин между собой «в мегагерцах» - то они обязательно должны быть одинаковой ширины. Иначе получается как в одном форуме, где человек всерьёз доказывал, что пропускная способность AGP2X («133-мегагерцевая», но 32-битная шина) - выше, чем пропускная способность FSB у Pentium III 800 (реальная частота 100 МГц, ширина 64 бита ).
Пара слов о некоторых пикантных особенностях DDR и QDR протоколов
Как уже было сказано выше, в режиме DDR по шине за один такт передаётся удвоенный объём информации, а в режиме QDR - учетверённый. Правда, в документах, ориентированных больше на прославление достижений производителей, чем на объективное освещение реалий, почему-то всегда забывают указать одно маленькое «но»: режимы удвоенной и учетверённой скорости включаются только при пакетной передаче данных . То есть, если мы запросили из памяти парочку мегабайтов с адреса X по адрес Y - то да, эти два мегабайта будут переданы с удвоенной/учетверённой скоростью. А вот сам запрос на данные посылается по шине с «одинарной» скоростью - всегда ! Соответственно, если запросов у нас много, а размер пересылаемых данных не очень велик, то количество данных, которые «путешествуют» по шине с одинарной скоростью (а запрос - это тоже данные) будет почти равно количеству тех, которые передаются со скоростью удвоенной или учетверённой. Вроде бы нам никто открыто не врал, вроде бы DDR и QDR действительно работают, но… как говорится в одном старом анекдоте: «то ли он у кого-то украл шубу, то ли у него кто-то украл шубу, но что-то там с шубой не то…» ;)
Процессор «крупноблочно»
Кэш
Общее описание и принцип действия
Во всех современных процессорах есть кэш (по-английски - cache). Кэш - это некая особенная разновидность памяти (основная особенность, кардинально отличающая кэш от ОЗУ - скорость работы), которая является своего рода «буфером» между контроллером памяти и процессором. Служит этот буфер для увеличения скорости работы с ОЗУ. Каким образом? Сейчас попытаемся объяснить. При этом мы решили отказаться от попахивающих детским садом сравнений, которые частенько встречаются в популяризаторской литературе на процессорную тематику (бассейны, соединённые трубами разного диаметра, и т.д. и т.п.). Всё-таки человек, который дочитал статью до этого места, и не заснул - наверное, способен выдержать и «переварить» чисто техническое объяснение, без бассейнов, кошечек и одуванчиков.
Итак, представим, что у нас есть много сравнительно медленной памяти (пусть это будет ОЗУ размером 10"000"000 байт) и относительно мало очень быстрой (пусть это будет кэш размером всего 1024 байта). Как нам с помощью этого несчастного килобайта увеличить скорость работы со всей памятью вообще? А вот здесь следует вспомнить, что данные в процессе работы программы, как правило, не бездумно перекидываются с места на место - они изменяются . Считали из памяти значение какой-то переменной, прибавили к нему какое-то число - записали обратно на то же место. Считали массив, отсортировали по возрастанию - опять-таки записали в память. То есть в один какой-то момент программа работает не со всей памятью целиком, а, как правило, с относительно маленьким её фрагментом. Какое решение напрашивается? Правильно: загрузить этот фрагмент в «быструю» память, обработать его там, а потом уже записать обратно в «медленную» (или просто удалить из кэша, если данные не изменялись). В общем случае, именно так и работает процессорный кэш: любая считываемая из памяти информация попадает не только в процессор, но и в кэш. И если эта же информация (тот же адрес в памяти) нужна снова, сначала процессор проверяет: а нет ли её в кэше? Если есть - информация берётся оттуда, и обращения к памяти не происходит вовсе. Аналогично с записью: информация, если её объём влезает в кэш - пишется именно туда, и только потом, когда процессор закончил операцию записи, и занялся выполнением других команд, данные, записанные в кэш, параллельно с работой процессорного ядра «потихоньку выгружаются» в ОЗУ.
Разумеется, объём данных, прочитанных и записанных за всё время работы программы - намного больше объёма кэша. Поэтому некоторые из них приходится время от времени удалять, чтобы в кэш могли поместиться новые, более актуальные. Самый простой из известных механизмов обеспечения данного процесса - отслеживание времени последнего обращения к данным, находящимся в кэше. Так, если нам необходимо поместить новые данные в кэш, а он уже «забит под завязку», контроллер, управляющий кэшем, смотрит: к какому фрагменту кэша не происходило обращения дольше всего? Именно этот фрагмент и является первым кандидатом на «вылет», а на его место записываются новые данные, с которыми нужно работать сейчас. Вот так, в общих чертах, работает механизм кэширования в процессорах. Разумеется, приведенное выше объяснение весьма примитивно, на самом деле всё ещё сложнее, но, надеемся, общее представление о том, зачем процессору нужен кэш и как он работает, вы получить смогли.
А для того чтобы было понятно, насколько важен кэш, приведем простой пример: скорость обмена данными процессора Pentium 4 со своим кэшам более чем в 10 раз (!) превосходит скорость его работы с памятью. Фактически, в полную силу современные процессоры способны работать только с кэшем: как только они сталкиваются с необходимостью прочитать данные из памяти - все их хваленые мегагерцы начинают просто «греть воздух». Опять-таки, простой пример: выполнение простейшей инструкции процессором происходит за один такт, то есть за секунду он может выполнить такое количество простых инструкций, какова его частота (на самом деле еще больше, но это оставим на потом…). А вот время ожидания данных из памяти может в худшем случае составить более 200 тактов! Что делает процессор, пока он ждет нужных данных? А ничего он не делает. Просто стоит и ждет…
Многоуровневое кэширование
Специфика конструирования современных процессорных ядер привела к тому, что систему кэширования в подавляющем большинстве CPU приходится делать многоуровневой. Кэш первого уровня (самый «близкий» к ядру) традиционно разделяется на две (как правило, равные) половины: кэш инструкций (L1I) и кэш данных (L1D). Это разделение предусматривается так называемой «гарвардской архитектурой» процессора, которая по состоянию на сегодня является самой популярной теоретической разработкой для построения современных CPU. В L1I, соответственно, аккумулируются только команды (с ним работает декодер, см. ниже), а в L1D - только данные (они впоследствии, как правило, попадают во внутренние регистры процессора). «Над L1» стоит кэш второго уровня - L2. Он, как правило, больше по объёму, и является уже «смешанным» - там располагаются и команды, и данные. L3 (кэш третьего уровня), как правило, полностью повторяет структуру L2, и в современных x86 CPU встречается редко. Чаще всего, L3 - это плод компромисса: за счёт использование более медленной и узкой шины, его можно сделать очень большим, но при этом скорость L3 всё равно остаётся более высокой, чем скорость памяти (хотя и не такой высокой, как у L2-кэша). Тем не менее, алгоритм работы с многоуровневым кэшем в общих чертах не отличается от алгоритма работы с одноуровневым, просто добавляются лишние итерации: сначала информация ищется в L1, если её там нет - в L2, потом - в L3, и уже потом, если ни на одном уровне кэша она не найдена - идёт обращение к основной памяти (ОЗУ).
Декодер
На самом деле, исполнительные блоки всех современных десктопных x86-процессоров… вовсе не работают с кодом в стандарте x86. У каждого процессора есть своя, «внутренняя» система команд, не имеющая ничего общего с теми командами (тем самым «кодом»), которые поступают извне. В общем случае, команды, исполняемые ядром - намного проще, «примитивнее», чем команды стандарта x86. Именно для того, чтобы процессор «внешне выглядел» как x86 CPU, и существует такой блок как декодер: он отвечает за преобразование «внешнего» x86-кода во «внутренние» команды, исполняемые ядром (при этом достаточно часто одна команда x86-кода преобразуется в несколько более простых «внутренних»). Декодер является очень важной частью современного процессора: от его быстродействия зависит то, насколько постоянным будет поток команд, поступающих на исполняющие блоки. Ведь они неспособны работать с кодом x86, поэтому то, будут они что-то делать, или простаивать - во многом зависит от скорости работы декодера. Достаточно необычный способ ускорить процесс декодирования команд реализовала в процессорах архитектуры NetBurst компания Intel - см. ниже про Trace cache.
Исполняющие (функциональные) устройства
Пройдя через все уровни кэша и декодер, команды наконец-то попадают на те блоки, ради которых вся эта катавасия и устраивалась: исполняющие устройства. По сути, именно исполняющие устройства и являются единственно необходимым элементом процессора. Можно обойтись без кэша - скорость снизится, но программы работать будут. Можно обойтись без декодера - исполняющие устройства станут сложнее, но работать процессор будет. В конце концов, ранние процессоры архитектуры x86 (i8086, i80186, 286, 386, 486, Am5x86) - как-то без декодера обходились. Без исполняющих устройств обойтись невозможно, ибо именно они исполняют код программы. В самом первом приближении они традиционно делятся на две больших группы: арифметико-логические устройства (ALU) и блок вычислений с плавающей точкой (FPU).
Арифметико-логические устройства
ALU традиционно отвечают за два типа операций: арифметические действия (сложение, вычитание, умножение, деление) с целыми числами, логические операции с опять-таки целыми числами (логическое «и», логическое «или», «исключающее или», и тому подобные). Что, собственно, и следует из их названия. Блоков ALU в современных процессорах, как правило, несколько. Для чего - вы поймёте позже, прочитав раздел «Суперскалярность и внеочередное исполнение команд». Понятно, что ALU может исполнить только те команды, которые предназначены для него. Распределением команд, поступающих с декодера, по различным исполняющим устройствам, занимается специальный блок, но это уже, как говорится, «слишком сложные материи», и их вряд ли имеет смысл разъяснять в материале, который посвящен лишь поверхностному ознакомлению с основными принципами работы современных x86 CPU.
Блок вычислений с плавающей запятой*
FPU занимается выполнением команд, работающих с числами с плавающей запятой, кроме того, традиционно на него «вешают всех собак» в виде всяческих дополнительных наборов команд (MMX, 3DNow!, SSE, SSE2, SSE3…) - независимо от того, работают они с числами с плавающей запятой, или с целыми. Как и в случае с ALU, отдельных блоков в FPU может быть несколько, и они способны работать параллельно.
* - согласно традиций русской математической школы, мы называем FPU «блоком вычислений с плавающей запятой », хотя буквально его название (Floating Point Unit) переводится как «…с плавающей точкой» - согласно американскому стандарту написания таких чисел.
Регистры процессора
Регистры - по сути, те же ячейки памяти, но «территориально» они расположены прямо в процессорном ядре. Разумеется, скорость работы с регистрами во много раз превосходит как скорость работы с ячейками памяти, расположенными в основном ОЗУ (тут вообще на порядки…), так и с кэшами любого уровня. Поэтому большинство команд архитектуры x86 предусматривают осуществление действий именно над содержимым регистров, а не над содержимым памяти. Однако общий объём регистров процессора, как правило, очень мал - он не сравним даже с объёмом кэшей первого уровня. Поэтому де-факто код программы (не на языке высокого уровня, а именно бинарный, «машинный») часто содержит следующую последовательность операций: загрузить в один из регистров процессора информацию из ОЗУ, загрузить в другой регистр другую информацию (тоже из ОЗУ), произвести некое действие над содержимым этих регистров, поместив результат в третий - а потом снова выгрузить результат из регистра в основную память.
Процессор в подробностях
Особенности кэшей
Частота работы кэша и его шина
Во всех современных x86 CPU все уровни кэша работают на той же частоте, что и процессорное ядро, но это вовсе не всегда было так (данный вопрос уже поднимался выше). Однако скорость работы с кэшем зависит не только от частоты, но и от ширины шины, с помощью которой он соединён с процессорным ядром. Как вы (надеемся) помните из ранее прочитанного, скорость передачи данных является, по сути, произведением частоты работы шины (количества тактов в секунду) на количество байт, которые передаются по шине за один такт. Количество передаваемых за такт байтов можно увеличивать за счёт введения DDR и QDR (Double Data Rate и Quad Data Rate) протоколов - или просто за счёт увеличения ширины шины. В случае с кэшем более популярен второй вариант - не в последнюю очередь из-за «пикантных особенностей» DDR/QDR, описанных выше. Разумеется, минимально разумной шириной шины кэша является ширина внешней шины самого процессора, то есть, по состоянию на сегодняшний день - 64 бита. Именно так, в духе здорового минимализма, и поступает компания AMD: в её процессорах ширина шины L1 L2 равна 64 битам, но при этом она двунаправленная, то есть, способна работать одновременно на передачу и приём информации. В духе «здорового гигантизма» в очередной раз поступила компания Intel: в её процессорах, начиная с Pentium III «Coppermine», шина L1 L2 имеет ширину… 256 бит! По принципу «кашу маслом не испортишь», как говорится. Правда, шина эта однонаправленная, то есть в один момент времени работает либо только на передачу, либо только на приём. Споры о том, какой из подходов лучше (двунаправленная шина, но более узкая, или однонаправленная широкая) - продолжаются до сих пор… впрочем, равно как и множество других споров относительно технических решений, применяемых двумя основными конкурентами на рынке x86 CPU.
Эксклюзивный и не эксклюзивный кэш
Концепции эксклюзивного и не эксклюзивного кэширования очень просты: в случае не эксклюзивного кэша, информация на всех уровнях кэширования может дублироваться. Таким образом, L2 может содержать в себе данные, которые уже находятся в L1I и L1D, а L3 (если он есть) может содержать в себе полную копию всего содержимого L2 (и, соответственно, L1I и L1D). Эксклюзивный кэш, в отличие от не эксклюзивного, предусматривает чёткое разграничение: если информация содержится на каком-то уровне кэша - то на всех остальных она отсутствует. Плюс эксклюзивного кэша очевиден: общий размер кэшируемой информации в данном случае равен суммарному объёму кэшей всех уровней - в отличие от не эксклюзивного кэша, где размер кэшируемой информации (в худшем случае) равен объёму самого большого уровня кэша. Минус эксклюзивного кэша менее очевиден, но он есть: необходим специальный механизм, который следит за собственно «эксклюзивностью» (так, например, при удалении информации из L1-кэша, перед этим автоматически инициируется процесс её копирования в L2).
Не эксклюзивный кэш традиционно использует компания Intel, эксклюзивный (с момента появления процессоров Athlon на ядре Thunderbird) - компания AMD. В целом, мы наблюдаем здесь классическое противостояние между объёмом и скоростью: за счёт эксклюзивности, при одинаковых объёмах L1/L2 у AMD общий размер кэшируемой информации получается больше - но за счёт неё же он работает медленней (задержки, вызванные наличием механизма обеспечения эксклюзивности). Следует, наверное, заметить, что недостатки не эксклюзивного кэша компания Intel в последнее время компенсирует просто, тупо, но весомо: наращивая его объёмы. Для топовых процессоров данной компании стал уже почти что нормой L2-кэш объёмом 2 МБ - и AMD с её 128 КБ L1С+L1D и максимум 1 МБ L2 пока «не переплюнуть» эти 2 МБ даже за счёт эксклюзивности.
Кроме того, увеличивать общий объём кэшируемой информации за счёт введения эксклюзивной архитектуры кэша имеет смысл только в том случае, когда выигрыш в объёме получается достаточно больши м. Для компании AMD это актуально т.к. у её сегодняшних CPU суммарный объём L1D+L1I равен 128 КБ. Процессорам Intel, у которых объём L1D равен максимум 32 КБ, а L1I иногда имеет совсем другую структуру (см. про Trace cache), введение эксклюзивной архитектуры дало бы намного меньше пользы.
А ещё есть такое распространённое заблуждение, что архитектура кэша у CPU компании Intel «инклюзивная». На самом деле - нет. Именно НЕ эксклюзивная. Инклюзивная архитектура предусматривает, что на «нижнем» уровне кэша не может находиться ничего, чего нет на более «верхнем». Не эксклюзивная архитектура всего лишь допускает дублирование данных на разных уровнях.
Trace cache
Концепция Trace cache, состоит в том, чтобы сохранять в кэше инструкций первого уровня (L1I) не те команды, которые считаны из памяти, а уже декодированные последовательности (см. декодер). Таким образом, если некая x86-команда исполняется повторно, и она всё ещё находится в L1I, декодеру процессора не нужно снова преобразовывать её в последовательность команд «внутреннего кода», так как L1I содержит данную последовательность в уже декодированном виде. Концепция Trace cache очень удачно вписывается в общую концепцию архитектуры Intel NetBurst, ориентированную на создание процессоров с очень высокой частотой работы ядра. Однако полезность Trace cache для [относительно] менее высокочастотных CPU до сих пор находится под вопросом, так как сложность организации Trace cache становится сопоставима с задачей конструирования обычного быстрого декодера. Поэтому, отдавая должное оригинальности идеи, мы всё же сказали бы, что универсальным решением «на все случаи жизни» Trace cache считать нельзя.
Суперскалярность и внеочередное исполнение команд
Основная черта всех современных процессоров состоит в том, что они способны запускать на исполнение не только ту команду, которую (согласно коду программы) следует исполнить в данный момент времени, но и другие, следующие после неё. Приведём простой (канонический) пример. Пусть нам следует исполнить следующую последовательность команд:
1) A = B + C
2) Z = X + Y
3) K = A + Z
Легко заметить, что команды (1) и (2) совершенно независимы друг от друга - они не пересекаются ни по исходным данным (переменные B и C в первом случае, X и Y во втором), ни по месту размещения результата (переменная A в первом случае и Z во втором). Стало быть, если на данный момент у нас есть свободные исполняющие блоки в количестве более одного, данные команды можно распределить по ним, и выполнить одновременно, а не последовательно*. Таким образом, если принять время исполнения каждой команды равным N тактов процессора, то в классическом случае исполнение всей последовательности заняло бы N*3 тактов, а в случае с параллельным исполнением - всего N*2 тактов (так как команду (3) нельзя выполнить, не дождавшись результата исполнения двух предыдущих).
* - разумеется, степень параллелизма не бесконечна: команды могут быть выполнены параллельно только в том случае, когда на данный момент времени есть в наличии соответствующее количество свободных от работы блоков (ФУ), причём именно таких, которые «понимают» рассматриваемые команды . Самый простой пример: блок, относящийся к ALU, физически неспособен исполнить инструкцию, предназначенную для FPU. Обратное также верно.
На самом деле всё ещё сложнее. Так, если у нас имеется следующая последовательность:
1) A = B + C
2) K = A + M
3) Z = X + Y
То очередь исполнения команд процессором будет изменена! Так как команды (1) и (3) независимы друг от друга (ни по исходным данным, ни по месту размещения результата), они могут быть выполнены параллельно - и будут выполнены параллельно. А вот команда (2) будет выполнена после них (третьей) - поскольку для того, чтобы результат вычислений был корректен, необходимо, чтобы перед этим была выполнена команда (1). Именно поэтому обсуждаемый в данном разделе механизм и называется «внеочередным исполнением команд» (Out-of-Order Execution, или сокращённо «OoO»): в тех случаях, когда очерёдность выполнения никак не может сказаться на результате, команды отправляются на исполнение не в той последовательности, в которой они располагаются в коде программы, а в той, которая позволяет достичь максимального быстродействия.
Теперь вам должно стать окончательно понятно, зачем современным CPU такое количество однотипных исполняющих блоков: они обеспечивают возможность параллельного выполнения нескольких команд, которые в случае с «классическим» подходом к проектированию процессора пришлось бы выполнять в той последовательности, в которой они содержатся в исходном коде, одну за другой.
Процессоры, оснащённые механизмом параллельного исполнения нескольких подряд идущих команд, принято называть «суперскалярными». Однако не все суперскалярные процессоры поддерживают внеочередное исполнение. Так, в первом примере нам достаточно «простой суперскалярности» (выполнения двух последовательных команд одновременно) - а вот во втором примере без перестановки команд местами уже не обойтись, если мы хотим получить максимальное быстродействие. Все современные x86 CPU обладают обоими качествами: являются суперскалярными, и поддерживают внеочередное исполнение команд. В то же время, были в истории x86 и «простые суперскаляры», OoO не поддерживающие. Например, классическим десктопным x86-суперскаляром без OoO был Intel Pentium .
Справедливости ради, стоит заметить, что никаких заслуг в разработке концепций суперскалярности и OoO - нет ни у Intel, ни у AMD, ни у какого-либо иного (в том числе из ныне почивших) производителя x86 CPU. Первый суперскалярный компьютер, поддерживающий OoO, был разработан Сеймуром Креем (Seymour Cray) ещё в 60-х годах XX века. Для сравнения: Intel свой первый суперскалярный процессор (Pentium) выпустила в 1993 году, первый суперскаляр с OoO (Pentium Pro) - в 1995 году; первый суперскаляр с OoO от AMD (K5) увидел свет в 1996 году. Комментарии, как говорится, излишни…
Предварительное (опережающее) декодирование
и кэширование
Предсказание ветвлений
В любой более-менее сложной программе присутствуют команды условного перехода: «Если некое условие истинно - перейти к исполнению одного участка кода, если нет - другого». С точки зрения скорости выполнения кода программы современным процессором, поддерживающим внеочередное исполнение, любая команда условного перехода - воистину бич божий. Ведь до тех пор, пока не станет известно, какой участок кода после условного перехода окажется «актуальным» - его невозможно начать декодировать и исполнять (см. внеочередное исполнение). Для того чтобы как-то примирить концепцию внеочередного исполнения с командами условного перехода, предназначается специальный блок: блок предсказания ветвлений. Как понятно из его названия, занимается он, по сути, «пророчествами»: пытается предсказать, на какой участок кода укажет команда условного перехода, ещё до того, как она будет исполнена. В соответствии с указаниями «штатного внутриядерного пророка», процессором производятся вполне реальные действия: «напророченный» участок кода загружается в кэш (если он там отсутствует), и даже начинается декодирование и выполнение его команд. Причём среди выполняемых команд также могут содержаться инструкции условного перехода, и их результаты тоже предсказываются, что порождает целую цепочку из пока не проверенных предсказаний! Разумеется, если блок предсказания ветвлений ошибся, вся проделанная в соответствии с его предсказаниями работа просто аннулируется.
На самом деле, алгоритмы, по которым работает блок предсказания ветвлений, вовсе не являются шедеврами искусственного интеллекта. Преимущественно они просты… и тупы. Ибо чаще всего команда условного перехода встречается в циклах: некий счётчик принимает значение X, и после каждого прохождения цикла значение счётчика уменьшается на единицу. Соответственно, до тех пор, пока значение счётчика больше нуля - осуществляется переход на начало цикла, а после того, как он становится равным нулю - исполнение продолжается дальше. Блок предсказания ветвлений просто анализирует результат выполнения команды условного перехода, и считает, что если N раз подряд результатом стал переход на определённый адрес - то и в N+1 случае будет осуществлён переход туда же. Однако, несмотря на весь примитивизм, данная схема работает просто замечательно: например, в случае, если счётчик принимает значение 100, а «порог срабатывания» предсказателя ветвлений (N) равен двум переходам подряд на один и тот же адрес - легко заметить, что 97 переходов из 98 будут предсказаны правильно!
Разумеется, несмотря на достаточно высокую эффективность простых алгоритмов, механизмы предсказания ветвлений в современных CPU всё равно постоянно совершенствуются и усложняются - но тут уже речь идёт о борьбе за единицы процентов: например, за то, чтобы повысить эффективность работы блока предсказания ветвлений с 95 процентов до 97, или даже с 97% до 99…
Предвыборка данных
Блок предвыборки данных (Prefetch) очень похож по принципу своего действия на блок предсказания ветвлений - с той только разницей, что в данном случае речь идёт не о коде, а о данных. Общий принцип действия такой же: если встроенная схема анализа доступа к данным в ОЗУ решает, что к некоему участку памяти, ещё не загруженному в кэш, скоро будет осуществлён доступ - она даёт команду на загрузку данного участка памяти в кэш ещё до того, как он понадобится исполняемой программе. «Умно» (результативно) работающий блок предвыборки позволяет существенно сократить время доступа к нужным данным, и, соответственно, повысить скорость исполнения программы. К слову: грамотный Prefetch очень хорошо компенсирует высокую латентность подсистемы памяти, подгружая нужные данные в кэш, и тем самым, нивелируя задержки при доступе к ним, если бы они находились не в кэше, а в основном ОЗУ.
Однако, разумеется, в случае ошибки блока предвыборки данных, неизбежны негативные последствия: загружая де-факто «ненужные» данные в кэш, Prefetch вытесняет из него другие (быть может, как раз нужные). Кроме того, за счёт «предвосхищения» операции считывания, создаётся дополнительная нагрузка на контроллер памяти (де-факто, в случае ошибки - совершенно бесполезная).
Алгоритмы Prefetch, как и алгоритмы блока предсказания ветвлений, тоже не блещут интеллектуальностью: как правило, данный блок стремится отследить, не считывается ли информация из памяти с определённым «шагом» (по адресам), и на основании этого анализа пытается предсказать, с какого адреса будут считываться данные в процессе дальнейшей работы программы. Впрочем, как и в случае с блоком предсказания ветвлений, простота алгоритма вовсе не означает низкую эффективность: в среднем, блок предвыборки данных чаще «попадает», чем ошибается (и это, как и в предыдущем случае, прежде всего связано с тем, что «массированное» чтение данных из памяти, как правило происходит в процессе исполнения различных циклов).
Заключение
Я - тот кролик, который не может начать жевать траву до тех пор, пока
не поймёт во всех деталях, как происходит процесс фотосинтеза!
(изложение личной позиции одним из близких знакомых автора)
Вполне возможно, те чувства, которые у вас возникли после прочтения данной статьи, можно описать примерно следующим образом: «Вместо того чтобы на пальцах объяснить, какой процессор лучше - взяли и загрузили мне мозги кучей специфической информации, в которой ещё разбираться и разбираться, и конца-края не видно!» Вполне нормальная реакция: поверьте, мы вас хорошо понимаем. Скажем даже больше (и пусть с головы упадёт корона!): если вы думаете, что мы сами можем ответить на этот простецкий вопрос («какой процессор лучше?») - то вы очень сильно заблуждаетесь. Не можем. Для одних задач лучше один, для других - другой, а тут ещё цена разная, доступность, симпатии конкретного пользователя к определённым маркам… Не имеет задача однозначного решения. Если бы имела - наверняка кто-то бы его нашёл, и стал бы самым знаменитым обозревателем за всю историю независимых тестовых лабораторий.
Хотелось бы подчеркнуть ещё раз: даже полностью усвоив и осмыслив всю информацию, изложенную в данном материале - вы по-прежнему не сможете предсказать, какой из двух процессоров будет быстрее в ваших задачах, глядя только на их характеристики . Во-первых - потому, что далеко не все характеристики процессоров здесь рассмотрены. Во-вторых - потому, что есть и такие параметры CPU, которые в числовом виде могут быть представлены только с очень большой «натяжкой». Так для кого же (и для чего) всё это написано? В основном - для тех самых «кроликов», которые непременно желают знать, что происходит внутри тех устройств, которыми они пользуются ежедневно. Зачем? Может, они просто лучше себя чувствуют, когда знают, что вокруг них происходит? :)
В ближайших планах на расширение FAQ:
- Раздел, посвящённый многопроцессорным системам: объяснение понятия SMP, технология Hyper-Threading, N-процессорность, N-ядерность.
- Раздел, посвящённый физическим характеристикам CPU: типы корпусов, сокеты, энергопотребление, и т.п.
Сегодня уже никто не удивится тому факту, что любимая семейная фотография, хранимая и оберегаемая от коварных неожиданностей в виде, например, воды от незадачливых соседей с верхнего этажа, забывших закрыть кран, может представлять собой какой-то непонятный набор цифр и, вместе с тем, оставаться семейной фотографией. Домашний компьютер стал столь же банальной вещью, что и «ящик» с голубым экраном. Не удивлюсь, если скоро домашний ПК будет приравниваться к бытовой электротехнике. Кстати, «двигатель прогресса», всем знакомая Intel, это нам и пророчит, продвигая идею цифрового дома.
Итак, персональный компьютер занял свою нишу во всех сферах жизни человека. Его появление и становление как неотъемлемого элемента уклада жизни уже стало историей. Когда мы говорим о ПК, то имеем в виду IBM PC-совместимые системы, и вполне справедливо. Мало кто из читателей вообще своими глазами видел не IBM PC-совместимую систему, тем более пользовался такой.
Все компьютеры IBM PC и совместимые с ними основываются на процессорах с архитектурой х86. Честно говоря, иногда мне кажется, что это не только процессорная архитектура, а архитектура всего ПК, вроде идеологии строения системы в целом. Сложно сказать, кто кого тянул за собой, то ли разработчики периферийного оборудования и конечных продуктов подстраивались под архитектуру х86, или, наоборот, они прямо или косвенно формировали пути развития х86 процессоров. История х86 — не ровная асфальтированная дорожка, а совокупность различных по «степени тяжести» и гениальности шагов разработчиков, сильно переплетающихся с экономическими факторами. Знание истории процессоров х86 вовсе не обязательно. Сравнивать процессор сегодняшней реальности с его давними предками попросту бессмысленно. Но чтобы отследить общие тенденции развития и попытаться сделать прогноз, экскурс в историческое прошлое архитектуры х86 необходим. Конечно, серьезный исторический труд может занять не один том, и претендовать на объективный и широкий охват темы бессмысленно. Поэтому вдаваться в перипетии «лайф-тайма» каждого поколения процессоров х86 не будем, а ограничимся важнейшими событиями во всей эпопее х86.
1968 год
Четверо сотрудников компании Fairchild Semiconductor: Боб Нойс, менеджер и изобретатель интегральной микросхемы в 1959 году, Гордон Мур, возглавлявший научные исследования и конструкторские разработки, Энди Гроув, специалист в области химических технологий, и Артур Рок, осуществлявший финансовую поддержку, основали фирму Intel. Это название образовано от Integral Electronic.
1969 год
Бывшим директором маркетингового отдела Fairchild Semiconductor Джерри Сандерсом и несколькими его единомышленниками была основана фирма AMD (Advanced Micro Devices), занявшаяся производством микроэлектронных устройств.
1971 год
При выполнении одного из заказов на микросхемы оперативной памяти сотрудник Intel Тед Хофф предложил создать универсальную «умную» ИМС. Разработку возглавил Федерико Феджин. В итоге родился первый микропроцессор Intel 4004.
1978 год
Весь период до этого — предыстория, хотя и неотрывная от случившихся далее событий. В этом году началась эра х86 — фирмой Intel был создан микропроцессор i8086, который имел частоты 4.77,8 и 10MHz. Смешные частоты? Да, это частоты современных калькуляторов, но с них все начиналось. Чип изготавливался по 3-мкм технологии и имел внутренний 16-битный дизайн и 16-битную шину. То есть появились 16-битная поддержка и, следовательно, 16-разрядные операционные системы и программы.
Чуть позже, в том же году, был разработан i8088, основным отличием которого являлась 8-разрядная внешняя шина данных, обеспечивавшая совместимость с 8-разрядной обвязкой и памятью, использовавшейся ранее. Также доводом в его пользу была совместимость с i8080/8085 и Z-80, относительно низкая цена. Как бы там ни было, но в качестве ЦП для своего первого ПК IBM выбрала i8088. С тех пор процессор Intel станет неотъемлемой частью персонального компьютера, а сам компьютер долго будут именовать IBM PC.
 |
1982 год
Объявлен i80286. «Двести восемьдесят шестой» стал первым процессором х86, проникшим на советское и постсоветское пространство большим количеством. Тактовые частоты 6, 8, 10 и 12 МГц, производился по 1.5-мкм техпроцессу и содержал около 130000 транзисторов. Данный чип имел полную 16-битную поддержку. Впервые с появлением i80286 появилось такое понятие, как «защищенный режим», но тогда еще разработчики программного обеспечения не использовали его возможности в полной мере. Процессор мог адресовать более 1 Мб памяти, переключившись в защищенный режим, но назад вернуться можно было после полного перезапуска, а сегментированная организация доступа к памяти требовала значительных дополнительных усилий при написании программного кода. Из этого вытек тот факт, что i80286 использовался скорее как быстрый i8086.
 |
Производительность чипа по сравнению с 8086 (а особенно по сравнению с i8088) увеличилась в несколько раз и достигала 2.6 миллионов операций в секунду. В те годы производители стали активно использовать открытую архитектуру IBM PC. Тогда же начался период клонирования процессоров архитектуры х86 от Intel сторонними производителями. То есть чип выпускался другими фирмами в виде точной копии. Intel 80286 стал основой новейшего по тем меркам ПК IBM PC/AT и его многочисленных клонов. Основными преимуществами нового процессора оказались повышенная производительность и дополнительные режимы адресации. И главное — совместимость с существующим программным обеспечением. Естественно, процессор был также лицензирован сторонними производителями…
В том же году фирма AMD заключает с Intel лицензионное соглашение и на его основе начинает производство клонов процессоров x86.
1985 год
В этом году произошло, наверное, самое значительное событие в истории процессоров с архитектурой х86 — компанией Intel был выпущен первый процессор i80386. Он стал, можно сказать, революционным: 32-разрядный многозадачный процессор с возможностью одновременного выполнения нескольких программ. В сущности, самые современные процессоры представляют собой ничто иное, как быстрые 386-е. Современное программное обеспечение использует ту же архитектуру 386, просто современные процессоры делают то же самое, только быстрее. Intel 386™ стал большим шагом вперед по сравнению с i8086 и i80286. В сущности, самые современные процессоры представляют собой ничто иное, как быстрые 386-е. Современное программное обеспечение использует ту же архитектуру 386, просто современные процессоры делают то же самое, только быстрее. Intel 386™ стал большим шагом вперед по сравнению с i8086 и i80286. Intel 386™ имел значительно улучшенную систему управления памятью по сравнению с i80286, а встроенные средства многозадачности позволили разработать операционную систему Microsoft Windows и OS/2.
 |
В отличие от i80286 Intel 386™ мог свободно переключаться из защищенного режима в реальный и обратно и имел новый режим — виртуальный 8086. В этом режиме процессор мог выполнять несколько различных программных нитей одновременно, так как каждая из них выполнялась на изолированной «виртуальной» 86-й машине. В процессоре были введены дополнительные режимы адресации памяти с переменной длиной сегмента, что значительно упростило создание приложений. Процессор производился по 1-мкм технологическому процессу. Впервые процессор Intel был представлен несколькими моделями, которые образовали семейство 386-х. Здесь и начинается знаменитая маркетинговая игра компании Intel, позднее вылившаяся в разделение одного разработанного ядра на два торговых варианта, в некотором круге пользователей и специалистов называемое: «Pentium для богатых, Celeron для бедных». Хотя что здесь плохого — и волки сыты, и овцы целы.
Были выпущены следующие модели:
386DX с частотой 16, 20, 25 и 33 МГц имел 4 ГБ адресуемой памяти;
386SX с частотой 16, 20, 25 и 33 МГц в отличие от 386DX имел 16, а не 32-битную шину данных, и соответственно 16 Мб адресуемой памяти (подобным образом в свое время процессор i8088 был «создан» из i8086 за счет уменьшения разрядности внешней шины для обеспечения совместимости с имеющимися внешними устройствами);
386SL в октябре 1990 года — мобильная версия процессора Intel 386SX с частотой 20 и 25MHz.
1989 год
Корпорация Intel выпускает свой очередной процессор — Intel 486™ DX с частотой 25, 33 и 50 МГц. Intel 486 ™ DX стал первым процессором в семействе 486 и имел значительный (более чем в 2 раза при той же частоте) прирост производительности по сравнению с семейством 386. У него появился кэш первого уровня объемом 8 Кб, интегрированный в чип, а максимальный размер L2-кэша увеличился до 512 Kb. В i486DX был интегрирован блок вычислений с плавающей точкой (FPU — Floating Point Unit), который раньше выполнялся в виде внешнего математического сопроцессора, устанавливаемого на системную плату. Кроме того, это первый процессор, ядро которого содержало пятиступенчатый конвейер. Таким образом, команда, прошедшая первую ступень конвейера, продолжая обрабатываться на второй, высвобождала первую для следующей инструкции. По своей сути, процессор Intel 486™DX представлял собой быстрый Intel 386DX™, объединенный с математическим сопроцессором и 8 кБ кэш-памяти на одном кристалле. Такая интеграция позволила увеличить скорость коммуникаций между блоками до очень высоких значений.
Фирмой Intel была развернута рекламная кампания с лозунгом «Intel: The Computer Inside». Пройдет время, и она превратится в знаменитую рекламную кампанию «Intel Inside».
 |
1991 год
Был создан собственный процессор фирмы AMD — Am386™. Этот был частично построен под действием лицензии, частично по собственной разработке и работал на максимальной частоте 40 МГц, что превышало аналогичный показатель процессора Intel.
Немного ранее произошли первые судебные разбирательства между Intel и AMD по поводу намерения AMD продавать свой клон Intel 386™. Крепко укрепившая свои позиции Intel перестала нуждаться в раздаче лицензий сторонним производителям и делиться пирогом собственного приготовления ни с кем не собиралась. В результате AMD впервые вступила на рынок х86 процессоров как конкурент. За ней последовали и другие компании. Так началось продолжающееся до сих пор великое противостояние двух гигантов (остальные конкуренты сошли с дистанции), которое дало миру много хорошего. Негласным лозунгом конкурентов Intel стала фраза: «то же, что у Intel, но за меньшую цену».
В то же время Intel выпускает i486SX, в котором для удешевления продукта отсутствует блок FPU (интегрированный сопроцессор), что, конечно же, негативно сказалось на производительности. Других отличий от i486DX не было.
 |
1992 год
С выходом процессора Intel 486DX2 впервые был использован коэффициент умножения частоты шины. До этого момента внутренняя частота ядра была равна частоте внешней шины данных (FSB), но появилась проблема ее наращивания, так как локальные шины периферии (в то время VESA VL-bus), да и сами периферийные устройства проявляли нестабильность работы при частоте, превышающей 33 МГц. Теперь при частоте шины FSB 33 МГц тактовая частота ядра составляла 66 МГц за счет умножения на 2. Такой прием надолго вошел в историю и используется поныне, только множитель в современных CPU может превышать 20. Intel 486™ DX2 надолго стал популярным процессором и продавался в огромных количествах, впрочем, как и его клоны от конкурентов (AMD, Cyrix и другие), которые теперь уже имели некоторые отличия от «интеловского оригинала».
 |
1993 год
В свет вышел первый суперскалярный процессор х86, то есть способный выполнять более одной команды за такт — Pentium (кодовое название P5). Это достигалось наличием двух независимых параллельно работающих конвейера. Первые процессоры имели частоту 60 и 66 МГц и получили 64-разрядную шину данных. Впервые кэш-память первого уровня была разделена на две части: отдельно для инструкций и данных. Но одним из самых значительных нововведений был полностью обновленный блок вычислений с плавающей точкой (FPU). Фактически до этого на платформе x86 еще не было настолько мощного FPU, и лишь через многие годы после выхода Intel Pentium конкуренты смогли достичь его уровня производительности. Также впервые в процессор был включен блок предсказания ветвлений, с тех пор активно развивающийся инженерами.
Суть заключается в следующем: в любой программе присутствует множество условных переходов, когда в зависимости от условия выполнение программы должно пойти по тому или иному пути. В конвейер можно поместить только одну из нескольких ветвей перехода, и если он оказывается заполненным кодом не той ветви, то его приходится очищать и заполнять заново несколько тактов (в зависимости от количества ступеней конвейера). Для решения этой проблемы и используются механизмы предсказания ветвлений. Процессор содержал 3,1 млн. транзисторов и изготавливался по 0.8-мкм процессу. Все эти изменения позволили поднять производительность нового процессора на недосягаемую высоту. В действительности же оптимизация кода «под процессор» первое время была редкой и требовала применения специальных компиляторов. И еще долго новейшему процессору приходилось выполнять программы, предназначенные для процессоров семейств 486 и 386.
В том же году появилось второе поколение Pentium на ядре P54, в котором были устранены все недостатки Р5. При изготовлении использовались новые технологические процессы 0.6, а позднее и 0.35-мкм. До 1996 года новым процессором были охвачены тактовые частоты от 75 до 200 МГц.
Первый Pentium сыграл важную роль в переходе на новые уровни производительности персонального компьютера, дал толчок и определил ориентиры развития на будущее. Но при большом рывке в производительности он не привнес никаких кардинальных изменений в архитектуру х86.
1994 год
Появившиеся Intel 486™DX4, AMD Am486DX4 и Cyrix 4х86 продолжили линейку 486-х и использование умножения частоты шины данных. Процессоры имели утроение частоты. Процессоры DX4 от Intel работали на 75 и 100 МГц, а Am486DX4 от AMD достиг 120 МГц. В процессорах стала широко применяться система управления энергопотребления. Других принципиальных отличий от 486DX2 не обнаружилось.
1995 год
Анонсирован Pentium Pro (ядро P6). Новая процессорная шина, три независимых конвейера, оптимизация под 32-битовый код, от 256 Kb до 1 Mb L2-кэша, интегрированного в процессор, причем работающего на частоте ядра, усовершенствованный механизм предсказания ветвлений — по количеству нововведений новый процессор чуть ли не бил рекорды, ранее установленные Intel Pentium.
 |
Процессор позиционировался на использование в серверах и имел очень высокую цену. Самое примечательное, что вычислительное ядро Pentium Pro фактически не было ядром архитектуры х86. Машинные коды x86, поступающие в CPU, внутри декодировались в RISC-подобный микрокод, и уже именно его исполняло ядро процессора. Набор CISC-команд, как набор команд процессора х86, подразумевал переменную длину команд, что определяло сложность нахождения каждой отдельной команды в потоке и, следовательно, создавало трудности в разработке программ. CISC-команды являются сложными и комплексными. RISC-команды упрощенные, короткие, требующие значительно меньшее время на выполнение команды с фиксированной длиной. Использование RISC-команд позволяет значительно увеличить распараллеливание процессорных вычислений, то есть использовать больше конвейеров и, следовательно, уменьшать время исполнения команд. Ядро P6 легло в основу трех следующих процессоров Intel — Pentium II, Celeron, Pentium III.
В этом году состоялось также знаковое событие — компания AMD купила фирму NexGen, имеющую к тому времени передовые архитектурные разработки. Слияние двух инженерных команд позже принесет миру процессоры х86 с отличной от Intel микроархитектурой и даст толчок новому витку жестокой конкуренции.
На Микропроцессорном Форуме впервые был представлен новый процессор MediaGX от Cyrix, и его отличительной особенностью являются интегрированные контроллер памяти, графический ускоритель, интерфейс шины PCI и производительность, соизмеримая с производительностью Pentium. Это была первая попытка такой плотной интеграции устройств.
1996 год
Появился новый процессор AMD К5 с суперскалярным RISC-ядром. Однако RISC-ядро с его набором команд (ROP-команд) скрыты от программного обеспечения и конечного пользователя, а команды х86 преобразуются в RISC-команды. Инженеры AMD использовали уникальное решение — команды х86 частично преобразуются еще во время помещения в кэш-память процессора. В идеале процессор K5 может выполнять до четырех команд х86 за один такт, но на практике в среднем за такт обрабатываются только 2 инструкции.
 |
Кроме того, традиционные для RISC-процессоров изменения порядка вычислений, переименование регистров и другие «приемы» позволяют увеличить производительность. Процессор К5 явился детищем объединенной команды инженеров AMD и NexGen. Максимальная тактовая частота так и не превысила 116 МГц, но производительность К5 была выше, чем у процессоров Pentium с такой же тактовой частотой. Поэтому в маркетинговых целях впервые в практике маркировки CPU был использован рейтинг производительности (Performance Rating), который явно противопоставлялся тактовой частоте равных по производительности Pentium. Но процессор все-таки не мог достойно потягаться с ним, так как Pentium уже тогда достиг частоты 166 МГц.
В том же году увидел свет Intel Pentium MMX. Главное нововведение процессора P55C — дополнительные команды MXX к набору команд, который почти не претерпевал изменений со времен создания процессоров третьего поколения. Технология MMX — это использование команд, ориентированных на работу с мультимедиаданными. Специальный набор команд SIMD (Single Instruction — Multiple Data — одна команда — множественные данные) повышает производительность при выполнении векторных, циклических команд и обработке больших массивов данных — при применении графических фильтров и различных спецэффектов.
 |
По сути это 57 новых инструкций, призванных ускорить обработку видео и звука. Остальными изменениями ядра стали уже типичные увеличение объема кэш-памяти, улучшение схем работы кэш-памяти и других блоков. Производился процессор по 0.35-мкм процессу, 4.5 млн. транзисторов. Максимальная частота 233 МГц.
Начался выпуск суперскалярных процессоров Cyrix 6х86 на ядре М1, который на самом деле являлся процессором 5-го поколения, отличительной особенностью которого были «глубокие» конвейеры и использование классических х86 команд без каких-либо дополнительных наборов инструкций.
В конце года, пока в Intel велась разработка PentiumII, снова заявила о себе AMD, выпустив процессор шестого поколения К6. В основу AMD-K6 легло ядро, разработанное инженерами компании NexGen для процессора Nx686 и существенно доработанное в AMD. Как и К5, ядро К6 оперировало не х86 инструкциями, а RISC-подобным микрокодом. Процессор поддерживал команды MMX и 100-мегагерцевую системную шину и имел увеличенный до 64 Кб объем кэш-памяти первого уровня. Вскоре стало ясно, что PentiumII окажется К6 не по зубам.
с 1997 года до наших дней…
К 1997 году уже сложились направления инженерных разработок архитектуры х86 ведущих производителей. Следующий этап в развитии процессоров x86 можно охарактеризовать как противостояние архитектур, которое продолжается и поныне. На дистанцию по крупному счету вышли: захватившая 90 % рынка Intel, упорно с ней бьющаяся AMD, многократно проигрывающая в производственных мощностях, и Cyrix, которая впоследствии будет куплена компанией VIA, а затем и вовсе, не выдержав конкуренции, канет в неизвестность. Остальные производители не смогут достойно конкурировать и будут вынуждены искать другие ниши на рынке. Намечен переход от CISC к RISC-подобным микрокомандам в меньшей степени у Intel, в большей у AMD. Причем на вход и выход процессоров х86 по-прежнему поступают CISC-команды. А почему, собственно, стали вводить в х86 процессоры с родной ей CISC-архитектурой внутреннюю RISC-архитектуру, позволяющую углублять распараллеливание выполнения команд? Да просто из CISC-архитектуры х86 еще во времена четвертого поколения было выжато все, и способов повышать производительность на уровне базисных наборов команд не осталось.
 |
Принципиально новых изменений и прорывов в развитии архитектуры с тех пор не было, хотя современные процессоры быстрее, например, «386-го» в сотни раз. Инженеры оттачивают и совершенствуют уже существующие микроархитектуры ядер, а новые представляют собой лишь переработанные старые. Все усовершенствования и попытки повысить производительность сводятся к оптимизации существующих решений, введению различных исправлений и «костылей» для хромающих FPU, системы организации конвейеров и кэшей. Избитыми, но все же действенными средствами является постоянное увеличение объема кэш-памяти и частоты шины FSB. Современные процессоры имеют до 2 Мб кэш-памяти, работающей на частоте ядра, а частоты системных шин достигают 800 МГц, и то с использованием множителя, так как реальная генерируемая частота всего 200 МГц. За последние 7 лет в процессоры х86 были введены следующие «новшества-подпорки»: кэш-память окончательно переехала на кристалл процессора и переведена на частоту ядра, введены и постоянно совершенствуются блоки предсказания ветвлений как компенсация увеличению длины (количества стадий) конвейера, механизм динамического изменения порядка исполнения инструкций, уменьшающий количество холостых тактов, механизм предвыборки данных для более рационального использования кэш-памяти. Множатся дополнительные наборы команд: SSE, SSE2, SSE3, 3DNow!, 3DNow Professional. Если MMX еще можно было с натяжкой назвать дополнительным набором инструкций х86, то все последующие наборы вряд ли, так как к командам х86 добавлять уже нечего. Смысл же появления этих наборов заключается в попытке как можно меньше использовать блок вычислений с плавающей точкой (FPU) в таком виде, в каком он есть, так как, обладая высокой производительностью, он отличается малой приспособленностью для высокоточных вычислений, капризностью внутренней архитектуры и ее непредсказуемостью, что усложняет жизнь программистам. То есть фактически ввели специализированный расчетный блок, ориентированный не на вычисления вообще, а на реальные, часто встречающиеся задачи, выполнять которые предлагается в обход классического FPU.
 |
Как-то это больше похоже на борьбу с последствиями интеграции математического сопроцессора в CPU в далеком 1989 году. Во всяком случае, если задуматься и подсчитать, то большую часть времени процессор тратит «на себя» — на всевозможные преобразования, предсказания и многое другое, а не на выполнение программного кода.
Глядя назад, видно, что не все было гладко. Введение коэффициента умножения и полученная в итоге асинхронность, а также увеличение количества стадий конвейера — все это палки о двух концах. С одной стороны, это позволило увеличить тактовые частоты процессора почти до 4 ГГц (и это еще не предел), с другой — получили узкое место в виде шины FSB и проблему с условными переходами. Но всему свое время, и тогда, видимо, это были разумные решения, так как всегда присутствует очень злой экономический фактор.
Нельзя не отметить, что по-настоящему блистательных успехов за последние годы добились в области полупроводникового производства. Уже освоен 90-нанометровый технологический процесс изготовления процессоров х86, который позволяет достигать близких к СВЧ-диапазону тактовых частот, а количество транзисторов в кристалле достигает 170 млн (Pentium 4 EE).
Мы привыкли считать, что процессор — это главное устройство в ПК и что именно он задает тон глобальной компьютеризации. А ведь победоносное шествие архитектуры х86, длящееся более четверти века, началось не конкретно с процессора, а с конечного пользовательского устройства в целом — IBM PC. Тогда еще в компании IBM не догадывались, какое блистательное будущее ждет этот ПК и, не придав проекту никакого значения, сделали его открытым для всех. Именно открытости концепции, успеху программного обеспечения и MS DOS обязан успех IBM PC. А процессор в нем мог стоять любой архитектуры, но так уж получилось, что IBM выбрала i8088 и i8086, а потом уже все закрутилось, завертелось… Но из процессора х86 в итоге не получилось эдакого универсального вычислителя на все случаи жизни или «умного» устройства, вездесущего и все способного сделать, как об этом мечтали раньше. Да и «закон» Гордона Мура (каждые 2 года количество транзисторов в кристалле процессора будет увеличиваться вдвое) стал законом только для Intel, которая поставила его на острие своей маркетинговой политики, а отказываться от данного слова ей неудобно, видимо.
 |
Сегодня можно уже твердо сказать, что архитектура х86 зашла в тупик. Вклад ее в популяризацию компьютера как устройства огромен, и с этим никто не спорит. Однако нельзя быть актуальной вечно. Молодой и сильный некогда жеребец стал старой клячей, которую продолжают запрягать в телегу. Аппетиты пользователей ненасытны, и вскоре архитектура х86 не сможет их удовлетворить. Конечно, переход связан с титаническими усилиями в связи с тем, что многомиллионный мировой парк ПК в своем почти абсолютном большинстве использует процессоры архитектуры х86, и что самое важное, использует программное обеспечение для х86 кода. Одним днем все не перевернуть, нужны годы. Но разработки 64-битных процессоров и программ набирают обороты с завидной скоростью, Intel представила Itanium2, а AMD уже почти год выпускает свои Athlon 64, которые имеют совсем не х86 архитектуру, хотя и полностью совместимы с ней и еще могут выполнять все старые программы. Таким образом, можно сказать, что AMD Athlon 64 положил начало уходу от архитектуры х86 и тем самым открыл переходный период.
Как видите, заявления о том, что процессор — самый быстро развивающийся компонент ПК, далеко не беспочвенны. Представьте себе, какими процессорами будут оснащаться компьютеры наших детей. Подумать страшно!
 |
В Одноклассники